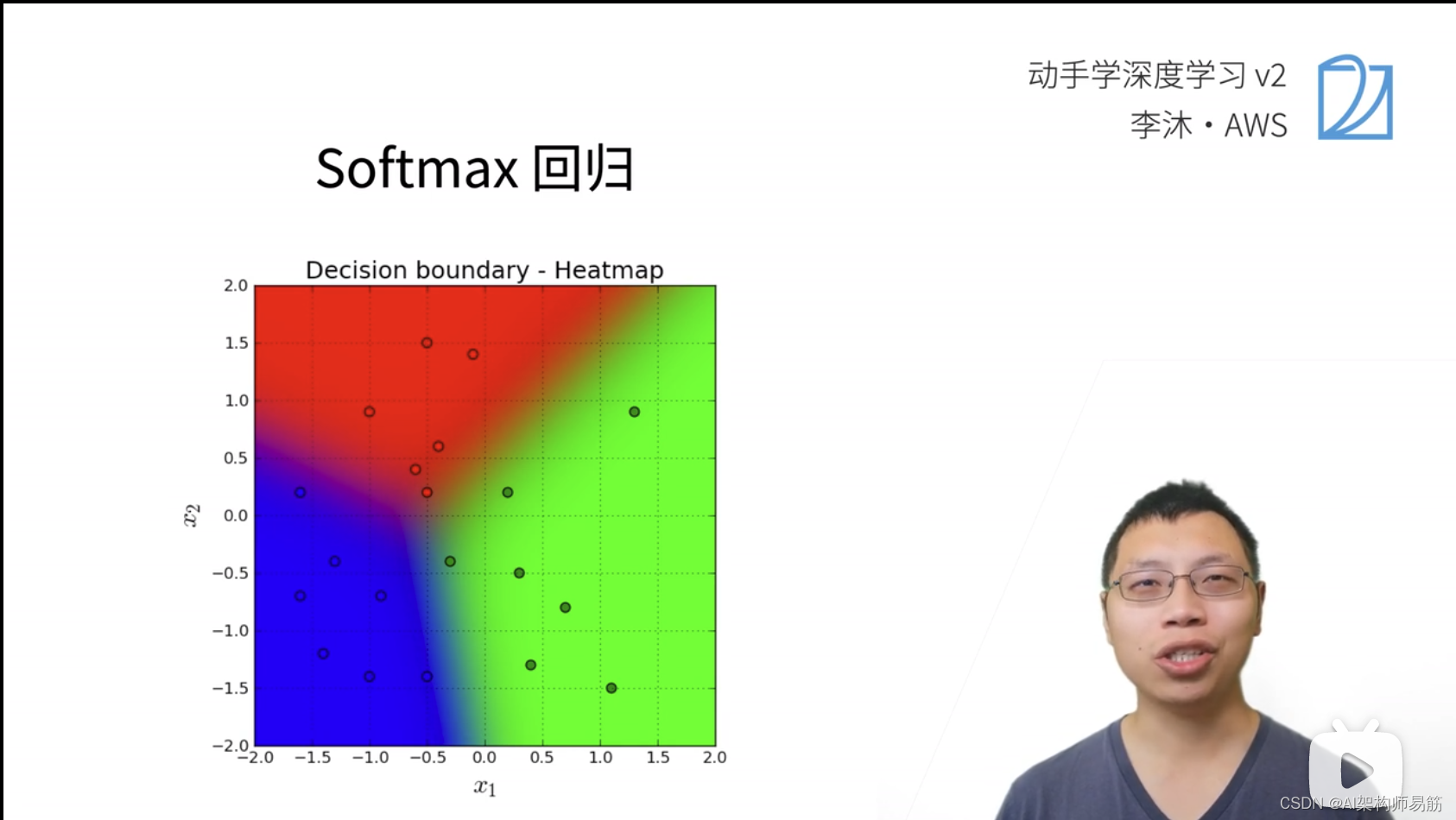
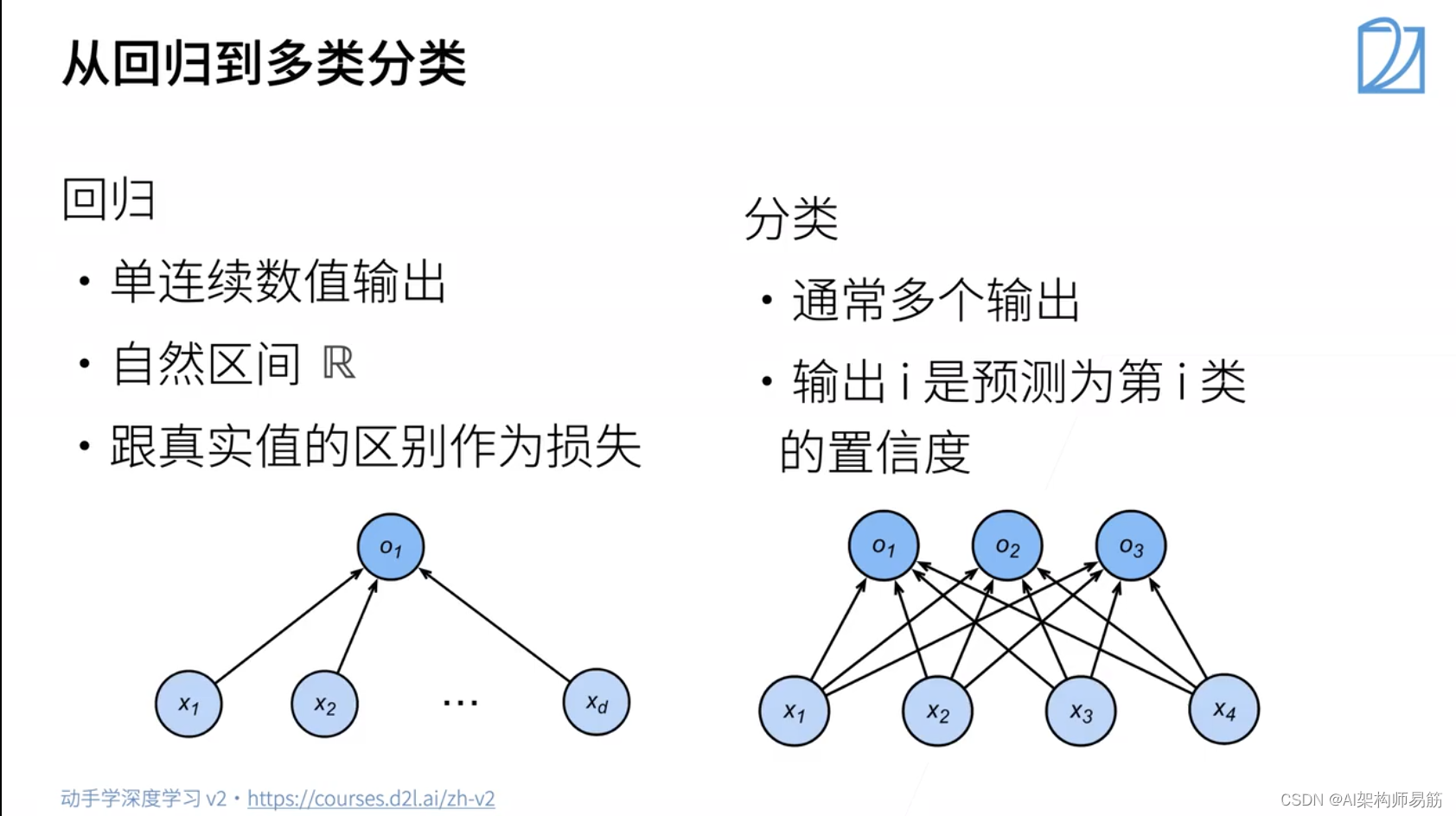
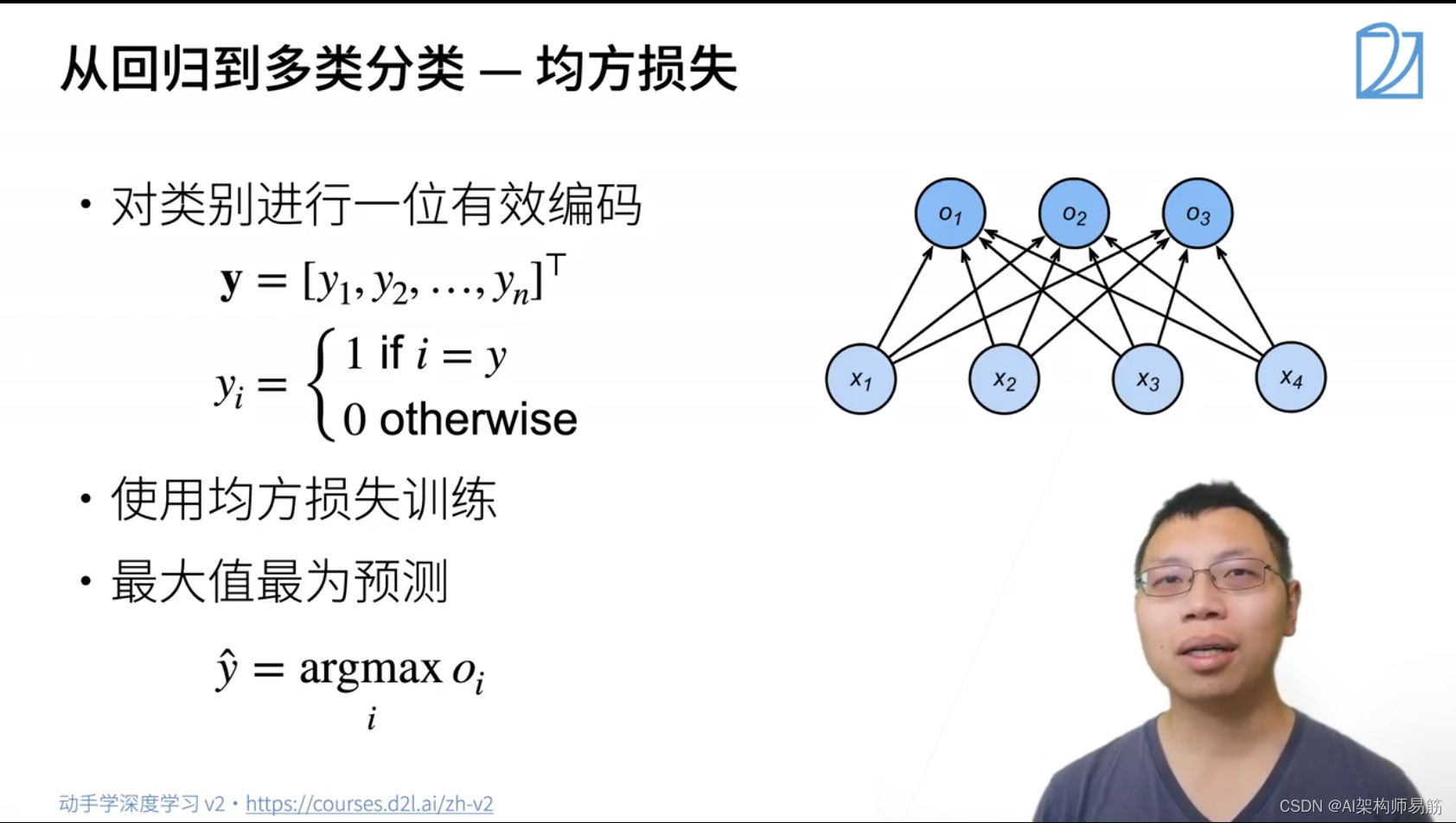
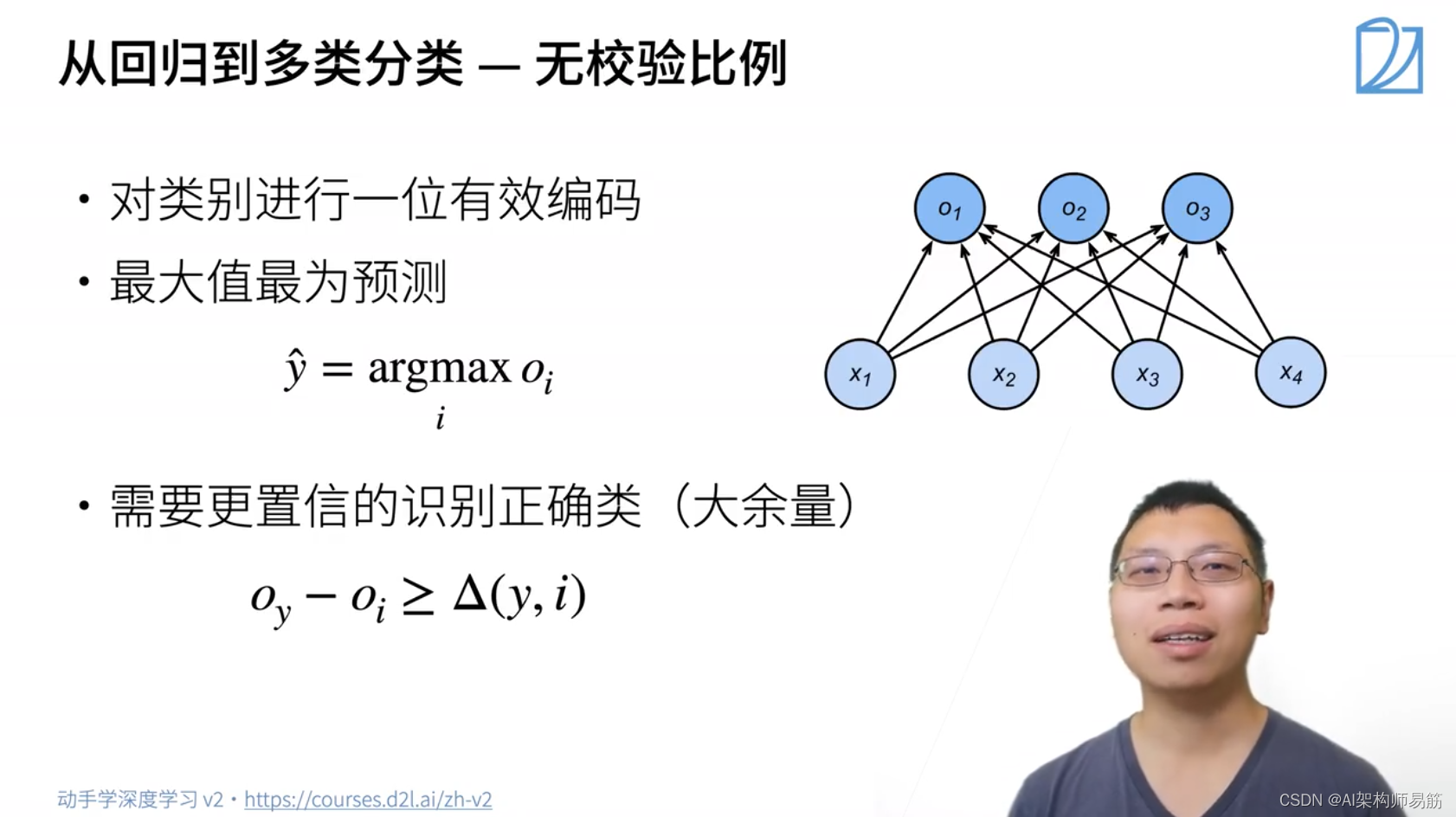
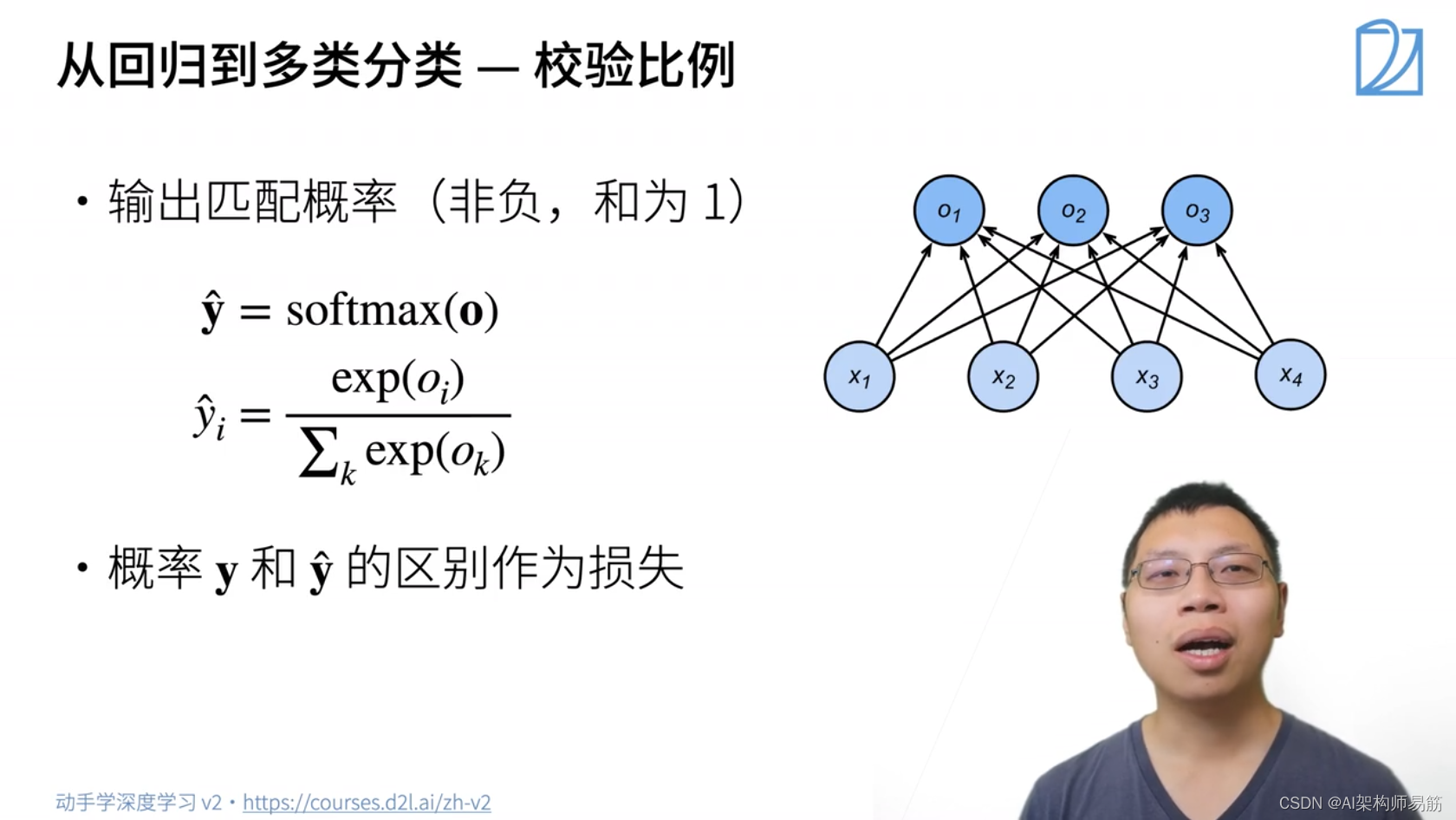
1. Softmax 回归



2. 损失函数
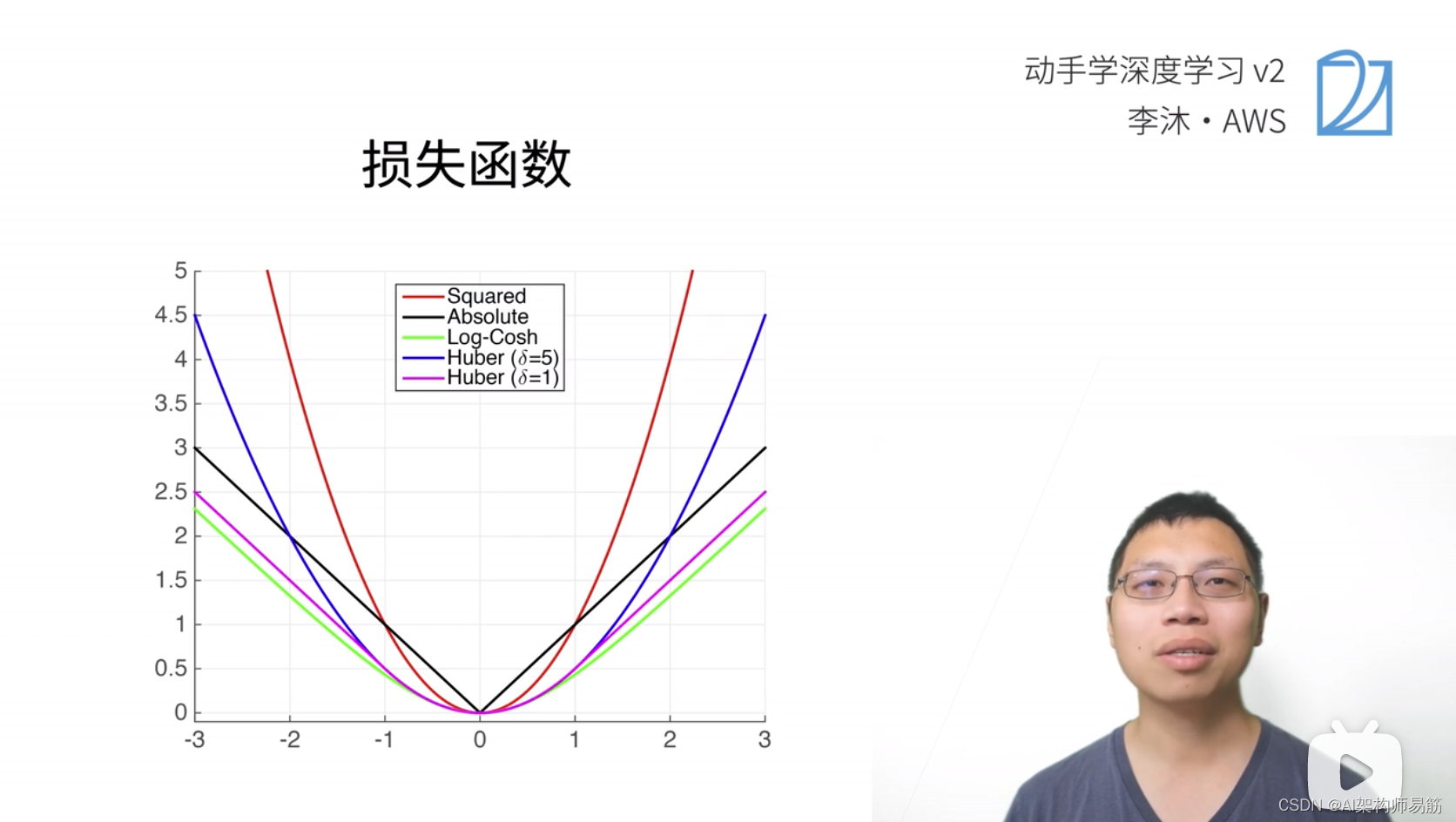
2.1 L2 Loss 均分平方损失函数
蓝色的线:变化的损失函数, 当y=0, y'的变化的预测值, 这是个二次函数0.5 * y'^2
绿色的线:似然函数 e^-l
橙色的线:损失函数的梯度,梯度就是一个一次函数y-y'
梯度下降的时候,我们是根据负梯度的方向来更新我们的参数,所以它的导数就决定如何更新参数。当真实值y,跟预测值y’隔的比较远的时候,(y-y') 变化是比较大的;反之靠近原点的时候,导数则比较小。
缺点,离圆点比较远的时候,我们不一定需要变化那么大的梯度,去更新我们的参数。
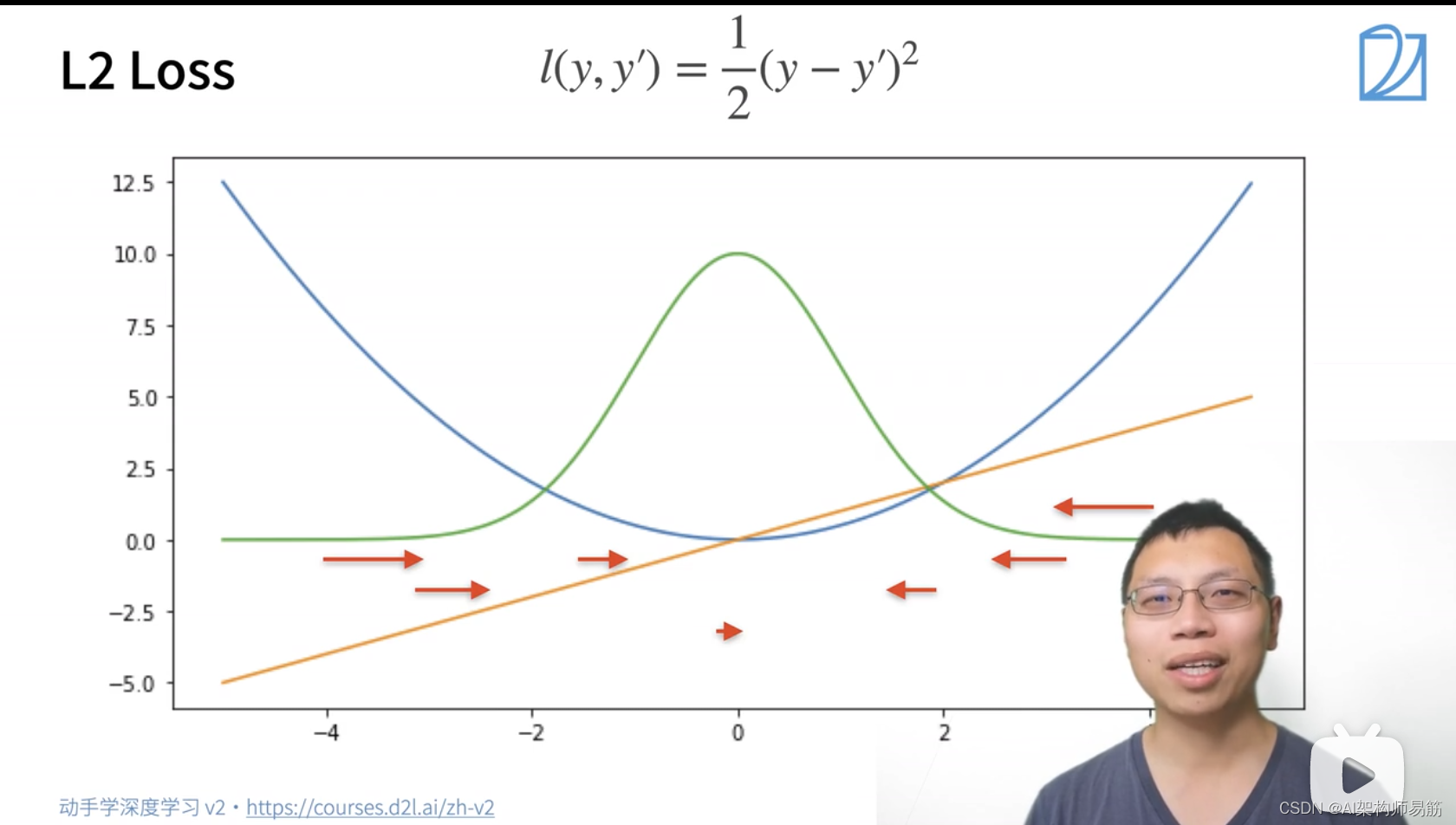
2.2 L1 Loss 绝对值损失函数
蓝色的线:变化的损失函数, 当y=0, y'的变化的预测值, 这是个二次函数y'
绿色的线:似然函数 e^-l,是个高斯分布,但是在0处也比较陡,有个尖顶。
橙色的线:损失函数的梯度,当预测值跟真实值离的比较远时,梯度就是一个绝对值误差,是个常数;当预测值跟真实值离的比较近时,是个指数函数。
为了减小离圆点比较远的时候,不要那么快地去更新参数。可以用绝对值损失函数。
- 当
y' > 0的时候,导数是1; - 当
y' < 0的时候, 导数是 -1; - 当
y' = 0的时候,不可导,导数在[-1,1]之间
不管真实值和预测值隔得多远,变化是个参数。好处,前期的稳定性比较好。当优化到末期的时候,y-y'趋近于0的时候,它的梯度变得很大,就不好优化,也就是绿色尖尖的地方。
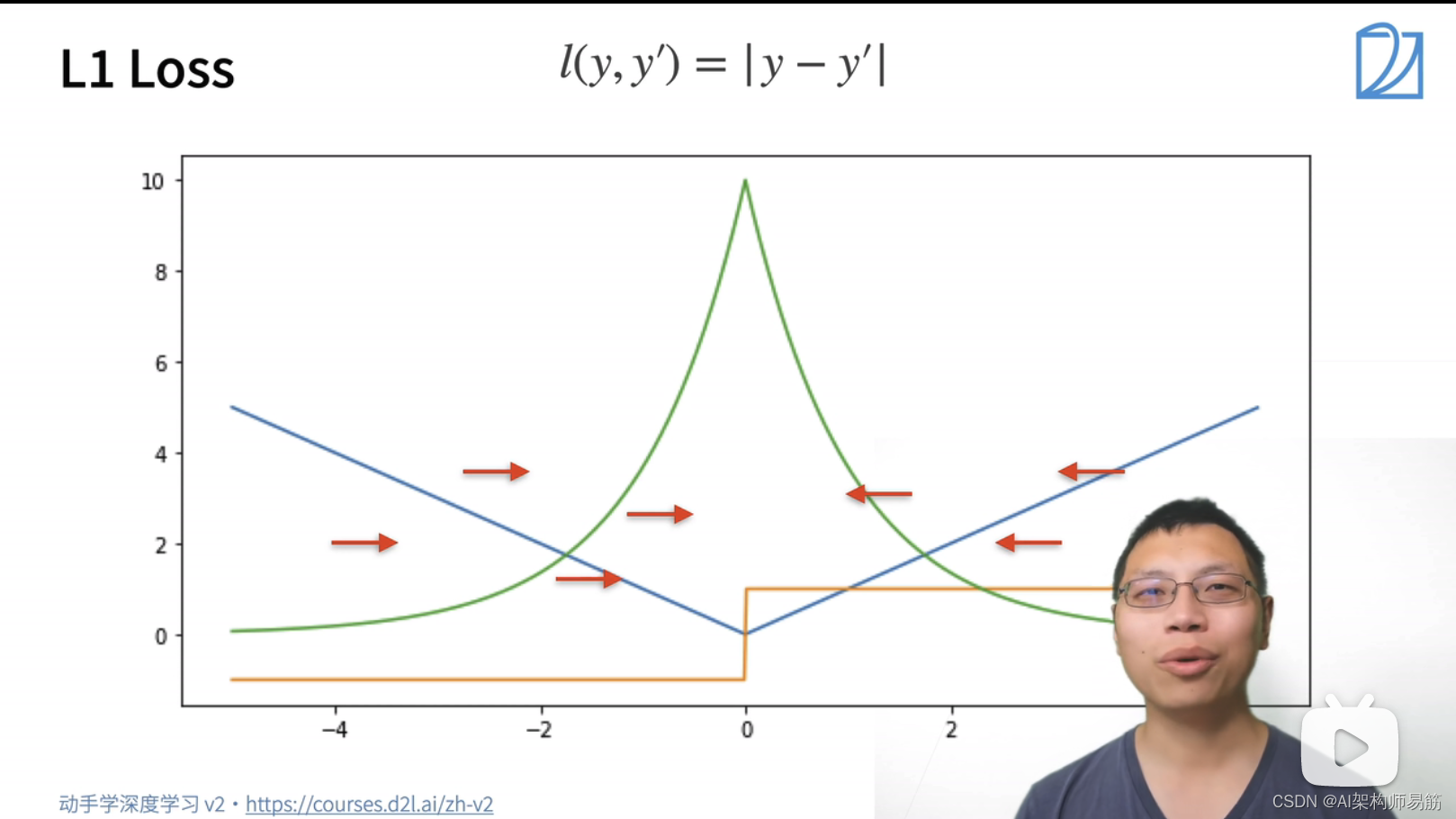
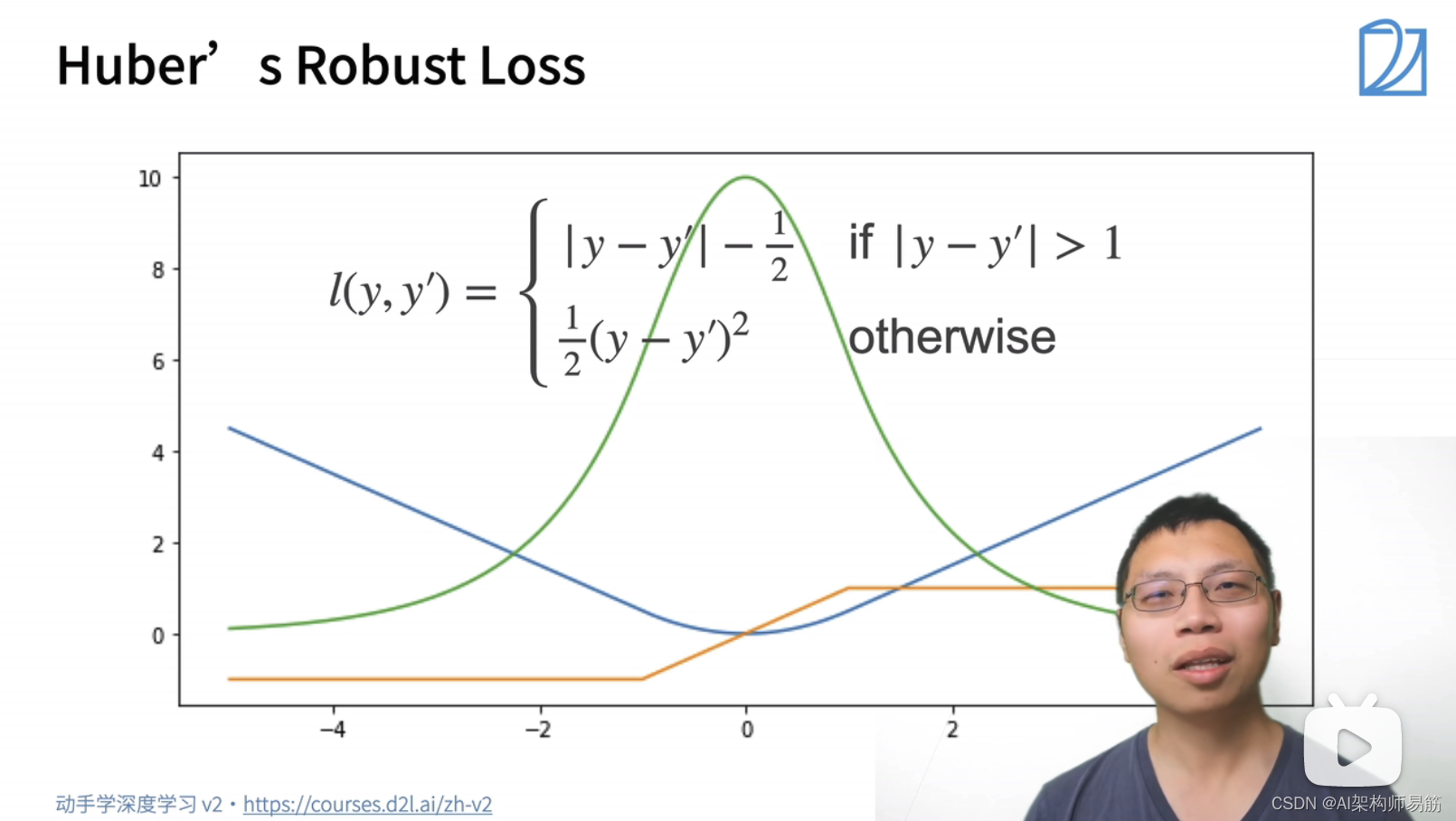
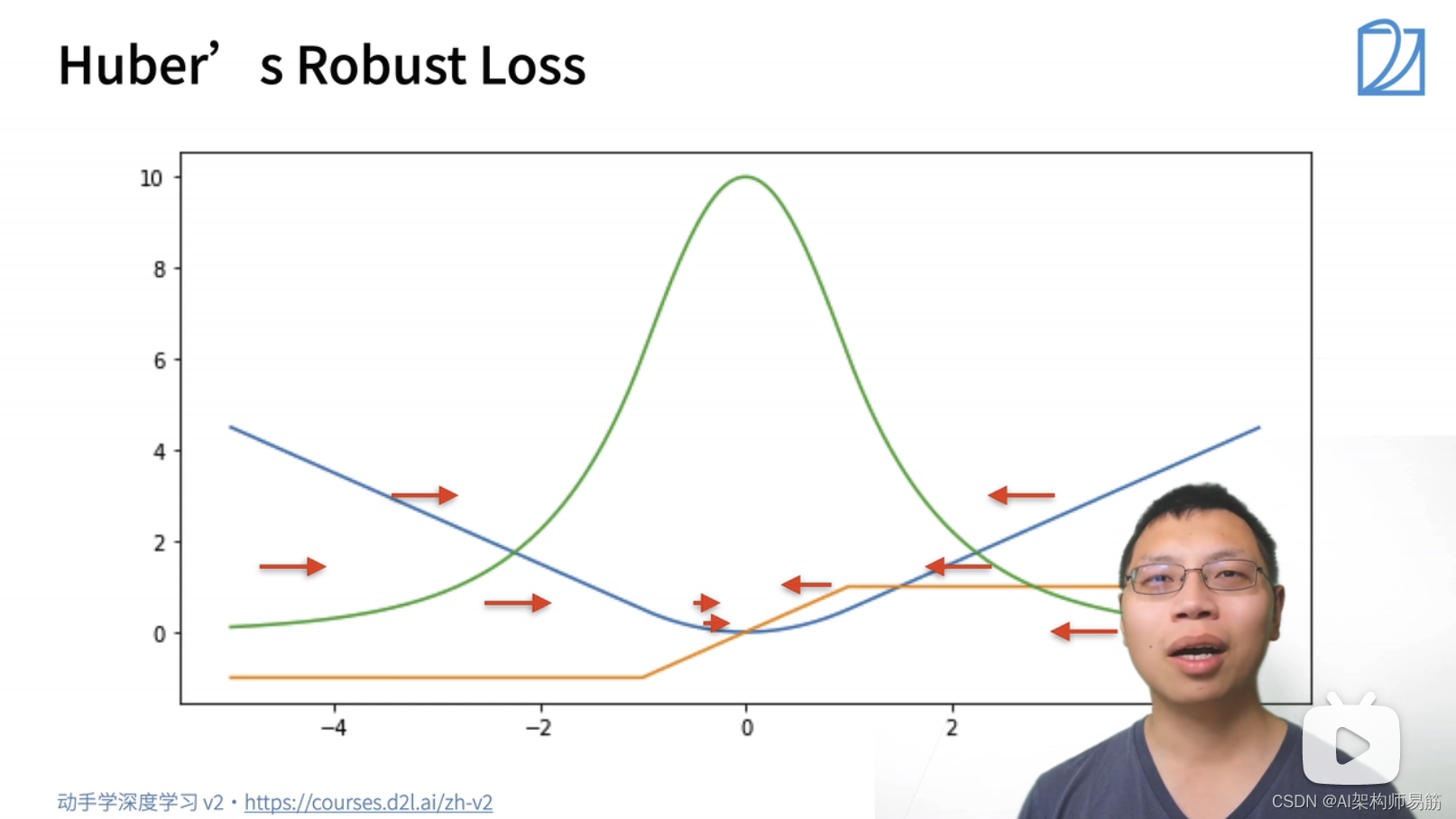
2.3 Huber’s Robust Loss
Huber’s Robust Loss综合了L2 Loss 和 L1 Loss的好处。
蓝色的线:变化的损失函数, 当y=0, y'的变化的预测值, 这是个二次函数y'
绿色的线:似然函数 e^-l,是个高斯分布,但是在0处也比较平滑
橙色的线:损失函数的梯度,当预测值跟真实值离的比较远时,梯度就是一个绝对值误差,是个常数;当预测值跟真实值离的比较近时,是个平方误差。
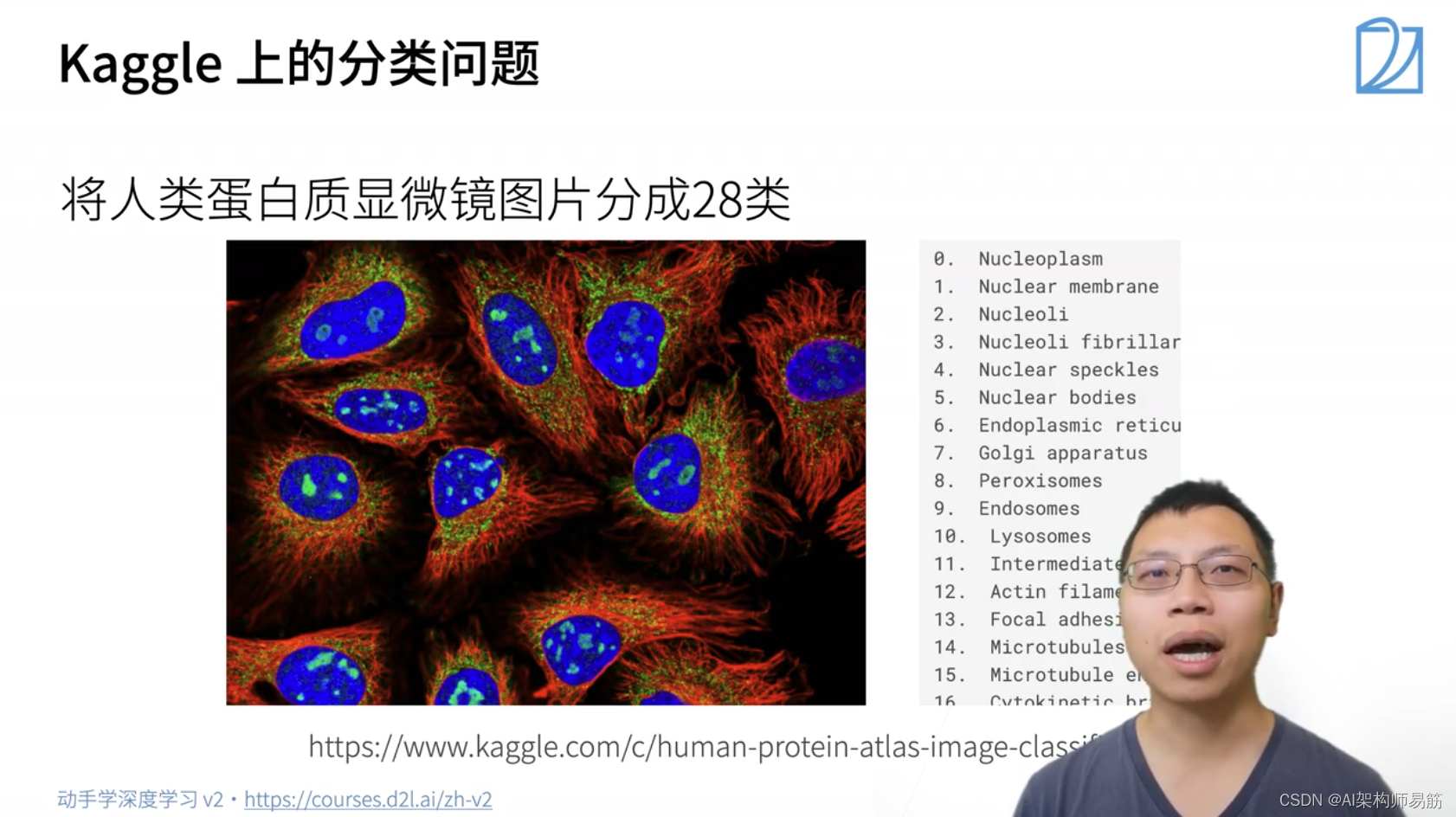
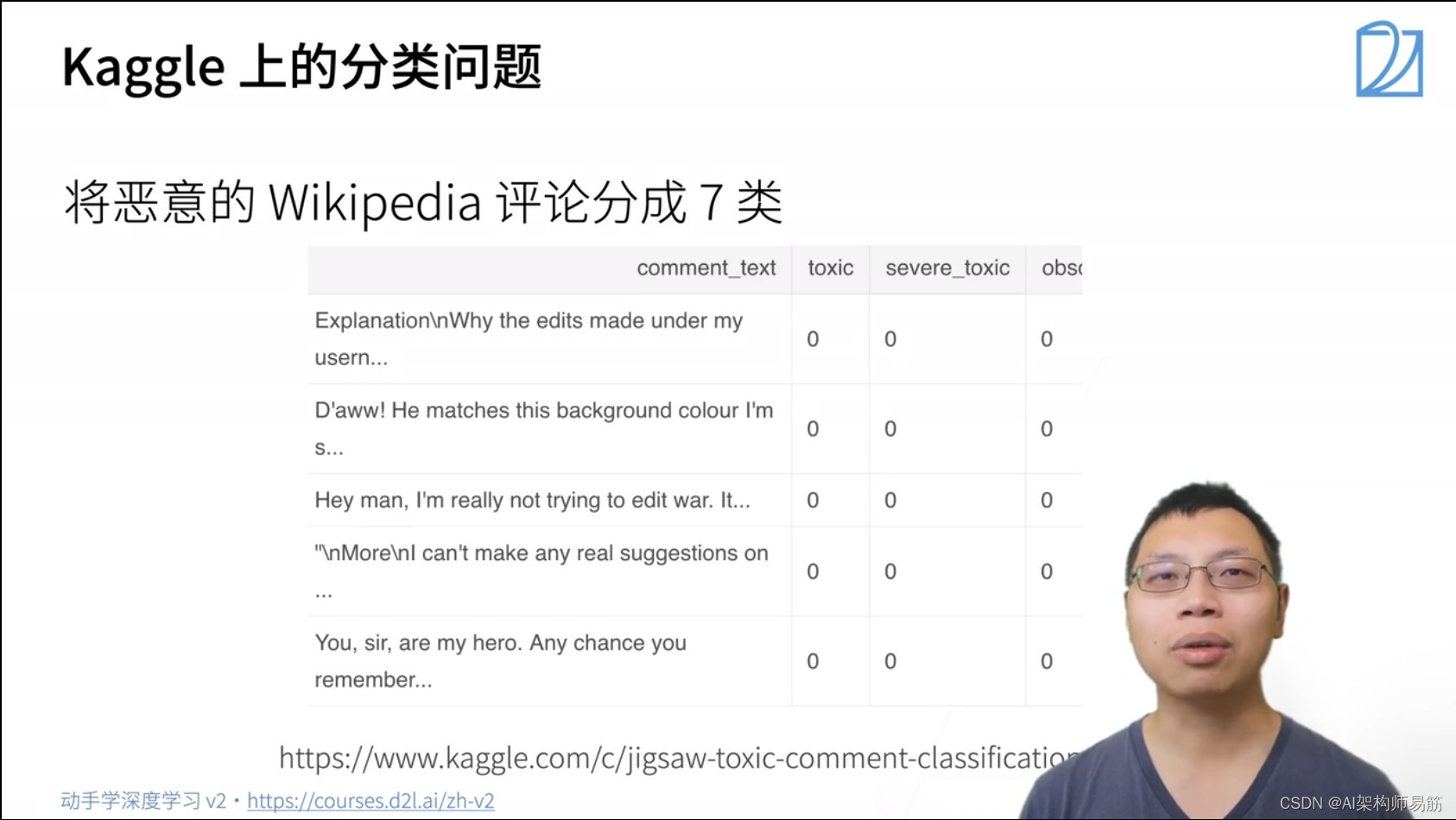
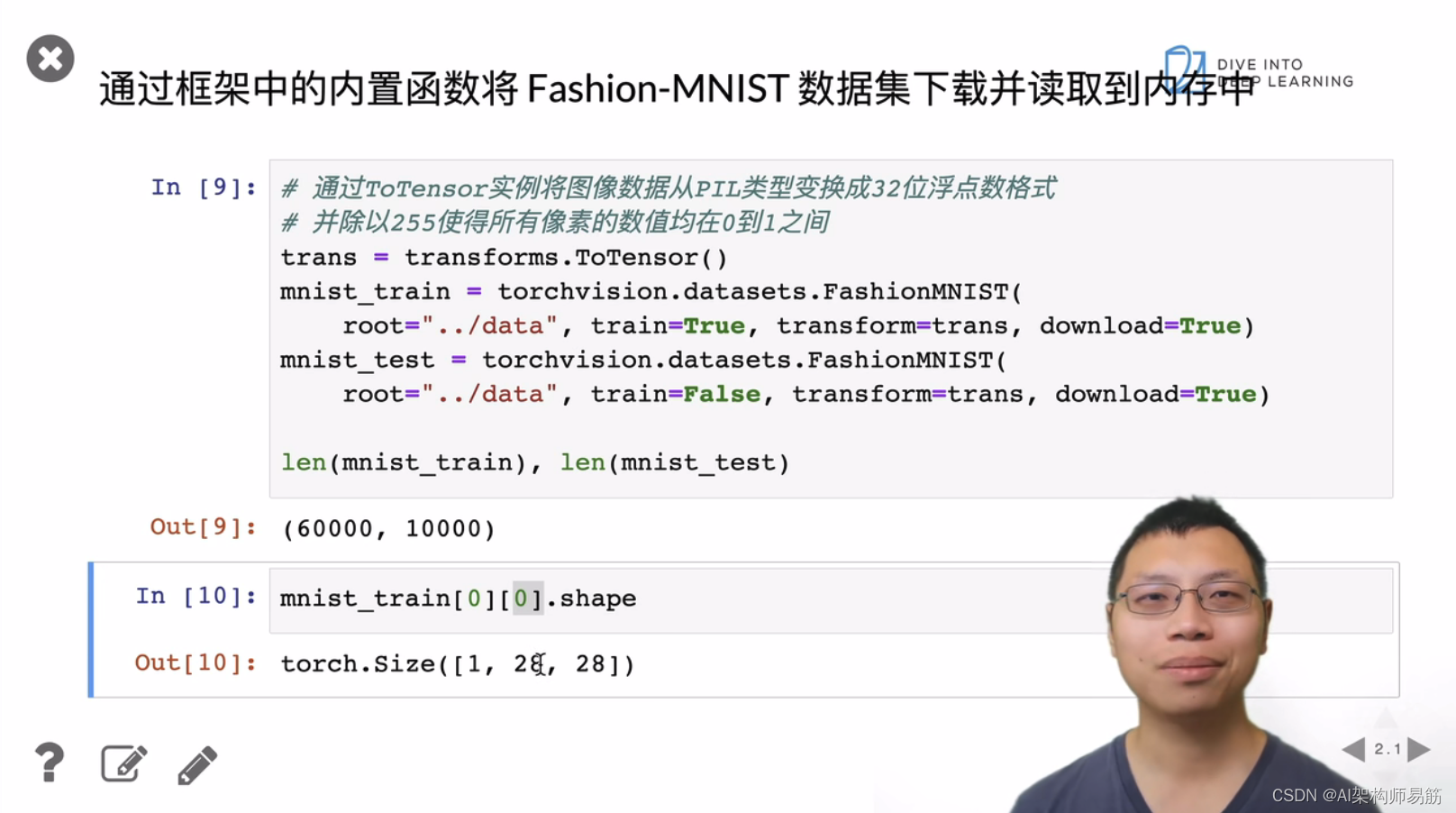
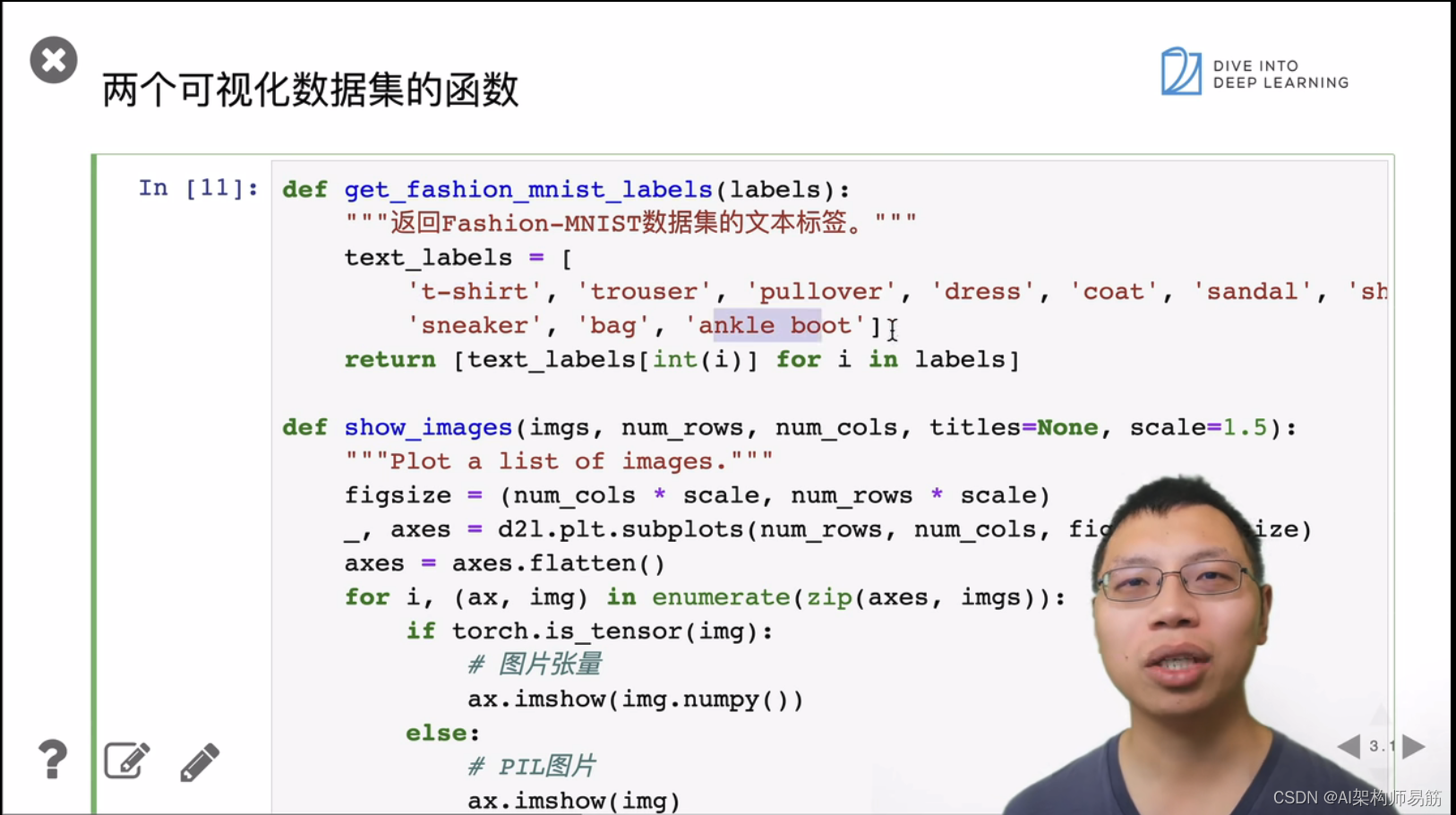
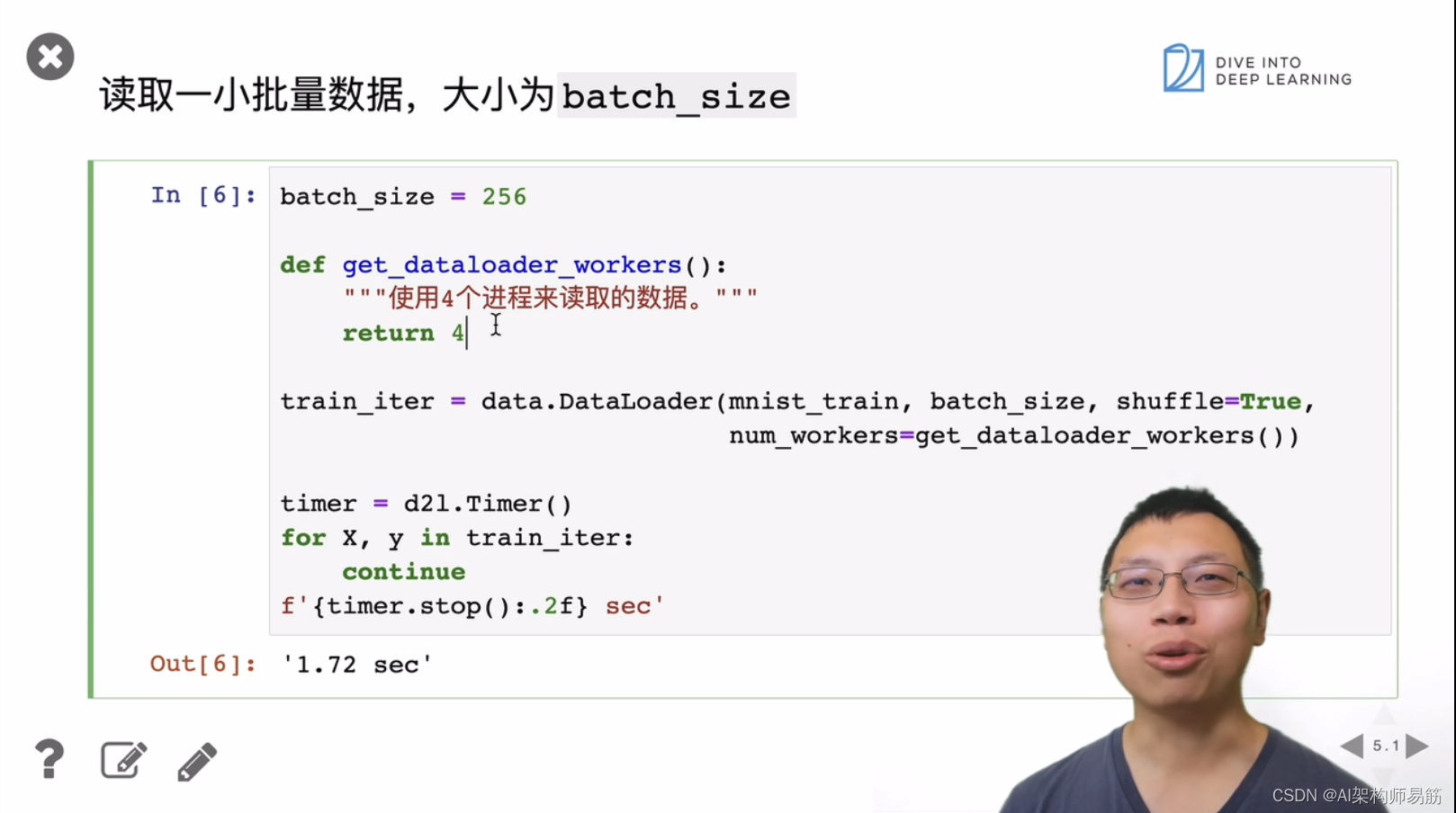
3. 图像分类数据集



参考
https://www.bilibili.com/video/BV1K64y1Q7wu?p=1