本博文是关于normalization的介绍博文。
目录

Normalization. It is well-known that normalizing the input data makes training faster. To normalize hidden features, initialization methods have been derived based on strong assumptions of feature distributions, which can become invalid when training evolves.
对于normalization,目前主要有以下几个方法

Batch Normalization
论文链接(https://arxiv.org/pdf/1502.03167.pdf)
首先,在进行网络训练前,一般要对数据做归一化,使其分布一致,但是在深度神经网络训练过程中,通常以送入网络的每一个batch训练,这样每个batch具有不同的分布;此外,为了解决internal covarivate shift问题(这个问题定义是随着batch normalizaiton这篇论文提出的,在训练过程中,数据分布会发生变化,对下一层网络的学习带来困难)所以batch normalization就是强行将数据拉回到均值为0,方差为1的正太分布上,这样不仅数据分布一致,而且避免发生梯度消失。
那为什么要进行归一化呢?由于ANN学习过程的本质就是为了学习数据的分布,一旦训练数据于测试数据分布不同,那么网络的泛化能力也大大下降;另一方面,一旦每批训练数据的分布各不相同(batch size),那么网络就要在每次迭代都去学习适应不同的分布,这样将会大大降低网络的训练速度。而且在训练的过程中,经过一层层的网络运算,中间层的学习到的数据分布也是发生着挺大的变化,这就要求我们必须使用一个很小的学习率和对参数很好的初始化,但是这么做会让训练过程变得慢而且复杂。在论文中,这种现象被称为Internal Covariate Shift。为了降低Internal Covariate Shift带来的影响,其实只要进行归一化就可以的。比如,把network每一层的输出都整为方差为1,均值为0的正态分布,这样看起来是可以解决问题,但network好不容易学习到的数据特征,一下子又相当于没有学习了。所以作者就进行:变换重构,引入了两个可以学习的参数γ、β:
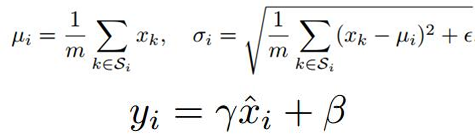
BN带来的优势

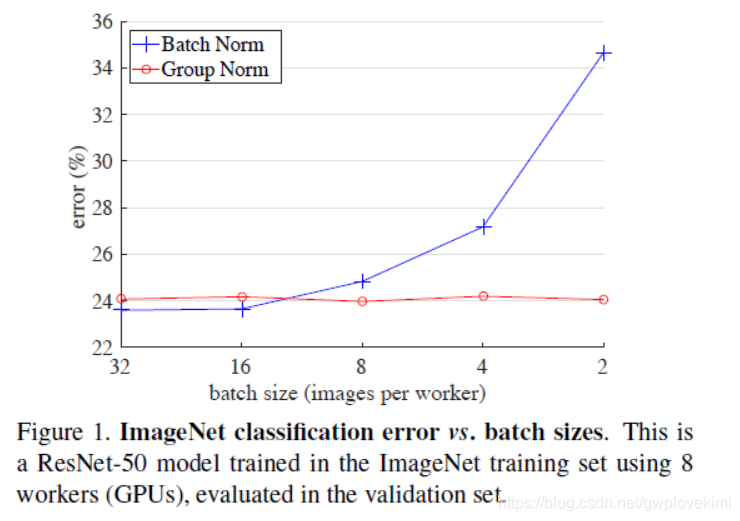
但是。BN会受到batchsize大小的影响。如果batchsize太小,算出的均值和方差就会不准确,如果太大,显存又可能不够用。
However, the BN has several disadvantages:
- It is sensitive to the size of batchsize (it is required for BN to work with a sufficiently large batch size, e.g., 32 per worker). Because the mean and variance of each calculation are on one batch, if the batchsize is too small, the calculated mean and variance are not enough to represent the whole data distribution. so BN’s error increases rapidly when the batch size becomes smaller, caused by inaccurate batch statistics estimation. A small batch leads to inaccurate estimation of the batch statistics, and reducing BN’s batch size increases the model error dramatically (as can be seen from the figure) If the batch size is too small, the calculated mean and variance will be inaccurate. If it is too large, the memory of GPU may not be enough.
- When BN is actually used, it is necessary to calculate and save statistical information such as the mean and variance of a certain layer of neural network batch. It is convenient to use BN for a fixed depth forward neural network (DNN, CNN); However, for RNN, the length of the sequence is inconsistent. In other words, the depth of the RNN is not fixed. Different time-steps need to store different statics features. There may be a special sequence that is much longer than other sequences, so when training, The calculation is very troublesome. So there is LN.
一个较好的介绍材料https://zhuanlan.zhihu.com/p/34480619
首先应该理解什么是feature scaling。此处用一个简单的图示意
第二个概念Internal Covariate Shift
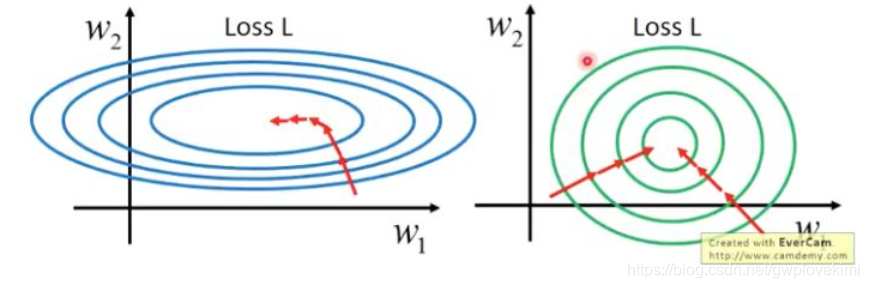
我们train神经网络的过程,就是对于其中每一层layer中的weights的学习的过程,而通过正向传播和反向传播的相互作用,每一层的layer会不断的变化,这也就导致了其input和output在不断的变化。但是,当我们固定下来一个方向的数值后,再去调整另外一个方向的数值,使得其与前面的方向匹配,那么,我们就得到了最终想要的目的。对于不加bn其实也可以解决我们的问题,就是通过非常小的learning_rate来弥补这种双向变化的空缺,但是训练的过程将会非常慢
第三个概念batch
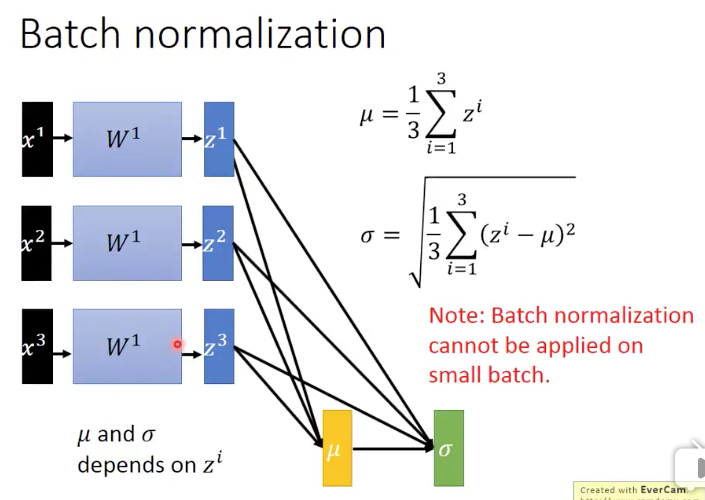
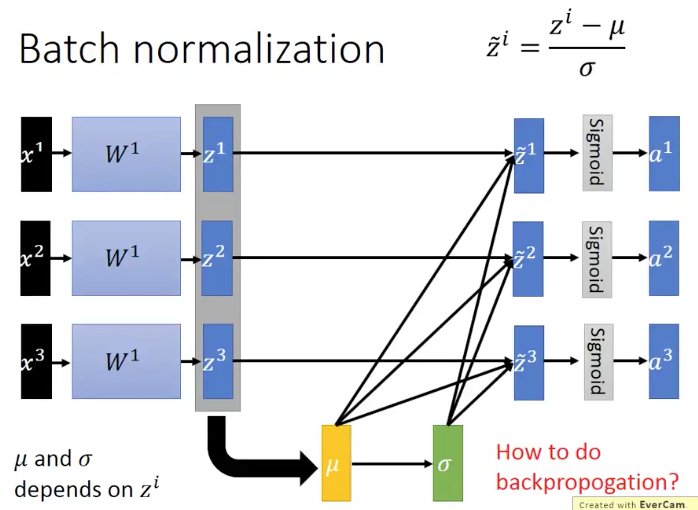
的值是来自
的,
的值是来自
和
的。注意:BN是不能够应用到小数据batch上的,因为我们知道,在计算均值和方差的时候,非常小的batch是没办法来衡量整个training set的均值和方差的。而如果我们要去计算整个training set的均值和方差,就会太浪费时间。其实我们真正想要的
和
的值就是整个training set上得到的。
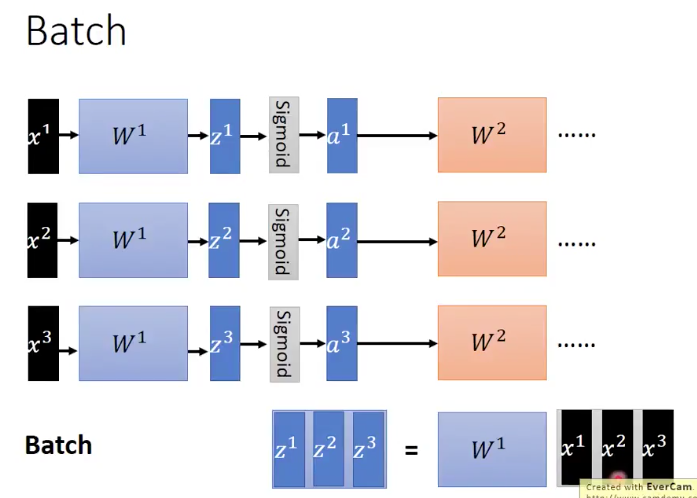
上面这张图是说,一个batch里面现在有 这三个数据,然后通过同一组parameters,我们得到了
,然后在经过activation function,得到了
,依次不断input下去。而当我们把
都同时放进一个matrix里面的时候,将
放到这个matrix的前面,我们就能得到两个matrix的乘法操作,最终得到
。比起分别计算三次矩阵乘法得到
和放到一个矩阵中,平行化计算一次来说。第二种方法明显加快了运算的速度,这也就是GPU加速batch进行训练的原理了。
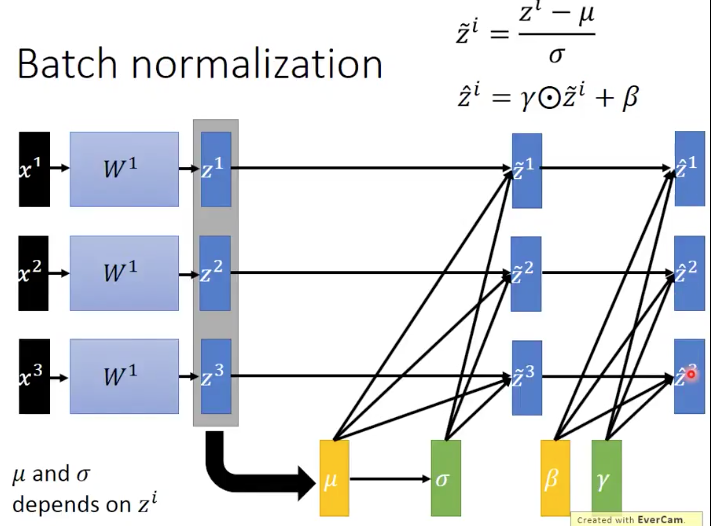
第四个概念,BN是怎么操作的呢
多引入一组独立的参数 ,这组parameter和输入的batch数据无关。是神经网络能够通过学习自己学到的。而
却是和输入的batch数据有关的。
在training阶段,NB的表现如下图所示
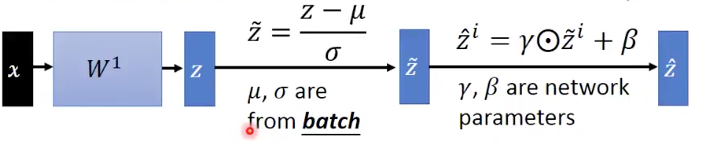
在testing阶段,输入的是一个data,并不是像train那样,输入的是一个batch的data,那么关于参数 的信息,我们没办法得到。为此可以在我们training的过程中,把每个batch所得到的
都保存下来,然后用平均的
来代替我们最终test时候的
BN的优势:
- 能够减少Interal Covariate Shift的问题,从而减少train的时间,使得对于deep网络的训练更加可行。
- 消除梯度消失和梯度爆炸的问题,特别是对sigmoid和tanh函数
- 对于参数的初始化影响更小即使对于某组parameter同时乘以k倍后,最终的结果还是会keep不变的
- 能够减少overfitting问题的发生
Layer normalization
论文链接(https://arxiv.org/pdf/1607.06450v1.pdf)
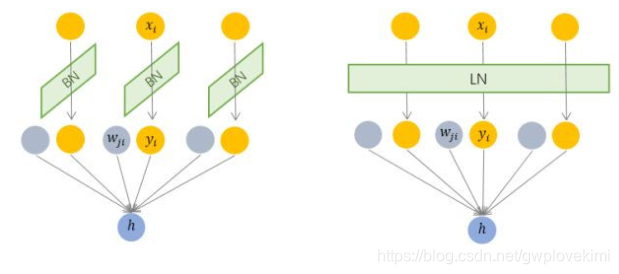
由图可以看出BN是对input tensor的每个通道进行mini-batch级别的Normalization。而LN则是对所有通道的input tensor进行Normalization(BN仅针对单个神经元,而LN考虑一层的信息,计算该层输入的平均值和方差作为规范化标准,对该层的所有输入施行同一个规范化操作)此外,由于无需保存mini-batch的均值和方差,节省了存储空间。然而,对于相似度相差较大的特征,LN会降低模型的表示能力,此种情形下BN更好(因为BN可对单个神经元训练得到)
下面给出本人做汇报时的总结ppt

batch normalization存在以下缺点:
- 对batchsize的大小比较敏感,由于每次计算均值和方差是在一个batch上,所以如果batchsize太小,则计算的均值、方差不足以代表整个数据分布;
- BN实际使用时需要计算并且保存某一层神经网络batch的均值和方差等统计信息,对于对一个固定深度的前向神经网络(DNN,CNN)使用BN,很方便;但对于RNN来说,sequence的长度是不一致的,换句话说RNN的深度不是固定的,不同的time-step需要保存不同的statics特征,可能存在一个特殊sequence比其他sequence长很多,这样training时,计算很麻烦。
与BN不同,LN是针对深度网络的某一层的所有神经元的输入按以下公式进行normalize操作

BN与LN的区别在于:
- LN中同层神经元输入拥有相同的均值和方差,不同的输入样本有不同的均值和方差;
- BN中则针对不同神经元输入计算均值和方差,同一个batch中的输入拥有相同的均值和方差。
所以,LN不依赖于batch的大小和输入sequence的深度,因此可以用于batchsize为1和RNN中对边长的输入sequence的normalize操作。
Weight Normalization
论文(《Weight Normalization: A Simple Reparameterization to Accelerate Training of Deep Neural Networks》)
Instead of operating on features, Weight Normalization (WN) proposes to normalize the filter weights.只是对滤波器的权重做归一化处理。将权重分为模和方向两个分量,并分别进行训练。不依赖于输入数据的分布(属于参数规范化。而前面的LN、BN属于特征规范化)
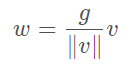
Instance normalization
论文链接(https://arxiv.org/pdf/1607.08022.pdf)
https://github.com/DmitryUlyanov/texture_nets
BN注重对每个batch进行归一化,保证数据分布一致,因为判别模型中结果取决于数据整体分布。但是图像风格转移中,生成结果主要依赖于某个图像实例,所以对整个batch归一化不适合图像风格化中,因而对HW做归一化。可以加速模型收敛,并且保持每个图像实例之间的独立。
Group normalization
论文链接(https://arxiv.org/pdf/1803.08494.pdf)
主要是针对Batch Normalization对小batchsize效果差,GN将channel方向分group,然后每个group内做归一化。算的是channel方向每个group的均值和方差,这样与batchsize无关,不受其约束。
深度网络中的数据维度一般是[N, C, H, W]或者[N, H, W, C]格式,N是batch size,H/W是feature的高/宽,C是feature的channel,压缩H/W至一个维度

作者发现很多经典的特征例如 SIFT和 HOG是分组的特征并涉及分组的归一化。GN介于LN和IN之间,其首先将channel分为许多组(group),对每一组做归一化,及先将feature的维度由[N, C, H, W]reshape为[N, G,C//G , H, W],归一化的维度为[C//G , H, W]。GN的极端情况就是LN和I N,分别对应G等于C和G等于1
BN、LN、IN、GN的区别:


下面给出参考代码
https://github.com/taokong/group_normalization
https://github.com/shaohua0116/Group-Normalization-Tensorflow
Switchable Normalization
论文链接(https://arxiv.org/pdf/1806.10779.pdf)
https://github.com/switchablenorms/Switchable-Normalization
本篇论文作者认为,
- 第一,归一化虽然提高模型泛化能力,然而归一化层的操作是人工设计的。在实际应用中,解决不同的问题原则上需要设计不同的归一化操作,并没有一个通用的归一化方法能够解决所有应用问题;
- 第二,一个深度神经网络往往包含几十个归一化层,通常这些归一化层都使用同样的归一化操作,因为手工为每一个归一化层设计操作需要进行大量的实验。
因此作者提出自适配归一化方法——Switchable Normalization(SN)来解决上述问题。与强化学习不同,SN使用可微分学习,为一个深度网络中的每一个归一化层确定合适的归一化操作。
Reference
https://blog.csdn.net/liuxiao214/article/details/81037416
https://blog.csdn.net/remanented/article/details/79980486
https://blog.csdn.net/antkillerfarm/article/details/83745601