这是Deep learning 第二门课的第三周课程的学习笔记。
1. Hyperparameter tuning
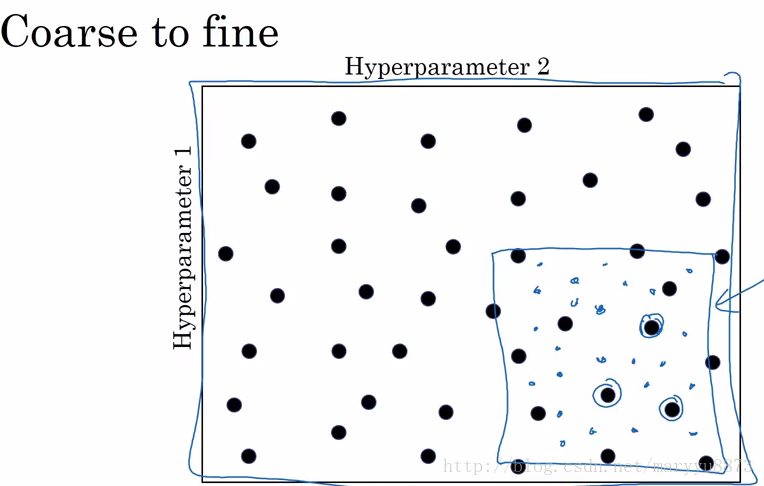
针对深度学习,不推荐使用grid search来寻找最优的参数值。因为深度学习的计算量实在太大了,grid search方法太耗资源也太慢了。
对于深度学习的调参,吴老师的观点是:
-Try random values, do not use a grid;
-Coarse to fine
2. Batch normalization
在之前的学习中,我们了解到通过对输入特征的值进行标准化后有利于加速整个训练过程。那是否可以对隐藏层的节点也进行标准化呢?这样做会对训练过程有帮助吗?
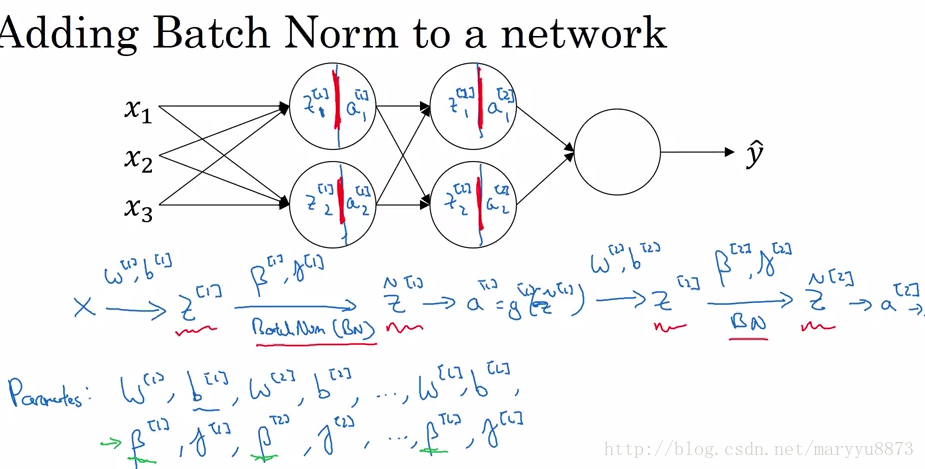
怎样进行Batch normalization?
针对每个batch的每个隐藏层的每个节点,首先计算出该节点的

Batch normalization所做的实际上是使每个节点的

Batch normalization 为什么会有效?
Batch Norm 限制了隐藏层每个节点的值的波动范围;它限制了由于前面几层节点由于参数的更新而使当前节点的输入值波动过大的问题;从而使每一层节点更加聚焦于本层的特征学习,减少受到前面层波动的影响。这样便能加速整个学习过程。
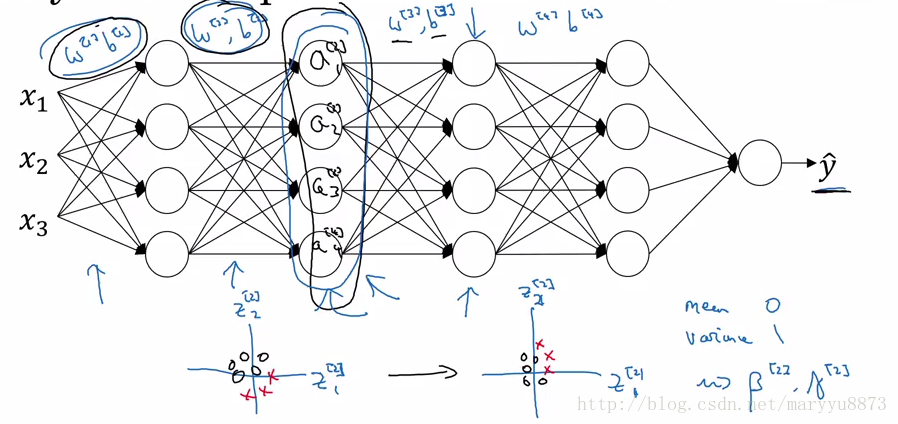
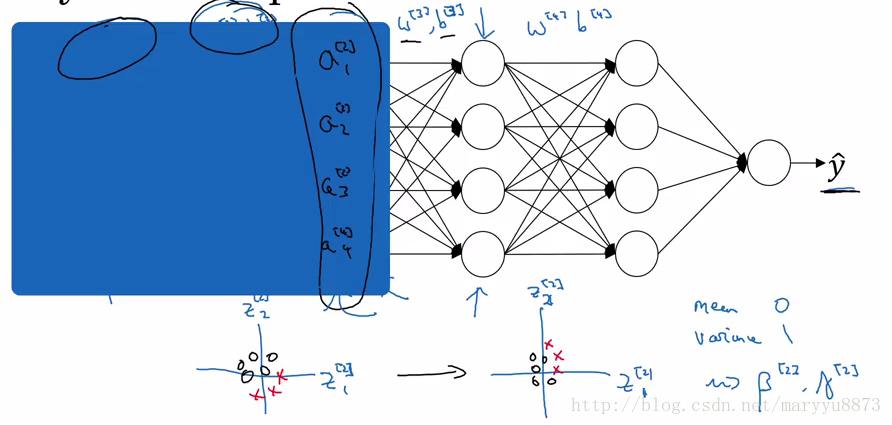
Batch Norm还有一个额外的效果,它增加了正则化过程。

由于每个隐藏层节点都受到的是当前mini-batch在该节点的有关均值和方差的缩放(每个mini-batch的缩放量不同),相当于对该节点的
怎样利用Batch Norm训练的模型用于预测?
在模型训练时,我们进行Batch Norm操作用到了当前mini-batch在相应节点的
我们可以采用指数权重平均法(Exponential weight average)计算训练集所有mini-batch在该节点的

3. Multi-class classification
当需要建立一个多目标分类器时,我们就要用到Softmax Regression,与之前不同的是输出项有多个,对应多个分类目标。输出层的激活函数由Sigmoid变为Softmax。
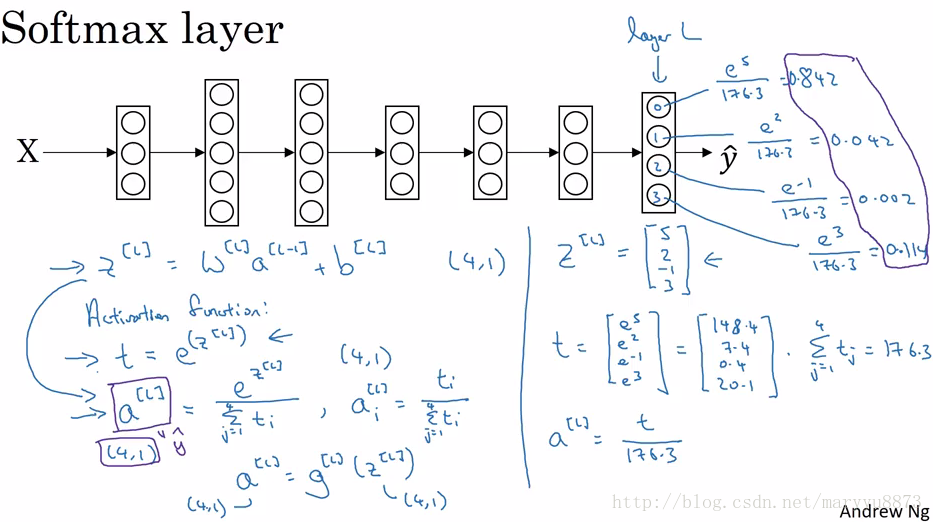
即:
首先计算
输出层所有节点的激活值总和为1,每个激活值即为相应目标的预测概率。
理解 Softmax regression
Softmax regression实际上是将Logistic regression 泛化到适用于多目标分类任务。因此当目标类别为2时,应用Softmax的结果与Logistic 一致。

Softmax regression的损失函数
对于单个样本:
可以这样理解该损失函数:该损失函数能够使实际目标对应的节点的激活值最大化。
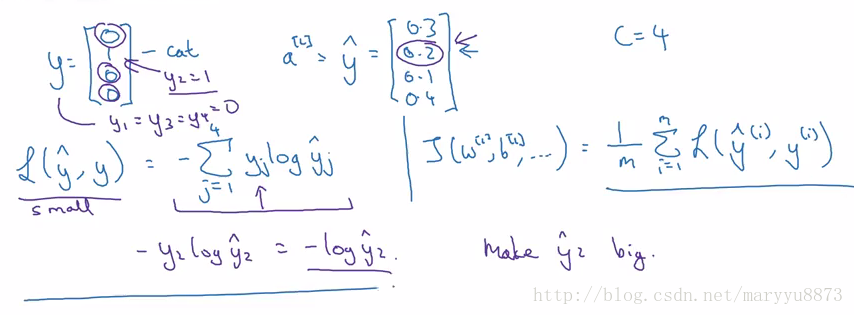
3. Tensorflow
利用Tensorflow运行程序一般都要经历如下步骤:
- 创建Tensors(变量);
- 创建Tensors之间的连接规则;
- 初始化所有建立的Tensors;
- 创建 Session;
- 运行Session。
Tensorflow里最重要的两个概念是Tensors和Operators,我们首先要建立Tensors,然后定义Operators将Tensors连接起来。
在Tensorlow里不用考虑自己去定义反向传播过程,因为整个框架会自动相应的反向传播规则。

注:如无特殊说明,以上所有图片均截选自吴恩达在Coursera开设的神经网络系列课程的讲义。