softmax基本概念
softmax是单层神经网络,与线性回归相同,通常用于离散的分类问题。掌握softmax需要掌握模型、数据集、损失函数和优化函数四个方面。
-
softmax的使用场景
softmax一般用于离散分类问题,使用softmax主要解决两个问题:
(1)不采用softmax层直接使用输出层会使得输出值的范围不确定,难以通过直观意义确定输出数值的意义。
(2)数据集的真实标签是离散值,这些离散值与不确定范围的输出值之间的误差难以衡量。 -
softmax模型
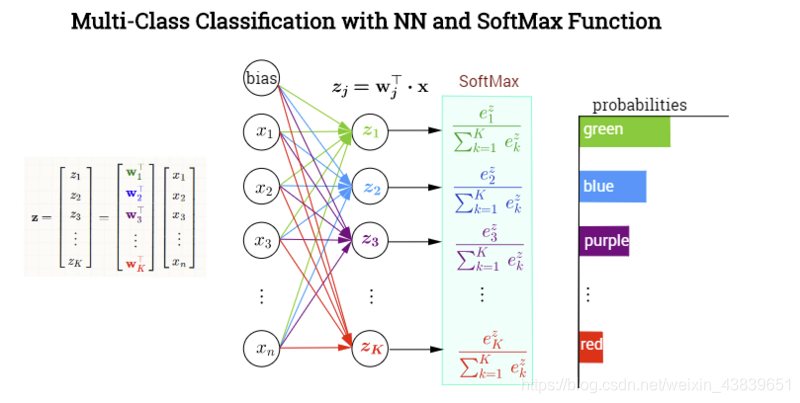
注:上述图片引自https://segmentfault.com/a/1190000017320763
如上图所示,softmax是单层神经网络,其主要作用在于将输出值再通过softmax运算符(softmax operator)进行转换,使其变为所有值为正且和为1的概率分布。转换后,要知道分类后的结果只需找到最大的概率值即可。
因此,目标函数转换成为:
3. 损失函数
对于softmax而言,若采用均方差函数作为损失函数,则要求过于严格,导致不必要的资源浪费。对于离散分类问题而言,最重要的在于对于分类正确的预测值显著大于其余预测值即可。改善该问题的一个方法就是使用更适合衡量两个概率分布差异的测量函数。其中,交叉熵(cross entropy)是一个常用的衡量方法:
假设每次迭代的训练数据样本数量为
,则交叉熵损失函数定义为:
最小化交叉熵损失函数等价于最大化训练数据集所有标签类别的联合预测概率。
对于交叉熵的理解,本文举一个小例子: [^1]
假如有一个三分类问题,其采用模型的预测概率和真实的标签如下表所示:

根据交叉熵损失的计算公式可得到:
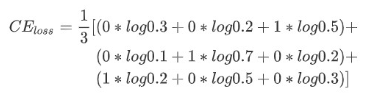
[^1]:https://zhuanlan.zhihu.com/p/35709485
