转自:https://blog.csdn.net/zhangyonggang886/article/details/78883028
2015年Google提出了Batch Normalization算法,Batch Normalization简称BN算法,它是为了克服神经网络层数加深导致难以训练而诞生的一个算法。根据ICS理论,当训练集的样本数据和目标样本数据分布不一致的时候,训练得到的模型无法很好的泛化。而在神经网络中,每一层的输入在经过层内操作之后必然会导致与原来对应的输入信号分布不同,并且前面层神经网络的增加会被后面的神经网络不断的累积放大。这个问题的一个解决思路就是根据训练样本与目标样本的比例对训练样本进行一个矫正,而BN算法则可以用来规范化某些层或者所有层的输入,从而固定每层输入信号的均值与方差。目前,该算法已经被广泛应用。
我们知道线性回归问题,本质上是一个多元一次函数的优化问题,多层神经网络(层数K=2),本质是一个多元K次函数优化问题。在线性回归当中,从任意一个点出发搜索,最终必然是下降到全局最小值附近的,而在多层神经网络中,从不同点出发,可能最终困在局部最小值处。在凸优化问题中,任何一个局部最小值点都是全局最小值点。然而局部最小值给神经网络结构带来的挥之不去的阴影,随着隐藏层层数的增加,非凸的目标函数越来越复杂,局部最小值点成倍增长(其实,对于很多高维非凸函数而言,局部最小值以及局部最大值事实上都远小于另为一类梯度为0的点——鞍点。鞍点(Saddle point)在微分方程中,沿着某一方向是稳定的,另一条方向是不稳定的奇点,叫做鞍点。在泛函中,既不是极大值点也不是极小值点的临界点,叫做鞍点。在矩阵中,一个数在所在行中是最大值,在所在列中是最小值,则被称为鞍点。在物理上要广泛一些,指在一个方向是极大值,另一个方向是极小值的点。)所以,从本质上来看,深度结构带来的非凸优化仍然不能解决,这限制着深度结构的发展。 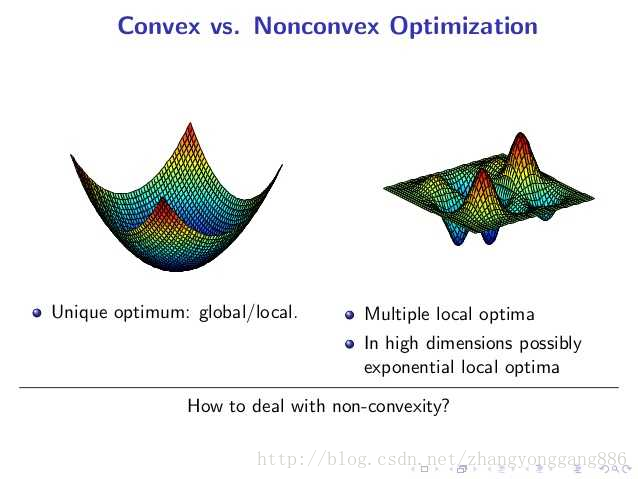
图一 凸函数与非凸函数
大多数机器学习问题都会涉及各种各样的优化问题,优化是指改变x已达到最小化或者最大化某一个函数的任务。梯度下降法(Gradient Descent)是一个最优化算法,通常也称为最速下降法,最速下降法是求解无约束优化问题最简单和最古老的方法之一。梯度下降算法由于每次更新参数,都遍历了一次所有的样本数据,这样做会具有更高的准确性,却在遍历m集合上会花费了大量的时间,当训练集合很大是,这种方法是很浪费时间的,所以引出随机梯度下降(Stochastic Gradient Descent)。随机梯度下降算法是机器学习中应用最多的优化算法。 
图二 随机梯度下降算法
尽管随机梯度下降法对于训练深度网络简单高效,但是它有一个问题就是需要人为的去选择参数,比如学习率、参数初始化、权重衰减系数、Dropout比例等。这些参数的选择对训练结果至关重要,以至于我们在训练模型时往往花费很多时间调优参数。
下面我们来说一下BN算法的优点:
a) 减少了人为选择参数。在某些情况下可以取消dropout和L2正则项参数,或者采取更小的L2正则项约束参数;
b) 减少了对学习率的要求。现在我们可以使用初始很大的学习率或者选择了较小的学习率,算法也能够快速训练收敛;
c) 可以不再使用局部响应归一化。BN本身就是归一化网络(局部响应归一化在AlexNet网络中存在)
d) 破坏原来的数据分布,一定程度上缓解过拟合(防止每批训练中某一个样本经常被挑选到,文献说这个可以提高1%的精度)。
神经网络的学习过程本质是为了学习数据的分布,如果存在训练数据与测试数据的分布不同,那么网络的泛化能力会降低。在神经网络训练中,如果参与训练的每一批训练数据分布各不相同,将会降低模型的学习速度,而数据的归一化预处理能够很好的应对这一问题。正如我们前面所说的,深度网络的训练是一个复杂的过程,如果网络的前面几层发生微小的改变,那么后面几层就会被累积放大下去。一旦网络某一层的输入数据的分布发生改变,那么这一层网络就需要去适应学习这个新的数据分布。所以如果训练过程中,训练数据的分布一直在发生变化,那么将会影响网络的训练速度。但是,深度网络的训练过程中,参数不断的发生更新,由于前面层训练参数的不断更新从而导致了后面层输入数据分布的变化。在训练深层的神经网络过程中,由于训练时每一层输入的分布在不断变化,会导致训练过程中的饱和。我们称在训练深度神经网络的过程中,网络内部节点的分布发生变换这一现象为,Internal Covariate Shift,而消除这个现象能够加速网络的训练。BN算法就是为了要解决在训练过程中,中间层数据分布发生改变的情况。
白化(whitened)——“我们已经了解了如何使用PCA降低数据维度。在一些算法中还需要一个与之相关的预处理步骤,这个预处理过程称为白化(一些文献中也叫sphering)。举例来说,假设训练数据是图像,由于图像中相邻像素之间具有很强的相关性,所以用于训练时输入是冗余的。白化的目的就是降低输入的冗余性;更正式的说,我们希望通过白化过程使得学习算法的输入具有如下性质:
a) 特征之间相关性较低;
b) (ii)所有特征具有相同的方差。”(源自知乎,更具体的解释请参考)
BN算法的主要思路:
a) 如果输入数据是白化的,网络会更快的收敛;
b) 白化目的是降低数据的冗余性和特征的相关性,例如通过线性变换使数据为0均值和单位方差;
c) BN并非直接标准化每一层那么简单,如果不考虑归一化的影响,可能会降低梯度下降的影响
d) 标准化与某个样本以及所有样本都有关系
解决上面的问题,我们希望对于任何参数值,都要满足想要的分布 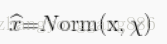
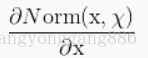
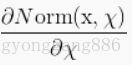
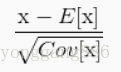
因为对于每一层的输入进行白化花费较高,并且也不是处处可微,所有BN做了两个必要的简化。第一是,我们对标量特征进行单独的进行零均值一方差归一化,来代替白化同时对层的输入和输出同时进行归一化。在BN算法的作者为了简化计算,作者忽略了特征之间的相关性降低的要求,仅使用公式进 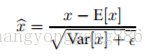
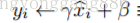
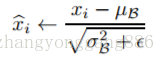
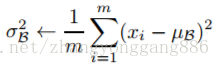
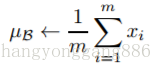
作者采用的第二个简化是在随机梯度下降中采用mini-batch的方式,这样就能够通过每个mini-batch为每个激活值计算出对应的均值和方差。通过这样的方式,归一化所需统计信息就能够完全被考虑到梯度下降中去。利用mini-batch就能计算每一维激活值的方差,而不是计算所有激活值的协方差矩阵。如果是计算协方差矩阵的话,batch的数量可能比激活值向量的大小还要小,这样就会产生奇异协方差矩阵。
算法1为BN变换,其中 ε 是一个常数(趋于0),为了保证计算方差时的稳定性。 
但需要注意的是,BN变换不仅仅与单个训练样本相关,也与mini-batch中的其他训练样本有关。由缩放和平移变换而来的 y 作为下一层的输入。虽然归一化激活值 x 被包含在BN变换中,但确实非常重要的存在。由于mini-batch中的样本都来自同一个分布,因此在忽略 ε 的情况下,x中的每一个元素都为0均值1方差分布。
BN变换是将归一化激活值引入神经网络的一种可微变换。这确保了网络可训练性,以及神经网络层能够持续学习输入数据分布。从而能够减少Internal Covariate Shift发生,同时加速网络的训练。进一步的,将学习好的仿射变换应用到归一化激活值中,能够允许BN变换比表示同样的变换,进而保存神经网络的表征能力。 
这篇文章使用两种不同方法实现了一种神经网络。每一步都输入相同的数据。网络具有完全相同的损失函数、完全相同的超参数和完全相同的优化器。然后在完全相同数量的 GPU 上进行训练。结果是其中一个版本的分类准确度比另一种低2%,并且这种性能的下降表现地很稳定。这篇文章总结了批归一化的万恶之源:
从工程的角度来分析:
a) 大体来讲,当代码出问题的时候,原因往往不外乎下面两个:很明显的错误。比如变量名输错了,或忘记调用某个函数。
b) 代码对与其交互的其他代码的行为有没有写明的依赖条件,并且的确有些条件没有满足。这些错误往往更加有害,因为一般需要花很长时间来弄清楚代码依赖什么样的条件。
这两个错误都是不可避免的。第二类错误可以依靠使用更简单的方法和重用已有代码来减少。
批归一化的方法有两个基本的性质:
c) 在训练时,单个输入 xi 的输出受制于小批次中的其他 xj 。
d) 在测试时,模型的计算路径发生了变化。因为现在它使用移动平均值而不是小批次平均值来进行归一化。
几乎没有其他优化方法有这些性质。这样的话,对于实现批归一化代码的人,很容易假设以下的前提:输入的小批次内是不相关的,或者训练时与测试时做的事情是一样的。没有人会质疑这种做法。
当然,你可以将批归一化看作万能归一化黑盒,而且还挺好用的。但是在实践中,抽象泄漏总是存在的,批归一化也不例外,而且其特性使它更容易泄漏。
建议大家在使用批归一化之前仔细考虑这样几个问题:
a) 我的训练数据集的每批样本是否平均?
b) 我的训练数据集的每批均值是否和测试时的移动平均一致?
否则的话,就有必要使用下面中的一种或几种方法来避免文中的问题:
a) 随机采样训练数据集来确保批次平均;
b) 像文中的例子一样修改模型来避免上述问题;
c) 使用层归一化,权重归一化或者余弦归一化来替代批归一化;
d) 不使用归一化方法。
在TensorFlow中BN算法主要有两个函数:tf.nn.moments以及tf.nn.batch_normalization,这两个方法中,前者用来返回均值和方差,后者用来进行批处理。
moments(
x,
axes,
shift=None,
name=None,
keep_dims=False
)
Returns:
Two `Tensor` objects: `mean` and `variance`.
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
其中参数 x 为要传递的tensor,axes是个int数组,传递要进行计算的维度,返回值是两个张量: mean and variance,我们需要利用这个函数计算出BN算法需要的前两项。
batch_normalization(
x,
mean,
variance,
offset,
scale,
variance_epsilon,
name=None
)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
其中x为输入的tensor,mean,variance由moments()求出,而offset,scale一般分别初始化为0和1,variance_epsilon一般设为比较小的数字即可。
参考文章:
深度学习中批归一化的陷阱 http://ai.51cto.com/art/201705/540230.htm;
cs231n学习笔记激活函数-BN-参数优化http://blog.csdn.net/myarrow/article/details/51848285
http://m.blog.csdn.net/panglinzhuo/article/details/77531913
Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift 论文翻译 http://blog.csdn.net/linmingan/article/details/50780761
《Batch Normalization Accelerating Deep Network Training by Reducing Internal Covariate Shift》阅读笔记与实现 http://blog.csdn.net/happynear/article/details/44238541
关于Batch Normalization(批归一化)的理解 http://m.blog.csdn.net/jyli2_11/article/details/74606919
Batch Normalization 学习笔记 http://blog.csdn.net/hjimce/article/details/50866313
Tensorflow: 批标准化(Batch Normalization) http://blog.csdn.net/fontthrone/article/details/76652772