3.4-3.7小节讲述batch normalization这个方法,包括其思想,使用方法,为什么奏效即测试时作法。
3.4 思想:对神经网络每一层标准化(normalizing activations in a network)
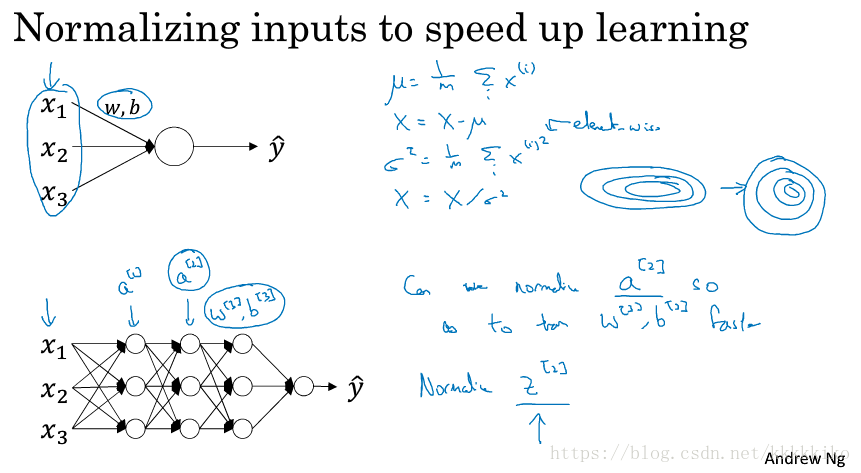
先前在1.9 标准化输入我们已经讲过标准化输入层是如何提高模型训练速度的,尤其在特征取值差别大时。而batch normalization的思想是希望对每一层节点都作标准化处理以提高模型训练速度。这里有两种思想,很多读者在不少文献中讨论过是直接对做标准化处理还是对
做标准化处理好,没有定论,老师在这里直接使用了对Z做处理,并默认在使用激活函数之前处理节点。
简单介绍完batch norm的思想,接下来就是应用batch norm,如下图所示:

通常batch norm方法是和mini-batch梯度下降结合在一起使用的。
首先是假设我们已经得到了第L层的节点值,是一个向量。然后我们对其作标准化处理,如上图所示,m在这里是mini-batch大小,分母的
是为了保证分式有意义。做完标准化处理后,
中每一个节点分布就变为均值为0,方差为1的分布。但实际中,并不一定每一个节点都服从均值为0,方差为1的分布,我们希望他们有所区别,不然也不能充分利用激活函数作用,如上图所示,假设我们使用的激活函数是sigmoid,均值为0,方差为1的分布使数据大多数集中于中间部分,相当于只利用了sigmoid的线性部分函数。
为了使不同节点服从不同分布,batch norm的处理思想是在将节点标准化处理之后,再通过改变节点的均值和方差,且
和
和W的调参过程一样。我们知道,若取
,
就可以将
还原为
。
3.5 使用方法:在神经网络中使用batch norm
将batch norm加入神经网络中,batch norm具体使用过程如下图所示:
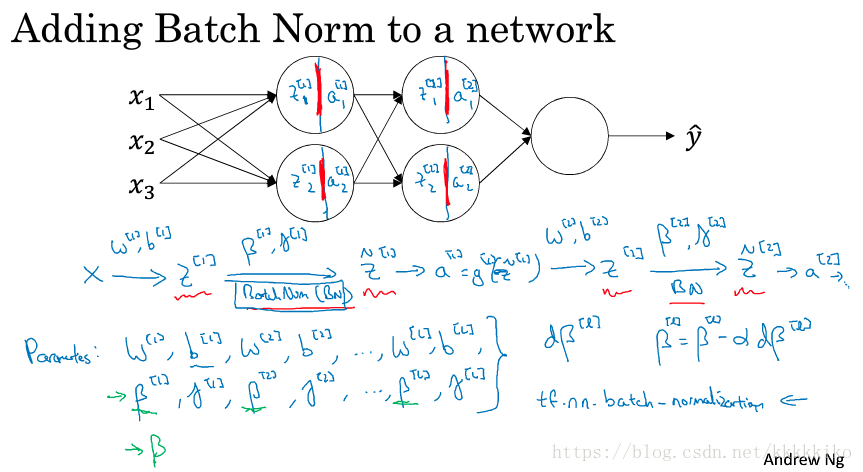
以前我们介绍过,在使用激活函数时实际上相当于将一个节点分为两部分,先计算,然后再计算
。而batch norm的实现发生在
和
之间,即现将计算出来的
标准化,然后使用
和
调整均值和方差,最后再代入激活函数计算
。
在这个过程中,参数如上图所示,注意这个不是我们之前介绍momentum和adam方法中的
,因为两个论文作者都使用了
作为这个参数,而batch norm中的
,同W一样,每一层参数都要通过梯度下降或其他优化算法进行调试的。
如果我们使用tensorflow,batch norm操作在tensorflow中就是一行代码,我们可以通过tf.nn.batch_normalization去实现batch norm操作。
前面已经提到过,batch norm一般结合mini-batch一起使用,具体使用过程如下:

如上图所示,表示第一个mini-batch,这一系列操作过程都是对mini-batch进行的,比如batch-norm求均值和方差都是在mini-batch上进行,还有参数更新。
在这个过程中我们有四种参数,分别是,除了W是矩阵,
均是
维向量,同
维度相同,因为这三个参数直接操作对象都是
。但其实
可以被剔除,为什么呢?因为
,而batch norm方法要求我们先对
作标准化处理,在作标准化过程中,有没有
对标准化过程没有影响,因为在减去均值时
被抵消掉了,且方差本来就不受常数
的影响,所以
这个参数我们就可以剔除了,因为无论有没有
,在最后计算
之前的标准化结果都是一样的。且节点分布均值可由
和
进行调试。
具体使用mini-batch进行梯度下降法过程如下图所示:

假设我们有num个mini-batches,首先通过权重初始值和计算损失函数(loss founction)值,即forward-prop过程,加入BN之后,这个过程中还包含着在每一个隐藏层的节点,使用
去代替
。然后在backprop过程中,计算
三个参数的梯度(b已剔除),然后使用优化算法更新梯度,除了梯度下降法,我们还可以使用momentum,RMSprop,Adam等优化算法。
3.6 作用机制:为什么batch norm奏效
之前我们已经说过了batch norm的思想是标准化每一个隐藏层的节点,提高模型训练速度,但不要忘记batch norm除了标准化节点,还加入和
调节节点分布。这个操作会带来什么样的效果呢?
batch norm能使深层权重(比如第10层)相比前层(比如第一层)更经受得住变化(more robust),这该怎么理解呢?往下看你就知道了。
先举个栗子介绍covariate shift,如下图所示:
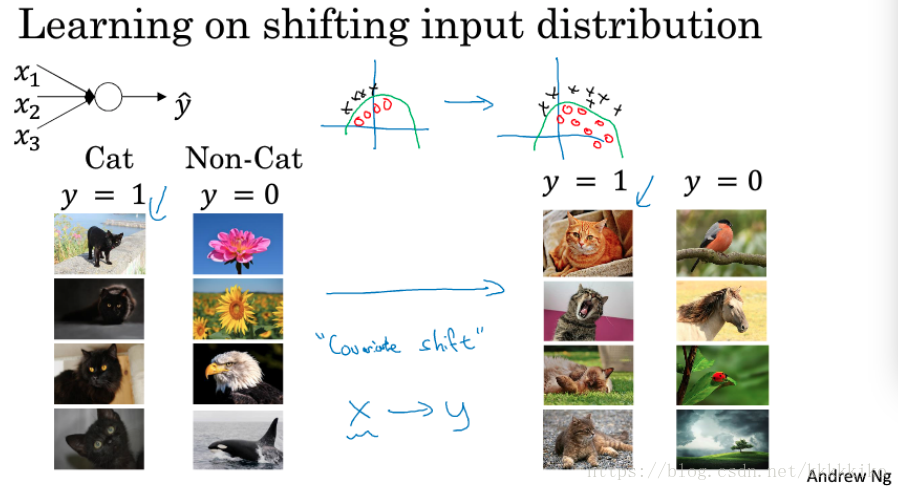
假设我们现在有一个学习任务,是判断图片是否是猫,现在我们的训练图片都是黑猫,如果换成彩色猫,这个模型还能很好判断猫的图片吗?答案恐怕是不可以,因为数据的分布发生了改变(测试集和训练集数据分布不同)。我们的问题没有发生改变,就是判断图片是否是猫,那么真实数据分布(彩色猫)可能如上图右侧所示,但黑猫仅表示真实数据中一部分数据,其分布可能如上图左侧所示。或许存在一种模型,如图中绿线所示,能够在左右这两种数据分布下,将猫与非猫正确分类,但是仅使用左边数据分布也许很难得到绿线模型,看图好像直线分类也是可以的,当然这只是打个比方,实际上我们称这类问题为‘covariate shift’。
covariate shift是指数据分布发生了改变。假设我们现在有从X到Y的映射,即使真实函数(比如上图中真实函数指判断图片是否是猫)没有发生改变,如果X的分布发生了改变,那我们可能需要重新学习算法,更不用说真实函数发生了改变,那情况就更糟糕,更需要重新学习模型了。
那么covariate shift如何应用于神经网络呢?如下图所示:
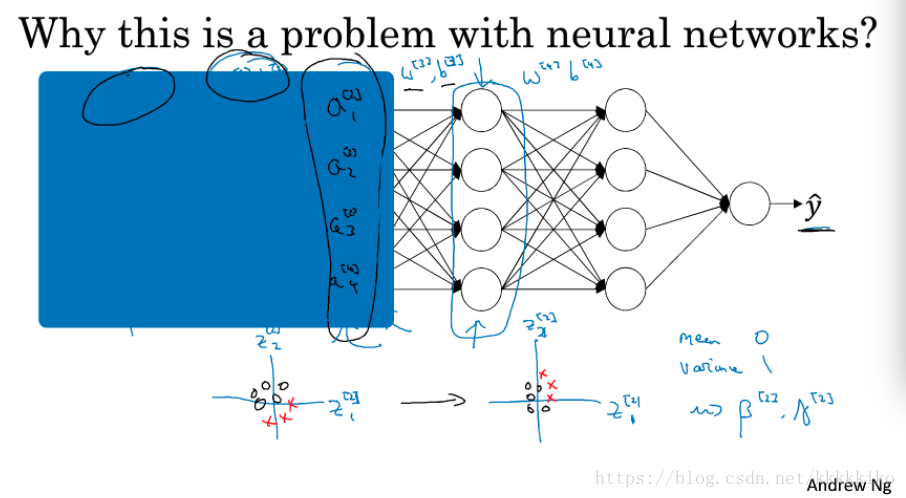
如果盖住前两层hidden layer,从第三层隐藏层看,第三层隐藏层的作用是找到到
映射,使
能够接近真实值,但是
的计算受前两层的影响,前两层参数发生改变,
的值就会发生改变。但是加入batch norm之后,通过调节
和
,节点的数据分布相对稳定,模型训练速度加快。
其实就是每一层隐藏层计算权重主要依赖于上一层数据,但是上一层数据值又依赖于前层,但是现在有一种方法(batch norm)能够使上一层数据分布保持稳定,这样即使前层保持学习,后层最依赖的前一层数据分布较稳定,那么后层适应前层的程度减少了,相当于减弱了前后层参数的依赖关系,使得每层都可以自己学习,稍稍独立于其他层,这有助于加速整个网络的学习。
重点在于,从后层视角来看,batch norm使前一层左右改变不会太多,因为被一样的方差和均值限制,这样也使后层的学习工作简单些。即使训练过程中Z的值会发生改变,但其分布是不变的,如上图中以为例。
batch norm除了通过使隐藏层节点数据分布更加稳定来加速模型训练,还有一个不太直观的效果--轻微的正则化效果,如下图所示:

配合mini-batch使用batch norm,每一个节点计算均值和标准差都是使用第t次迭代对应的mini-batch数据集,给隐层单元加了噪音,使得后部单元不过分依赖任何一个隐藏单元,类似于dropout,但是因为加的噪音不大,所以正则化效果微小,可以加上dropout共同使用。
batch大小可以改变正则化效果。增大batch大小,计算均值和标准差产生噪音更小,减少正则化效果。但通常不将batch norm作为正则化使用,而是作为标准化处理数据以加速训练,正则化是附带的效果。
3.7 测试作法:测试时的batch norm

batch norm同mini-batch一起使用,使用mini-batch去计算每一个节点的均值和方差,如上图所示,m表示mini-batch大小。但是测试的时候,我们一次只输入一个样本,无法计算和
,那怎么办呢?
有两种方法,一种是将所有训练集代入模型,计算出每个节点的均值和方差,还有就是上图中介绍的,对不同mini-batch计算得到的均值和方差作指数加权平均(快收敛时临近的一些mini-batch计算所得)。这两种方法都可以,其实只要make sense的求和
的方法都可以,这里不严格要求,都能得到不错的效果。
在得到和
之后,可以代入测试样本求出
,然后再用模型训练好的
和
作变化即可。
如果我们使用一些深度学习框架,那么可以直接使用框架中默认的求和
的方法,就能得到不错的效果。
版权声明:尊重博主原创文章,转载请注明出处https://blog.csdn.net/kkkkkiko/article/details/81510610