文章目录
Classification and Representation
Classification
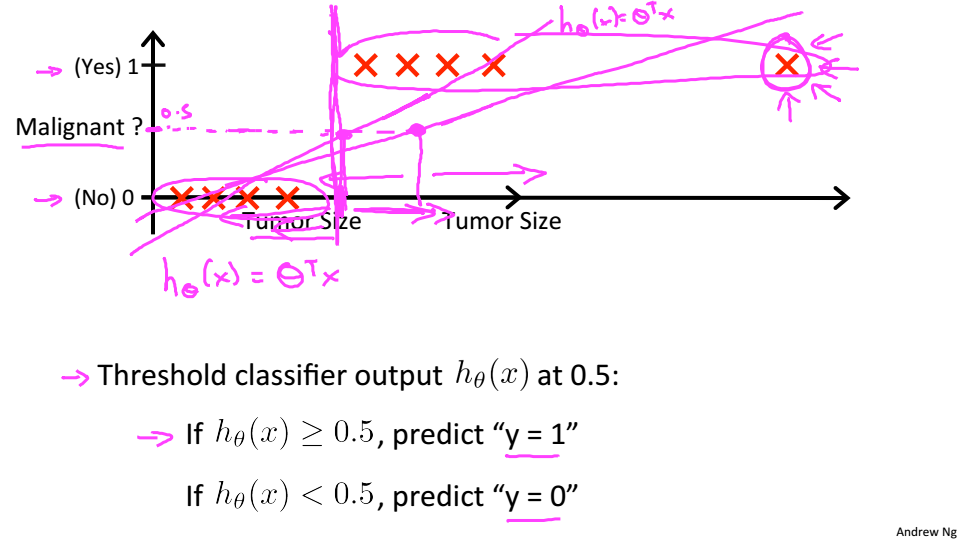
为了尝试分类,一种方法是使用线性回归,并将所有大于0.5的预测映射为1,而所有的预测都小于0.5映射为0。然而,这种方法并不适用,因为分类实际上并不是一个线性函数。
下面是个肿瘤的例子,y=1就是恶性,y=0就是良性,当使用一条直线去拟合时,可以尝试将输出阈值设为0.5,大于0.5就预测y=1,小于0.5就预测y=0,但当点在右边很远的位置y就会大于1,所以就要构造0<
<1

Hypothesis Representation
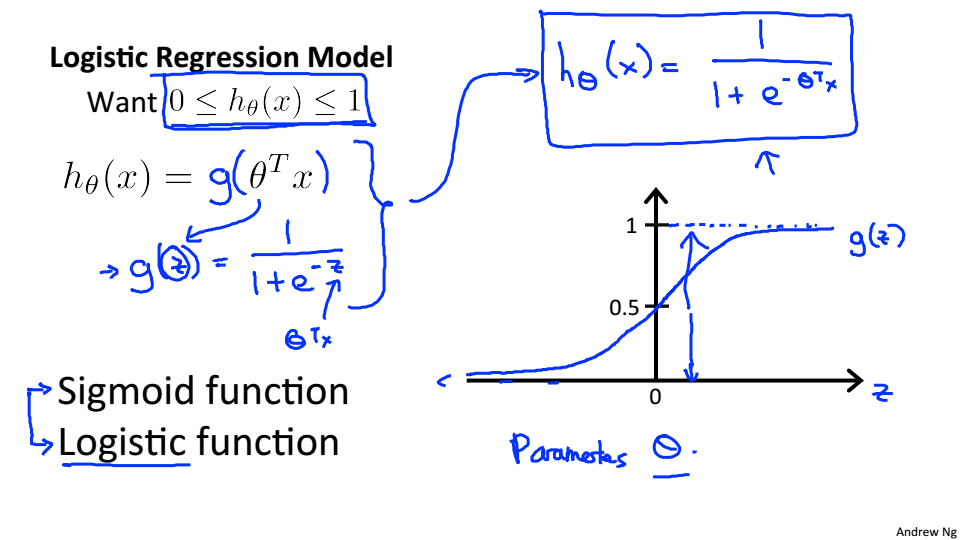
(x)的输出表示y=1的概率,可以用以下公式表示
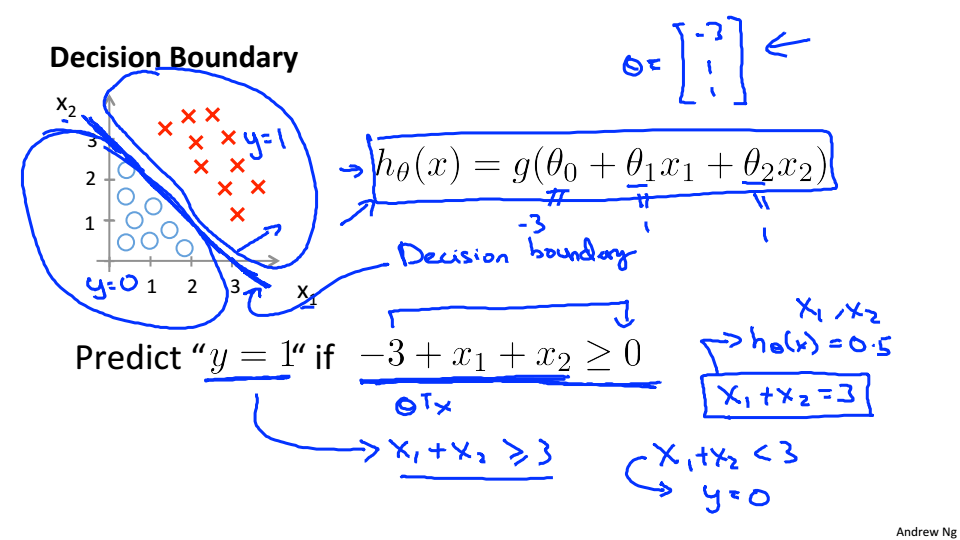
Decision Boundary
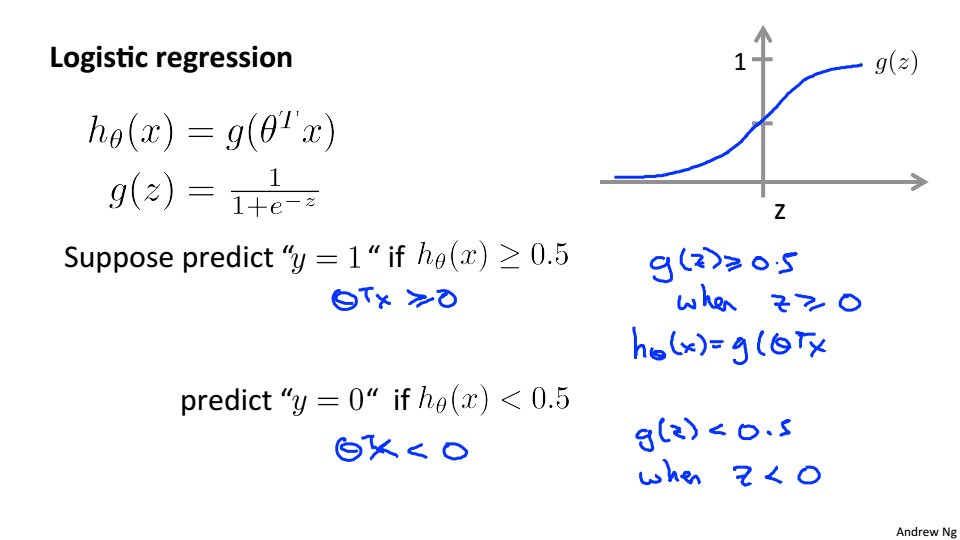
假设当
(x)>=0.5则y=1这时 z>=0
>=0
当
(x)<0.5则y=1这时 z<0
<0
决策边界是分隔y=0和y=1的区域的线。它是由我们的假设函数创建的。在下面的例子中就是
这条线,将平面分成两个部分,在这条线的上面
,在这条线的下面

Logistic Regression Model
Cost Function
因为
是非线性的,所以代价函数就会呈现非凸性,这时使用梯度下降,就无法保证收敛到全局最小值
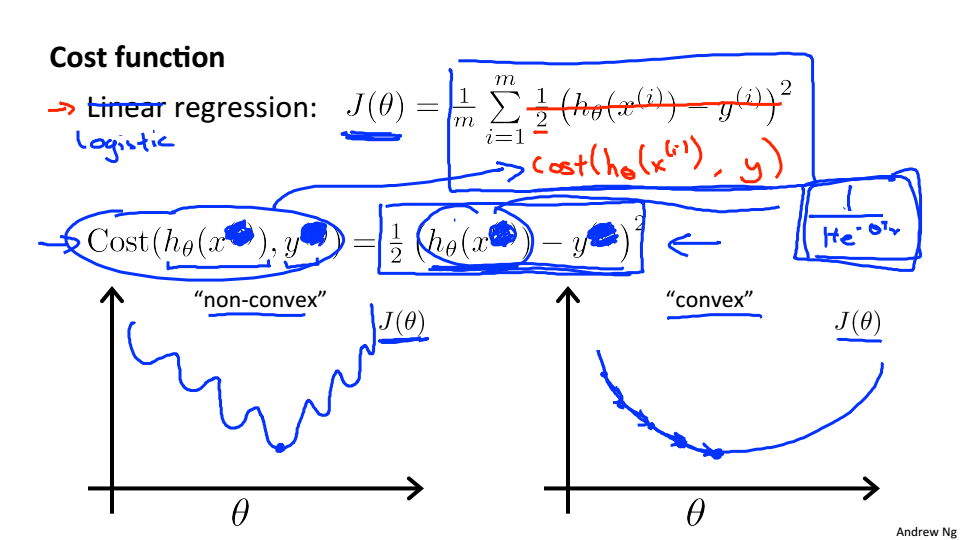
逻辑回归的代价函数定义如下:

如果我们的正确答案是0,那么如果我们的假设函数也输出0,那么代价函数就是0。如果我们的假设趋近于1,那么代价函数将趋近于无穷。
如果我们的正确答案是1,那么如果我们的假设函数输出1,那么代价将是0。如果我们的假设趋近于0,那么代价函数将趋近于无穷。
Simplified Cosf Function and Gradient Descent
上述代价函数可以简化为以下形式

梯度下降:


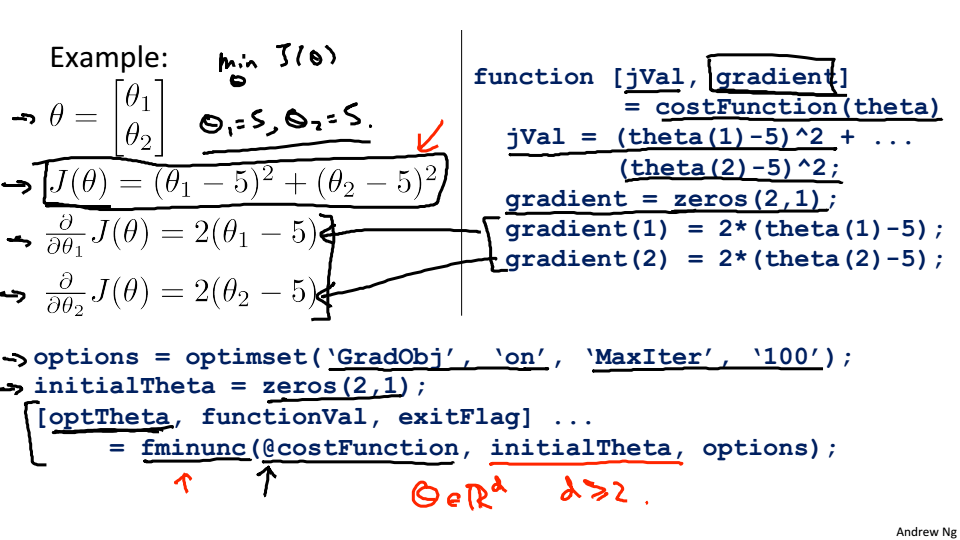
Advanced Optimization
优化方法:共轭梯度、BFGS、L-BFGS,这些方法不需要选择学习率,比梯度下降快,但是非常的复杂,建议直接调用库

只需提供代价函数和梯度,通过fminunc函数就可以计算出参数,fminunc是matlab中的一个优化求解器,可以找到无约束函数的最小值。
Mutliclass Classification
选取一个类,将其他类放在一个单独的类,对每种情况做二分逻辑回归,取返回的预测函数的最大值

Sloving the Problem of Overfitting
The Problem of Overfitting
第一张图就是欠拟合,也叫作高偏差,意思是没有很好的拟合数据,结果与实际有偏差
第三张图就是过拟合,也叫作高方差,当我们拟合一个高阶多项式,函数能很好的拟合训练集中的几乎所有数据,导致函数过于庞大变量太多,这时如果没有足够的数据去约束这个变量过多的模型那么这就是过拟合,当有新的样本数据,模型就不能很好的拟合
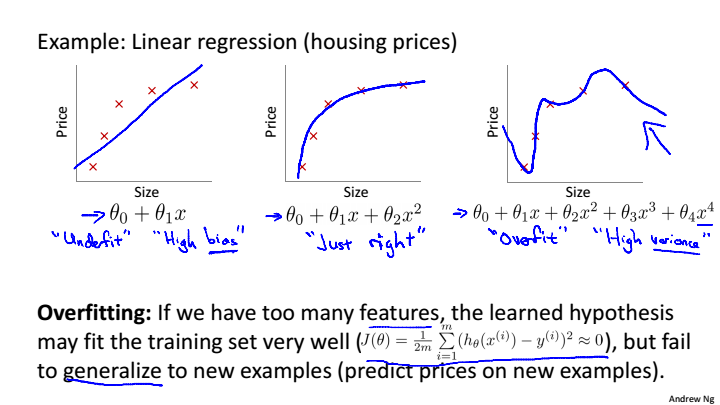
解决过拟合的两个方法:
1)减少特征的数量:

- 手动选择要保留哪些特性。
- 使用模型选择算法。
2)正则化: - 保留所有的特征, 减小参数的大小。
- 当我们有很多稍微有用的特性时,正则化就会很好地工作。
Cost Function
给参数
加上惩罚项,使得参数对模型的影响降低,避免过拟合,
叫作正则化参数,如果
过大,则会导致欠拟合,如果
过小,则起不到相应的作用,一般来说不惩罚
,但惩罚
影响也非常小

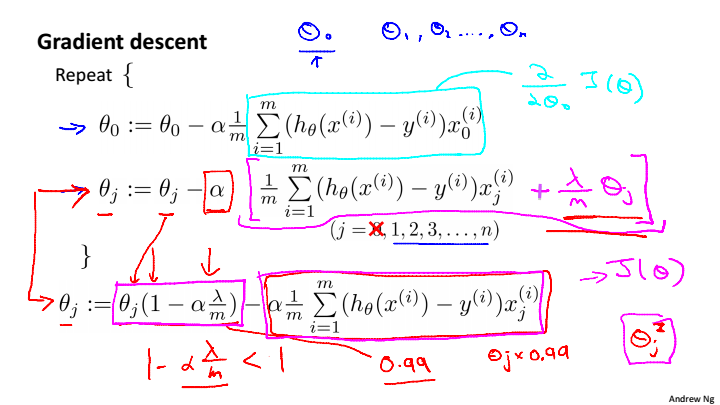
Regularized Linear Regression
梯度下降,
总是小于1的整数,可以看做逼近于1,这就把参数压缩了
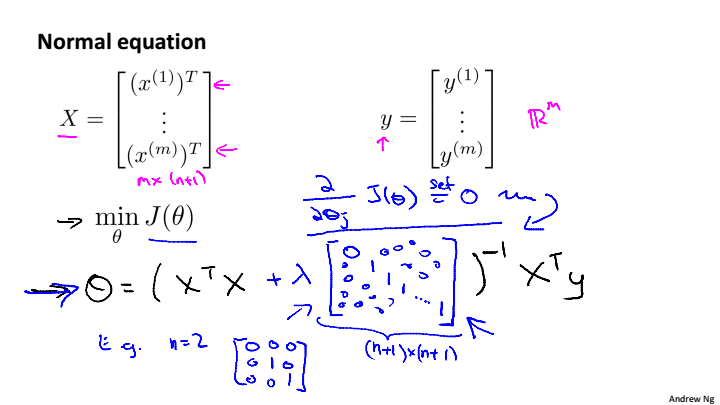
正规方程求解
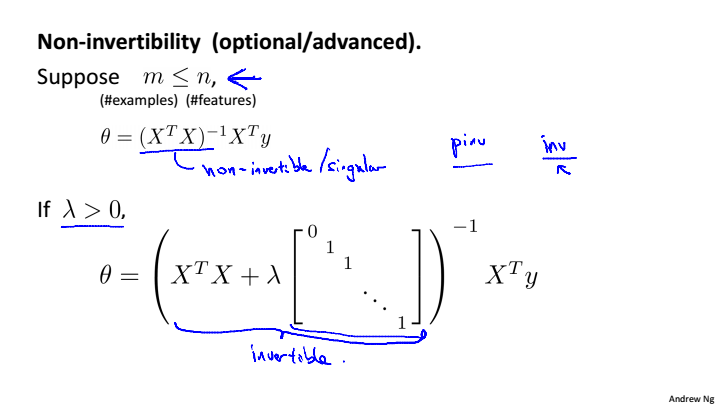
,当样本数量小于特征数量是,
不可逆,当正则化后,只要
>0,就一定可逆
Regularized Logistic Regression
