机器学习32:Batch Normalization 学习笔记(转载)
原文地址:http://blog.csdn.net/hjimce/article/details/50866313
作者:hjimce
1.背景意义:
本篇博文主要讲解2015年深度学习领域,非常值得学习的一篇文献:《Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift》,这个算法目前已经被大量的应用,最新的文献算法很多都会引用这个算法进行网络训练,可见其强大之处非同一般。
近年来随机梯度下降成了深度学习领域训练深度网络的主流方法,尽管随机梯度下降法对于训练深度网络简单高效,但是它需要我们人为选择参数,如学习率、参数初始化、权重衰减系数、Dropout比例等。这些参数的选择对训练结果至关重要,以至于很多时间都浪费在调参上,那么学习这篇文献之后便可以不必刻意地慢慢调整参数。
BN算法(Batch Normalization)的强大之处如下:
(1) 可以选择比较大的初始学习率,使训练速度加快:
之前的算法需要缓慢地调整学习率,甚至在网络训练过半时还需要计算学习率进一步调小的合适比例,现在可以采用较大的初始学习率,并且学习率的衰减速度也很快,因为算法收敛速度很快;
使用BN算法即使选择了较小的学习率,依然收敛速度快于之前,因为它具有快速训练收敛的特性;
(2)不需要人为选择拟合中Dropout及L2正则项的参数:
采用BN算法后可以移除这两项参数,或者可以选择更小的L2正则约束参数了,因为BN具有提高网络泛化能力的特性;
(3)不需要使用使用局部响应归一化层:
局部响应归一化是Alexnet网络中使用的方法,因为BN本身就是一个归一化网络层所以不需要继续使用局部响应归一化;
(4)可以把训练数据彻底打乱。
2,BN算法解决的问题:
神经网络学习过程本质就是为了学习数据分布,一旦训练数据与测试数据的分布不同,那么网络的泛化能力也大大降低;另外一方面,一旦每批训练数据的分布各不相同(batch 梯度下降),那么网络就要在每次迭代都去学习适应不同的分布,这样将会大大降低网络的训练速度,这也正是为什么我们需要对数据都要做一个归一化预处理的原因。
对于深度网络的训练是一个复杂的过程,只要网络的前面几层发生微小的改变,那么后面几层就会被累积放大下去。一旦网络某一层的输入数据的分布发生改变,那么这一层网络就需要去适应学习这个新的数据分布,所以如果训练过程中,训练数据的分布一直在发生变化,那么将会影响网络的训练速度。
网络训练过程中更新参数,除了已执行人为归一化的输入层数据外,后面网络每一层的输入数据分布是一直在发生变化,因为在训练过程中,前面层训练参数的更新将导致后面层输入数据分布的变化。以网络第二层为例:网络的第二层输入,是由输入数据和第一层的参数共同计算得到的,而第一层的参数在整个训练过程中一直在变化,因此必然会引起后面每一层输入数据分布的改变。
网络中间层在训练过程中数据分布的改变称为:“Internal Covariate Shift”,论文中所提出的算法,就是要解决在训练过程中中间层数据分布发生改变的情况,于是就有了Batch Normalization算法的诞生。
3.初识BN算法(Batch Normalization):
(1)BN算法概述:
与激活函数层、卷积层、全连接层、池化层相同,BN(Batch Normalization)也属于网络结构中的一层。
前面提到“Internal Covariate Shift”问题,即网络除了输出层外,其它层因为低层网络在训练的时候更新参数而引起了后面层输入数据分布的变化。此时如果在每一层输入时加入预处理操作,如网络第三层输入数据X3(X3表示网络第三层的输入数据)归一化至:均值0、方差为1,然后再输入第三层计算,这样就可以解决问题了。
而事实上,论文的算法本质原理就是这样:在网络的每一层输入时插入一个归一化层,也就是先做一个归一化处理,然后再进入网络的下一层。不过论文中的归一化层更复杂,是一个可学习、有参数的网络层。
(2)预处理操作——白化:
神经网络输入数据预处理操作中最好的算法莫过于白化预处理,然而白化算法计算量很大,并且不是处处可微的,所以在深度学习中其实很少用到白化。经过白化预处理后,数据满足条件:
a.特征之间的相关性降低:相当于pca;
b.数据均值、标准差归一化:使得每一维特征均值为0,标准差为1。
当数据特征维数比较大时需要进行PCA(实现白化的第一个要求),PCA操作需要计算特征向量因此计算量非常大,于是为了简化计算作者忽略了第一个要求,仅仅使用了下面的公式进行预处理,也就是近似的白化预处理,后面也将用这个公式对某一个层网络的输入数据做归一化处理:
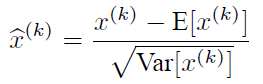
需要注意的是,训练过程中采用batch 随机梯度下降,分子中的E(xk)指的是每一批训练数据神经元xk的平均值,分母是每一批数据神经元xk激活得到的一个标准差。
3.BN算法实现:
(1)BN算法概述:
经过前面介绍,BN算法好像只是对网络中间层数据简单做一个归一化处理,然而其实实现起来并不是那么简单。
如果仅仅使用上面的归一化公式对网络某一层A的输出数据做归一化,然后送入网络下一层,这样会影响到本层网络A所学习到的特征。比如网络中间某一层学习到特征数据本身就分布在S型激活函数的两侧,如果强制把它归一化处理,标准差也限制在了1,把数据变换成分布于s函数的中间部分,这样就相当于这一层网络所学习到的特征分布被破坏了。于是论文中提出变换重构的思路,引入了可学习参数γ、β,这就是算法关键之处:
每一个神经元xk都会有一对这样的参数γ、β,这样可以恢复出原始的某一层所学到的特征:
因此引入了这个可学习重构参数γ、β使网络可以学习恢复出原始网络所要学习的特征分布,于是最终Batch Normalization网络层的前向传导过程公式就是(公式中m指的是mini-batch size):

(2)源码实现:
m = K.mean(X, axis=-1, keepdims=True)#计算均值
std = K.std(X, axis=-1, keepdims=True)#计算标准差
X_normed = (X - m) / (std + self.epsilon)#归一化
out = self.gamma * X_normed + self.beta#重构变换
(3)实战使用:
上面的算法解释了网络的训练过程,网络训练结束min-batch概念就失去了意义。测试阶段一般只输入一个测试样本获取测试结果。因此测试样本,前向传导的时候均值u、标准差σ 从何而来?
其实网络一旦训练完毕参数都是固定的,此时每批训练样本进入网络BN层计算的均值u、和标准差都是固定不变的,可以采用这些数值作为测试样本所需要的均值、标准差,于是测试阶段的u和σ 计算公式如下:
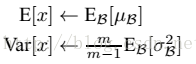
上面公式的简单理解就是:对于均值来说直接计算所有batch u值的平均值;然后对于标准偏差采用每个batch σB的无偏估计。测试阶段BN的使用公式就是:
根据论文,BN算法可以应用于一个神经网络的任何神经元上,文中主要将BN变换置于网络激活函数层的前面。在没有采用BN的时候,激活函数层是这样的:
也就是我们需要一个激活函数使函数输入的自变量x是经过BN处理后的结果。因此前向传导的计算公式是:
由于偏置参数b经过BN层后其实是没有用的,因此也会被均值归一化,当然BN层后面还有个β参数作为偏置项,所以b这个参数就不需要了。最后BN层+激活函数层转换为:
4.Batch Normalization在CNN中的使用:
通过前面的学习了解到BN层是对单个神经元执行归一化操作的运算,那么在卷积神经网络中假如某一层卷积层有6个特征图,每个特征图的大小是100*100,也就是这一层网络有6*100*100个神经元,如果采用BN算法就会产生6*100*100个参数γ、β。
因此卷积层上的BN算法的实际应用采取了类似权值共享的策略,将一整张特征图当做一个神经元进行处理。
卷积神经网络经过卷积后得到的是一系列的特征图,如果min-batch sizes为m,那么网络某一层输入数据可以表示为四维矩阵(m,f,p,q),f为特征图个数,p、q分别为特征图的宽高。在卷积神经网络中可以把每个特征图看成是一个特征处理(一个神经元),因此在使用BN算法时mini-batch size 的大小就是:m*p*q,于是对于每个特征图都只有一对可学习参数:γ、β。
这也就相当于求取所有样本所对应的一个特征图的所有神经元的平均值、方差,然后对这个特征图神经元做归一化。下面是来自于keras卷积层的BN实现一小段主要源码:
input_shape = self.input_shape
reduction_axes = list(range(len(input_shape)))
del reduction_axes[self.axis]
broadcast_shape = [1] * len(input_shape)
broadcast_shape[self.axis] = input_shape[self.axis]
if train:
m = K.mean(X, axis=reduction_axes)
brodcast_m = K.reshape(m, broadcast_shape)
std = K.mean(K.square(X - brodcast_m) + self.epsilon, axis=reduction_axes)
std = K.sqrt(std)
brodcast_std = K.reshape(std, broadcast_shape)
mean_update = self.momentum * self.running_mean + (1-self.momentum) * m
std_update = self.momentum * self.running_std + (1-self.momentum) * std
self.updates = [(self.running_mean, mean_update),
(self.running_std, std_update)]
X_normed = (X - brodcast_m) / (brodcast_std + self.epsilon)
else:
brodcast_m = K.reshape(self.running_mean, broadcast_shape)
brodcast_std = K.reshape(self.running_std, broadcast_shape)
X_normed = ((X - brodcast_m) /
(brodcast_std + self.epsilon))
out = K.reshape(self.gamma, broadcast_shape) * X_normed + K.reshape(self.beta, broadcast_shape)
5.参考文献:
(1)《Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift》
(2) Spatial Transformer Networks》
(3) https://github.com/fchollet/keras
————————————————
版权声明:本文为CSDN博主「hjimce」的原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/hjimce/article/details/50866313
