本系列是针对于DataWhale学习小组的笔记,从一个对统计学和机器学习理论基础薄弱的初学者角度出发,在小组学习资料的基础上,由浅入深地对知识进行总结和整理,今后有了新的理解可能还会不断完善。由于水平实在有限,不免产生谬误,欢迎读者多多批评指正。如需要转载请与博主联系,谢谢
线性回归算法核心概念
线性回归是什么?
回归模型是用来表示输入变量(自变量)到输出变量(因变量)之间映射关系的函数。当该函数属于线性函数时被称为线性回归模型,可以将其看作是由一个或多个被称为回归系数的模型参数的线性组合。
通俗地说就是用来定量表示多个指标(比如房间数量、房间面积与总房价)之间存在的数量关系的线性方程。
线性回归一般实现形式
假设\(x_{1}\)、\(x_{2}\)……\(x_{d}\)为待研究对象的自变量(如房间数量、房间面积等),\(y\)为与自变量有关的因变量(总房价),若用线性函数表示,则二者的关系可以写作:
其中\(θ_{i}\)是模型的参数,负责调整每个自变量对因变量影响的权重。线性回归模型拟合的过程就可以看做是利用我们已获得的数据集(采样得到,其中每一组数据都包含该样本各个自变量的值\(x_{i}\)及其对应的因变量的值\(y_{i}\))来寻找最合适的参数\(θ_{i}\),从而使模型的预测值\(f(x)\)尽可能接近真实值\(y\)的过程。
而想要找到最合适的参数,就要有一个评价模型效果的标准,还要有一个调整参数的策略。
均方误差作为预测值与真实值之差的平方和,是线性回归模型中最常用的评价指标之一,即:
我们的任务就是通过令均方误差取最小值来寻找最优的模型参数,此处的均方误差也被称为代价函数(Cost Function),即用来度量全部样本集的平均偏离程度的函数。
线性回归模型的优化方法
由上述讨论可知,我们需要一个参数调整策略来实现代价函数的最小化,这里常用的方法有最小二乘法、梯度下降法、牛顿法及拟牛顿法等:
最小二乘法(Least squares):
假设针对某一问题的数据集中共有n个样本(观测值),每个样本含有m个特征(自变量),其可由矩阵表示为:
其输出(因变量)可表示为:
此时线性方程可写作:
通过推导,最优参数θ可由下式得出:
上述方法为最小二乘法的矩阵解法,该解法相比与其他解法更加简洁,也便于计算机操作,是实现最小二乘法的最常用方法之一。
梯度下降法(Gradient descent):
梯度下降的核心思路就是利用迭代不断更新参数,使得目标函数收敛到最小值,其具体实现方法是在可微函数(目标函数)的当前位置寻找令函数值下降最快的方向(即梯度的反方向,梯度可看做是由函数对每个自变量分别求导构成的向量),然后沿该方向以一定速度对自变量(即参数θ)进行更新,如下式所示:
α为学习速率,决定了执行每一步梯度下降的步幅,速率越大,函数值下降越快,但过大的学习速率可能带来不收敛的问题。式中对J(θ)的求导:
此处下标j表示第j个参数,上标i表示第i个数据点。将$$frac{\partial{J(\theta)}}{\partial\theta}$$代入后写成向量表示的参数更新式:
此方法成为批梯度下降,即一次迭代同时对所有样本进行计算,在目标函数为凸函数时,可保证到达最小值,但当样本量大时会带来很大的计算量。为了解决这一问题,人们又提出了随机梯度下降方法:
随机梯度下降方法计算量小,程序运行速度快,但存在精度下降,可能收敛至局部最优等缺点。因此后来又提出了小批量梯度下降法,即每次计算固定数目的样本来对参数进行更新,在此不再赘述。
牛顿法(Newton's method)和拟牛顿法(Quasi-Newton methods):
牛顿法和拟牛顿法也是处理无约束最优化问题的常用方法,其突出特点为收敛速度快。牛顿法的基本思路是利用泰勒展开对较为复杂的函数在当前位点做线性函数近似,然后通过求该函数在区域内的极小值来逼近原函数的最小值,并通过反复迭代来完成对最小值的搜寻。对函数f(x)作泰勒展开并忽略二次以上高阶项得:
以向量形式表示为:
两边同时求梯度并令梯度等于0可得:
其中\(\bigtriangledown ^{2}f(x_0)\)我们称为Hessian矩阵,用H表示。
回到我们参数优化的问题,设\(l(\theta)\)为损失函数,我们更新的策略是:
其中,\(\Delta_{\theta}l(\theta)\)是\(l(\theta)\)对\(\theta_i\)的偏导数,也就是求梯度。\(H\)是\(J(\theta)\)的海森矩阵,
总结下牛顿法的完整步骤为:
- 设定初始值\(x_0\)及精度要求ε。
- 计算当前近似函数的梯度\(\Delta_{\theta}l(\theta)\)和Hessian矩阵。
- 判断,如果梯度的模小于精度要求ε,则模型收敛,停止迭代,否则继续下一步。
- 根据参数更新公式进行迭代,获得下一个点位置\(x_1\),然后返回到第二步。
海森矩阵的计算较为复杂,当参数的维度很多时影响更大。因此人们提出拟牛顿法,及不用二阶偏导数而构造出可以近似海塞矩阵(或海塞矩阵的逆)的正定对称阵B来完成计算。设\(x_k\)是第k个迭代值,则对该新构造矩阵的要求如下(忽略证明...):
从网络上看到的常用的拟牛顿法迭代公式总结表:
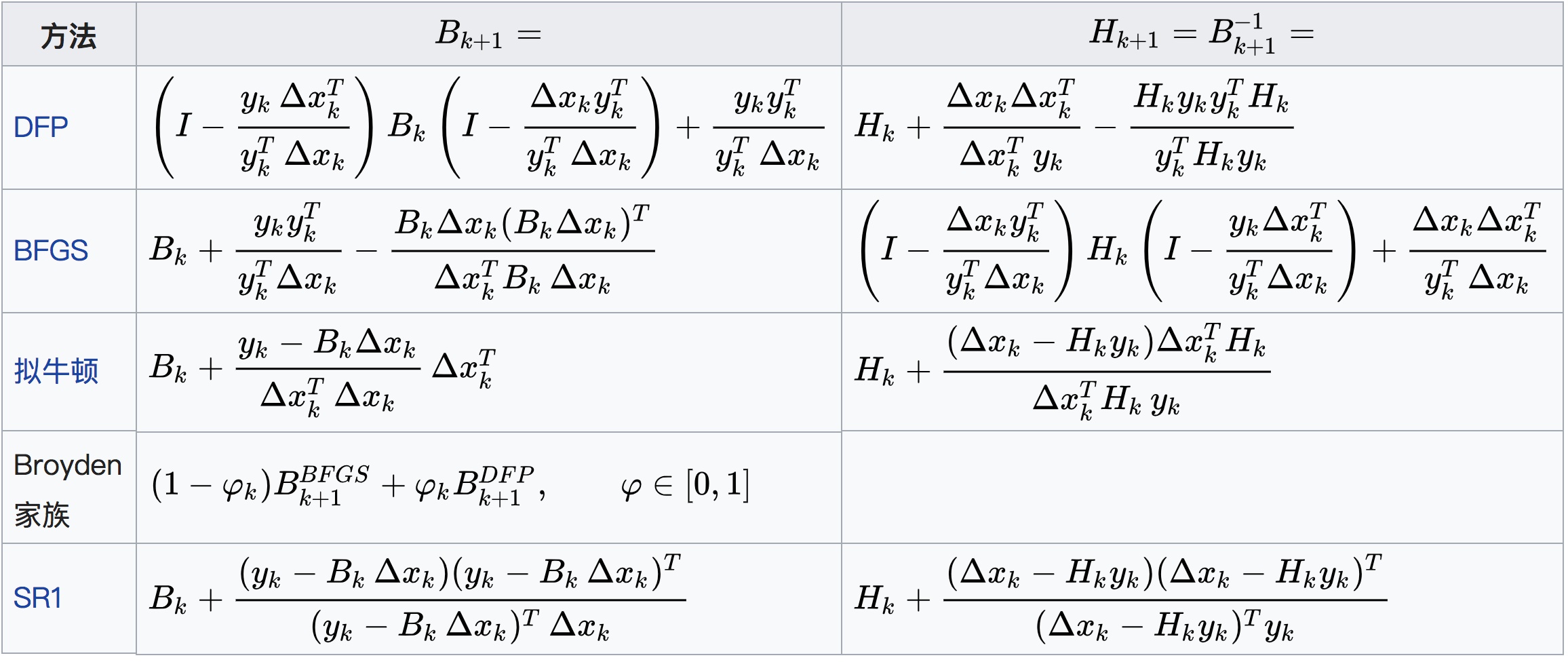
今后有时间再对拟牛顿法做一些深入探讨。
参考资料:
- https://github.com/datawhalechina/team-learning/tree/master/机器学习算法基础 DataWhale小组学习资料
- https://baike.baidu.com/item/线性回归/8190345?fr=aladdin 百度百科——线性回归
- https://blog.csdn.net/qq_41800366/article/details/86583789 梯度下降法原理讲解
- https://blog.csdn.net/sigai_csdn/article/details/80678812 理解牛顿法
- https://zhuanlan.zhihu.com/p/46536960 牛顿法和拟牛顿法