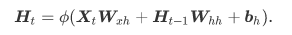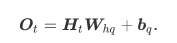线性回归
模型
price=warea⋅area+wage⋅age+b
数据集
我们通常收集一系列的真实数据,例如多栋房屋的真实售出价格和它们对应的面积和房龄。我们希望在这个数据上面寻找模型参数来使模型的预测价格与真实价格的误差最小。在机器学习术语里,该数据集被称为训练数据集(training data set)或训练集(training set),一栋房屋被称为一个样本(sample),其真实售出价格叫作标签(label),用来预测标签的两个因素叫作特征(feature)。特征用来表征样本的特点。
损失函数

优化函数 - 随机梯度下降

Softmax与分类模型
分类问题
一个简单的图像分类问题,输入图像的高和宽均为2像素,色彩为灰度。
图像中的4像素分别记为 x1,x2,x3,x4 。
假设真实标签为狗、猫或者鸡,这些标签对应的离散值为 y1,y2,y3 。
我们通常使用离散的数值来表示类别,例如 y1=1,y2=2,y3=3 。
权重矢量
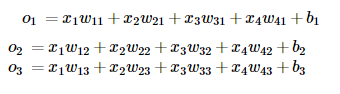
输出问题
直接使用输出层的输出有两个问题:
一方面,由于输出层的输出值的范围不确定,我们难以直观上判断这些值的意义。例如,刚才举的例子中的输出值10表示“很置信”图像类别为猫,因为该输出值是其他两类的输出值的100倍。但如果 o1=o3=103 ,那么输出值10却又表示图像类别为猫的概率很低。
另一方面,由于真实标签是离散值,这些离散值与不确定范围的输出值之间的误差难以衡量。
softmax运算符(softmax operator)解决了以上两个问题。它通过下式将输出值变换成值为正且和为1的概率分布:
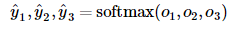
小批量矢量计算表达式
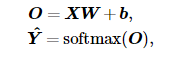
交叉熵损失函数
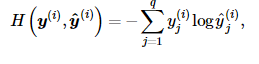
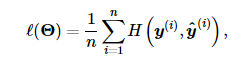
多层感知机
隐藏层
下图展示了一个多层感知机的神经网络图,它含有一个隐藏层,该层中有5个隐藏单元。

表达公式
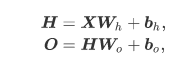
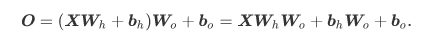
激活函数
ReLU函数
ReLU(rectified linear unit)函数提供了一个很简单的非线性变换。给定元素 x ,该函数定义为
ReLU(x)=max(x,0).

Sigmoid函数
sigmoid函数可以将元素的值变换到0和1之间:
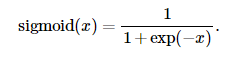

tanh函数
tanh(双曲正切)函数可以将元素的值变换到-1和1之间:

文本预处理
文本是一类序列数据,一篇文章可以看作是字符或单词的序列,本节将介绍文本数据的常见预处理步骤,预处理通常包括四个步骤:
1、读入文本
2、分词
3、建立字典,将每个词映射到一个唯一的索引(index)
4、将文本从词的序列转换为索引的序列,方便输入模型
语言模型
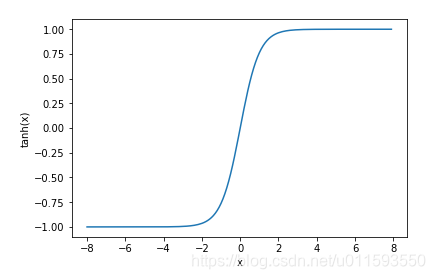
一段自然语言文本可以看作是一个离散时间序列,给定一个长度为 T 的词的序列 w1,w2,…,wT ,语言模型的目标就是评估该序列是否合理,即计算该序列的概率:
P(w1,w2,…,wT).

假设序列 w1,w2,…,wT 中的每个词是依次生成的,我们有
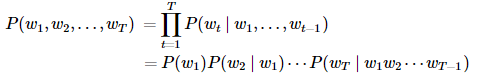
语言模型的参数就是词的概率以及给定前几个词情况下的条件概率。设训练数据集为一个大型文本语料库,如维基百科的所有条目,词的概率可以通过该词在训练数据集中的相对词频来计算,例如, w1 的概率可以计算为:
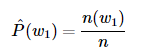
其中 n(w1) 为语料库中以 w1 作为第一个词的文本的数量, n 为语料库中文本的总数量。
类似的,给定 w1 情况下, w2 的条件概率可以计算为

其中 n(w1,w2) 为语料库中以 w1 作为第一个词, w2 作为第二个词的文本的数量。
n元语法
序列长度增加,计算和存储多个词共同出现的概率的复杂度会呈指数级增加。 n 元语法通过马尔可夫假设简化模型,马尔科夫假设是指一个词的出现只与前面 n 个词相关,即 n 阶马尔可夫链(Markov chain of order n ),如果 n=1 ,那么有 P(w3∣w1,w2)=P(w3∣w2) 。基于 n−1 阶马尔可夫链,我们可以将语言模型改写为
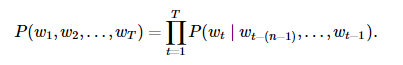
以上也叫 n 元语法( n -grams),它是基于 n−1 阶马尔可夫链的概率语言模型。例如,当 n=2 时,含有4个词的文本序列的概率就可以改写为:
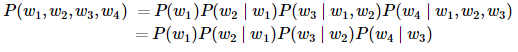
当 n 分别为1、2和3时,我们将其分别称作一元语法(unigram)、二元语法(bigram)和三元语法(trigram)。例如,长度为4的序列 w1,w2,w3,w4 在一元语法、二元语法和三元语法中的概率分别为
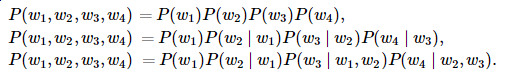
当 n 较小时, n 元语法往往并不准确。例如,在一元语法中,由三个词组成的句子“你走先”和“你先走”的概率是一样的。然而,当 n 较大时, n 元语法需要计算并存储大量的词频和多词相邻频率。
循环神经网络

循环神经网络的构造