学习地址:https://www.boyuai.com/elites/course/cZu18YmweLv10OeV/jupyter/MA03VfYBa12-oJ9mi6ZPV
文本分类
文本分类是自然语言处理的一个常见任务,它把一段不定长的文本序列变换为文本的类别。本节关注它的一个子问题:使用文本情感分类来分析文本作者的情绪。这个问题也叫情感分析,并有着广泛的应用。
同搜索近义词和类比词一样,文本分类也属于词嵌入的下游应用。在本节中,我们将应用预训练的词向量和含多个隐藏层的双向循环神经网络与卷积神经网络,来判断一段不定长的文本序列中包含的是正面还是负面的情绪。后续内容将从以下几个方面展开:
文本情感分类数据集
使用循环神经网络进行情感分类
使用卷积神经网络进行情感分类
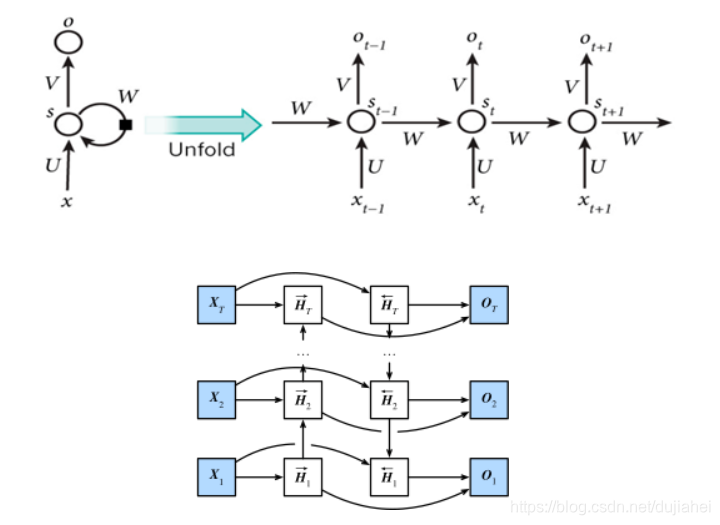
使用循环神经网络
使用卷积神经网络
一维卷积层
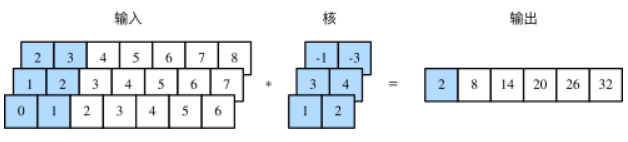
在介绍模型前我们先来解释一维卷积层的工作原理。与二维卷积层一样,一维卷积层使用一维的互相关运算。在一维互相关运算中,卷积窗口从输入数组的最左方开始,按从左往右的顺序,依次在输入数组上滑动。当卷积窗口滑动到某一位置时,窗口中的输入子数组与核数组按元素相乘并求和,得到输出数组中相应位置的元素。如图所示,输入是一个宽为 7 的一维数组,核数组的宽为 2。可以看到输出的宽度为 7−2+1=6,且第一个元素是由输入的最左边的宽为 2 的子数组与核数组按元素相乘后再相加得到的:0×1+1×2=2。

多输入通道的一维互相关运算也与多输入通道的二维互相关运算类似:在每个通道上,将核与相应的输入做一维互相关运算,并将通道之间的结果相加得到输出结果。下图展示了含 3 个输入通道的一维互相关运算,其中阴影部分为第一个输出元素及其计算所使用的输入和核数组元素:0×1+1×2+1×3+2×4+2×(−1)+3×(−3)=2。
由二维互相关运算的定义可知,多输入通道的一维互相关运算可以看作单输入通道的二维互相关运算。如图所示,我们也可以将图中多输入通道的一维互相关运算以等价的单输入通道的二维互相关运算呈现。这里核的高等于输入的高。图中的阴影部分为第一个输出元素及其计算所使用的输入和核数组元素:2×(−1)+3×(−3)+1×3+2×4+0×1+1×2=2。
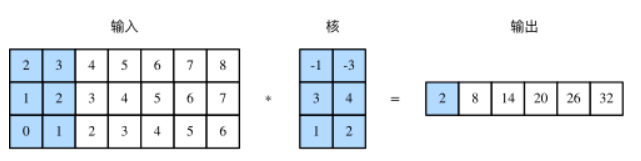
注:反之仅当二维卷积核的高度等于输入的高度时才成立。
时序最大池化层
类似地,我们有一维池化层。TextCNN 中使用的时序最大池化(max-over-time pooling)层实际上对应一维全局最大池化层:假设输入包含多个通道,各通道由不同时间步上的数值组成,各通道的输出即该通道所有时间步中最大的数值。因此,时序最大池化层的输入在各个通道上的时间步数可以不同。

TextCNN 模型
TextCNN 模型主要使用了一维卷积层和时序最大池化层。假设输入的文本序列由 n 个词组成,每个词用 d 维的词向量表示。那么输入样本的宽为 n,输入通道数为d 。TextCNN 的计算主要分为以下几步。
1.,定义多个一维卷积核,并使用这些卷积核对输入分别做卷积计算。宽度不同的卷积核可能会捕捉到不同个数的相邻词的相关性。
2.,对输出的所有通道分别做时序最大池化,再将这些通道的池化输出值连结为向量。
3.通过全连接层将连结后的向量变换为有关各类别的输出。这一步可以使用丢弃层应对过拟合。
数据增强/图像增广
大规模数据集是成功应用深度神经网络的前提。图像增广(image augmentation)技术通过对训练图像做一系列随机改变,来产生相似但又不同的训练样本,从而扩大训练数据集的规模。图像增广的另一种解释是,随机改变训练样本可以降低模型对某些属性的依赖,从而提高模型的泛化能力。例如,我们可以对图像进行不同方式的裁剪,使感兴趣的物体出现在不同位置,从而减轻模型对物体出现位置的依赖性。我们也可以调整亮度、色彩等因素来降低模型对色彩的敏感度。可以说,在当年AlexNet的成功中,图像增广技术功不可没。本节我们将讨论这个在计算机视觉里被广泛使用的技术。
常见的图像增广方法
1.翻转和裁剪
左右翻转图像通常不改变物体的类别。它是最早也是最广泛使用的一种图像增广方法。下面我们通过torchvision.transforms模块创建RandomHorizontalFlip实例来实现一半概率的图像水平(左右)翻转。
2.变化颜色
可以从4个方面改变图像的颜色:亮度(brightness)、对比度(contrast)、饱和度(saturation)和色调(hue)。
3.叠加多个图像增广方法
实际应用中我们会将多个图像增广方法叠加使用。我们可以通过Compose实例将上面定义的多个图像增广方法叠加起来,再应用到每张图像之上。
模型微调
1.在源数据集(如ImageNet数据集)上预训练一个神经网络模型,即源模型。
2.创建一个新的神经网络模型,即目标模型。它复制了源模型上除了输出层外的所有模型设计及其参数。我们假设这些模型参数包含了源数据集上学习到的知识,且这些知识同样适用于目标数据集。我们还假设源模型的输出层跟源数据集的标签紧密相关,因此在目标模型中不予采用。
3.为目标模型添加一个输出大小为目标数据集类别个数的输出层,并随机初始化该层的模型参数。
4.在目标数据集(如椅子数据集)上训练目标模型。我们将从头训练输出层,而其余层的参数都是基于源模型的参数微调得到的。
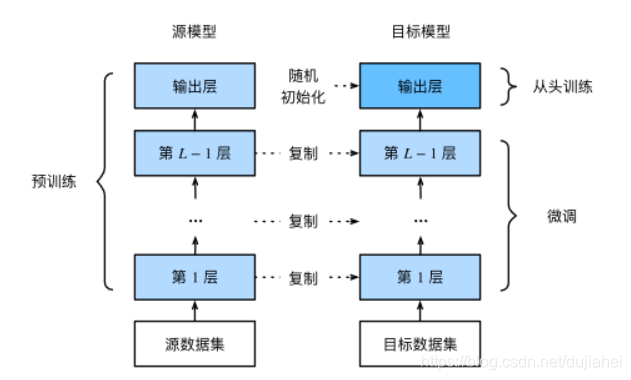
当目标数据集远小于源数据集时,微调有助于提升模型的泛化能力。
