取自孙明的"数字图像处理与分析基础"
从字面意思上理解Batch Normalization就是对每一批数据进行归一化,确实如此,对于训练中某一个batch的数据{
,
, ……,
},注意这个数据可以是输入也可以是中间某一层的输出,BN的前3步如下:
到这步为止就是一个标准的数据减均值除方差的归一化流程。这样的归一化有什么用呢?来看图1定性了解一下。
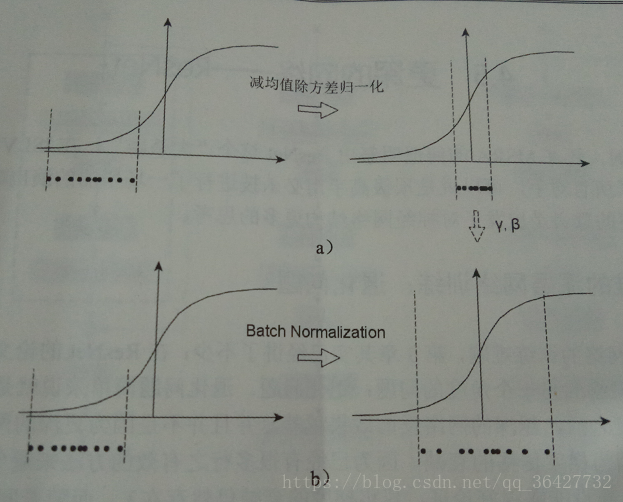
图1中左边是没有任何处理的输入数据,曲线是激活函数的曲线,比入Sigmoid。如果数据在如图1所示梯度很小的区域,那么学习率就会很慢甚至陷入长时间的停滞。减去均值再除以方差之后,数据被移到中心区域,就是图1中右边的情况。对于大多数激活函数而言,这个区域的梯度都是最大的或是有梯度的(比如ReLU),这可以看做是一种对抗梯度消失的手段。对于一层是如此,如果对于每一层数据都这么操作,那么数据的分布就总是在随输入变化敏感的区域,相当于不用考虑数据分布变来变去了,这样训练起来效率就高多了。不过到这里问题并没有结束,因为减均值除方差未必是最好的分布。比如数据本身就不对称,或者激活函数未必是对方差为1的数据有最好的效果,比如Sigmoid激活函数,在-1~1之间的梯度变化不大,那么这样非线性变换的作用有可能就不能很好体现。所以,在前面三步之后加入最后一步完成真正的Batch Normalization。
其中 和 是两个需要学习的参数,所以其实BN的本质就是利用优化变一下方差大小和均值的位置,示意图如图1b所示。因为需要统计方差和均值,而这两个值是在每个batch的数据上计算的,所以叫做Batch Normalization。当然训练模型时,数据分布的均值和方差应该尽量贴近所有数据的分布,所以在训练过程中记录大量数据的均值和方差,得到整体;样本的均值和方差的期望值,训练结束后作为最后使用的均值和方差。
注意前面写的都是对于一般情况,对于卷积神经网络有些许不同。因为卷积神经网络的特征是对应到一整张特征相应图的,所以做BN的时候也是以响应图为单位,而不是按照各个维度。比如在某一层,batch大小为 ,响应图大小为 ,则BN的数据量为 。