1. 线性回归:
知识点:
- 平方损失函数(用来评估评为 i 的样本误差)
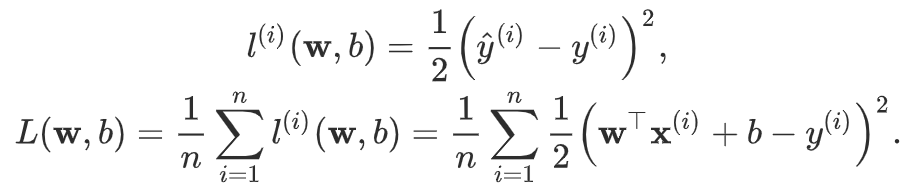
- 优化函数-随机梯度下降
当模型和损失函数形式较为简单时,上面的误差最小化问题的解可以直接用公式表达出来。这类解叫作解析解(analytical solution)。
线性回归和平方误差刚好属于这个范畴。
然而,大多数深度学习模型并没有解析解,只能通过优化算法有限次迭代模型参数来尽可能降低损失函数的值。这类解叫作数值解(numerical solution)
小批量随机梯度下降(mini-batch stochastic gradient descent) 是求解数值解的优化算法。
基本思想如下:
先选取一组模型参数的初始值,如随机选取;接下来对参数进行多次迭代,使每次迭代都可能降低损失函数的值。在每次迭代中,先随机均匀采样一个由固定数目训练数据样本所组成的小批量(mini-batch) ,然后求小批量中数据样本的平均损失有关模型参数的导数(梯度),最后用此结果与预先设定的一个正数的乘积作为模型参数在本次迭代的减小量。
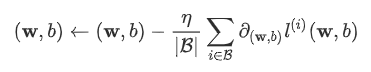
学习率: 代表在每次优化中,能够学习的步长的大小
批量大小: 是小批量计算中的批量大小batch size
因此,优化函数有以下两个步骤:
(i)初始化模型参数,一般来说使用随机初始化;
(ii)我们在数据上迭代多次,通过在负梯度方向移动参数来更新每个参数。
代码实现:
均方误差
def squared_loss(y_hat, y):
return (y_hat - y.view(y_hat.size())) ** 2 / 2
在这里需要注意y.view()的用法;
view的用法:
torch.Tensor.view会返回具有相同数据但大小不同的新张量。 返回的张量必须有与原张量相同的数据和相同数量的元素,但可以有不同的大小。一个张量必须是连续contiguous()的才能被查看。类似于Numpy的np.reshape()。
下面是实现部分:
x = torch.Tensor(2,2,2)
print(x)
y = x.view(1,8)
print(y)
z = x.view(-1,4) # the size -1 is inferred from other dimensions
print(z)
t = x.view(8)
print(t)
f = x.view(-1,1)
print(f)
g = x.view(-1)
print(g.shape)
输出结果:

view_as(tensor)的用法:

pytorch中view的选择:
.resize(): 将tensor的大小调整为指定的大小。如果元素个数比当前的内存大小大,就将底层存储大小调整为与新元素数目一致的大小。如果元素个数比当前内存小,则底层存储不会被改变。原来tensor中被保存下来的元素将保持不变,但新内存将不会被初始化。
.permute(dims):将tensor的维度换位。具体可以自己测试
torch.unsqueeze:返回一个新的张量,对输入的制定位置插入维度
相比之下,如果你想返回相同数量的元素,只是改变数组的形状推荐使用torch.view()
2. softmax和分类模型¶
softmax的公式:

直接使用输出层的缺陷:

交叉熵损失函数:
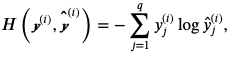

即对于单标签的情况,
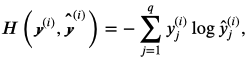
等价于
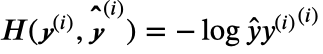
训练样本数据为n时,交叉熵损失函数公式如下:
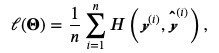

3.多层感知机
知识点:

对于上述公式可知,添加较多的隐藏层其实和仅含输出层的单层神经网络等价。
因此,引入激活函数,来增加非线性。
上述问题的根源在于全连接层只是对数据做仿射变换(affine transformation),而多个仿射变换的叠加仍然是一个仿射变换。解决问题的一个方法是引入非线性变换,例如对隐藏变量使用按元素运算的非线性函数进行变换,然后再作为下一个全连接层的输入。这个非线性函数被称为激活函数(activation function)。
ReLU激活函数:
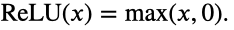
ReLU函数只保留正数元素,并将负数元素清零
图像:

导数图像:

Sigmoid函数:
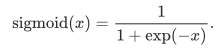
sigmoid函数可以将元素的值变换到0和1之间:
图像:

求导公式:
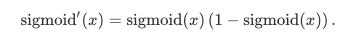
导数图像:

当输入为0时,sigmoid函数的导数达到最大值0.25;当输入越偏离0时,sigmoid函数的导数越接近0。
tanh函数
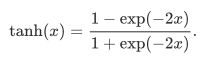
tanh(双曲正切)函数可以将元素的值变换到-1和1之间。
图像:

当输入接近0时,tanh函数接近线性变换。虽然该函数的形状和sigmoid函数的形状很像,但tanh函数在坐标系的原点上对称。
导数图像:

导数公式:
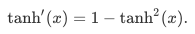
当输入为0时,tanh函数的导数达到最大值1;当输入越偏离0时,tanh函数的导数越接近0。
激活函数的选择
ReLu函数是一个通用的激活函数,目前在大多数情况下使用。但是,ReLU函数只能在隐藏层中使用。
用于分类器时,sigmoid函数及其组合通常效果更好。由于梯度消失问题,有时要避免使用sigmoid和tanh函数。
在神经网络层数较多的时候,最好使用ReLu函数,ReLu函数比较简单计算量少,而sigmoid和tanh函数计算量大很多。
在选择激活函数的时候可以先选用ReLu函数如果效果不理想可以尝试其他激活函数
4.习题理解:



