论文解读:(TranSparse)Knowledge Graph Completion with Adaptive Sparse Transfer Matrix
先前的基于深度学习的知识表示模型TransE、TransH、TransR(CTransR)和TransD模型均一步步的改进了知识表示的方法,在完善知识图谱补全工作上逐渐提高效果。通过先前的模型,我们基本掌握了知识表示的学习方法:首先通过投影策略将实体和关系映射到对应的语义空间,其次均使用得分函数 表示实体对的评分。另外使用负采样生成错误样本进行训练,使得正确的样本得分函数值降低,错误样本的得分函数值升高。然而这些模型均忽略了图谱的两个重要特性:异质性(heterogeneity)和不平衡性(imbalance)。图谱中的异质性是指不同关系对应的实体对数量不一致,例如对于关系 链接的所有实体对数量可能非常多,而对于 链接的所有实体对数量可能只有1个。不平衡性是指头尾实体的数量不一致,例如形如对于(地名,local,洲名)的三元组,地名可能成千上万个,而洲名只有七个。由于数量的不对等,可知数量较多的对应关系的实体对或头尾实体,它们所包含的信息应该越多,而前面的几种模型忽略了这一点,使得针对每个实体对都用同样的方法训练,势必会导致数量多的部分出现欠拟合,数量少的部分出现过拟合。因此本文TranSparse试图改进这一点。
一、简要信息
| 序号 | 属性 | 值 |
|---|---|---|
| 1 | 模型名称 | TransSparse |
| 2 | 所属领域 | 自然语言处理 |
| 3 | 研究内容 | 知识表示 |
| 4 | 核心内容 | knowledge embedding |
| 5 | GitHub源码 | https://github.com/thunlp/KB2E |
| 6 | 论文PDF | http://www.xuebalib.com/cloud/literature-3tdsSjKHNBQi.html |
二、摘要与引言
我们构建完整的知识图谱通过对每个实体和关系进行表征到连续空间中。所有先前的工作包括TransE、TransH、TransR(CTransR)和TransD忽略了异质性(一些关系链接了大量的实体对,而另一些则链接少数的实体对)和非平衡性(相同关系的所有实体对中,头尾实体的数量不相同)。本文我们提出一个新的方法叫TranSparse来解决这两个问题。在TranSparse中,变换矩阵被替换为动态稀疏矩阵,稀疏因子由指定关系的实体或实体对的数量所决定。实验中,我们设计了结构化和非结构化稀疏模式的变换矩阵,并分析他们的优劣性。我们在三元组分类和链接预测两个任务上评估了我们的方法,实验结果表明TranSparse比之前的方法效果好。
知识图谱是由结点和结点之间相连的边组成,我们定义图谱中结点与边组成的元素为三元组,定义为
,分别为头实体、关系和尾实体。虽然当前的图谱包含大量的三元组,但仍然是完整的。最近知识表示通过将实体和关系嵌入到连续的空间中来表示图谱成为主流的方法。现有的两种策略分别是基于张量分解(例如RESCAL)和神经网络模型(例如TransE/H/R/D)。然而这些方法均忽略了图谱的异质性和不平衡性。异质性可能导致过拟合或欠拟合,不平衡性可能导致训练的不平等。
本文处理这种问题的策略是引用稀疏矩阵。首先对于异质性,提出TranSparse(Share),稀疏因子取决于关系链接对应的实体对数量,且两个实体对应的关系投影矩阵是相同的。对于不平衡性,提出TranSparse(Separate),每个关系对应的实体对中,头尾实体使用不同的关系投影矩阵。
三、相关工作与主要贡献
相关工作。略,图为相关模型的参数复杂度:

本文的主要贡献:
(1)我们提出一种新的模型考虑异质性和不平衡性;
(2)我们的方法是有效的,且含有少量的参数;
(3)我们提出了两种稀疏模式,并分析优劣;
(4)在三元组分类和链接预测任务上达到了最优效果。
四、算法模型详解(TranSparse)
4.1 稀疏矩阵
稀疏矩阵是指一个矩阵中含有大量的0元素,而0元素所占总元素个数的比值为稀疏因子
。稀疏因子
越大表示这个矩阵越稀疏。用
表示稀疏因子为
的矩阵。对于稀疏矩阵有两种结构,如图所示:
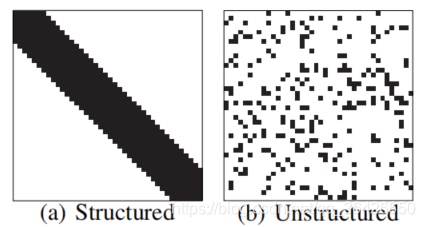
黑色表示非0元素,白色表示0元素。图(a)表示结构化的稀疏矩阵,可知所有非0元素沿着主对角线排列,因此可知对于
的对角矩阵的稀疏因子为
。图(b)中表示非结构稀疏矩阵,0元素是随机排布。
4.2 为什么选择稀疏矩阵,而不是低秩矩阵?
自由度是衡量一个矩阵中相互独立的元素个数,而稀疏矩阵和低秩矩阵均可以在一定程度上降低自由度(稀疏矩阵包含大量的0,而低秩矩阵对应的梯形矩阵包含大量的0,0的个数越多,则非0的相互独立的元素个数变少)。对于低秩矩阵,由于许多变量之间存在线性约束条件(可回顾线性方程组和线性相关的概念),因此秩越低,自由度就越低。对于稀疏矩阵,由于含有非0元素数量少,所以在训练过程中让0元素保持不变,因此可变的元素就很少,亦即自由的变量很少。之所以引入自由度的概念,是因为对于一个矩阵,如果自由度越低,即包含有效的信息量就越少,对解决异质性和非平衡性很有效。
对于低秩矩阵,矩阵的秩的大小不大于该矩阵最小的维度数,而自由度也仅局限于一小范围内。具体地说,如果矩阵
,秩
,自由度也在
之间,因为矩阵的秩主要用于衡量行向量或列向量的线性最大无关组的数量,因此其可以控制大量的元素,不易于控制。如果使用稀疏矩阵,我们知道非0元素的个数即为自由元素的个数,因此其可以控制唯一的元素,使得自由度范围更大,亦即能够大范围的表示不同复杂度的图。稀疏矩阵中仅有非0元素参与运算,这比低秩矩阵更有效,因此选择稀疏矩阵来控制投影的复杂度。
4.3 TranSparse模型
先前的模型中,不论关系对应的实体或实体对数量多少,训练的参数是相同的,因此可能导致数量少的实体或实体对训练过拟合,数量多的实体或实体对训练欠拟合,因此需要考虑参数与实体对数量的关系。在TranSparse(Share)中。设
表示关系
链接的实体对数量,
表示其中最大值,
表示对应的关系。设
表示矩阵
的稀疏因子,则
。通过此公式可知取最大实体对数量为基数,其他实体对数量与之比值作为相对复杂度。该公式可计算对应关系投影矩阵的稀疏因子。其次可将头尾实体分别映射到关系空间中:
,
。
TranSparse(Separate)与Share不同,头尾实体分别映射到不同的关系空间中。
表示“头实体-关系”映射矩阵
和 “尾实体-关系”映射矩阵
。对于关系
,最大数量头尾实体
和
分别对应的数量
,
。因此“头实体-关系”映射矩阵的稀疏因子为
,
。因此头尾实体分别映射到关系空间中:
,
。
最后得分函数则为:
。
4.4 训练目标
由于图谱中都为真实的三元组,因此需要进行负采样。这一部分与TransH相同。损失函数为:
4.5 实现细节
TranSparse模型通过控制投影矩阵的自由度(稀疏因子)来对不同数量的实体或实体对进行训练。数量越多的实体对对应的关系投影矩阵的参数越多。具体的实现细节如下:
(1)首先使用TransE进行预训练,得到对应的向量;
(2)根据稀疏因子
初始化两种稀疏矩阵,分别是结构化矩阵和非结构化矩阵。结构化矩阵沿着主对角线的两侧,如果数量达不到对应的结构化模式,可以适当小范围内调整参数个数。非结构化矩阵则是随机生成。
(3)在训练过程中指更新非0元素。
算法如图所示:

五、实验及分析
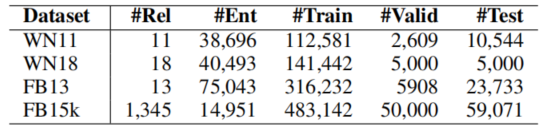
本节,实验主要包括三元组分类和链接预测。数据集为WordNet的子集WN11和WN18,FreeBase的子集FB15k和FB13,实验数据集的统计信息如图所以:
三元组分类:三元组旨在对给定三元组的正确与否进行分类。实验表明我们的方法达到最优。分析:(1)相比先前的工作,我们的模型能够很好的处理异质性和不平衡性。(2)Separate比Share效果好;(3)非结构化比结构化效果好。
链接预测:链接预测旨在预测未知的头实体或尾实体,评价标准则为
。实验表明:(1)我们的模型效果达到最优;(2)对于一对多、多对一和多对多的关系模式依然有效;(3)非结构化稀疏矩阵效果最好。
六、论文总结与评价
本文我们提出一种TranSparse模型用于补全知识图谱,考虑先前工作忽略了异质性和不平衡性,我们引入了稀疏变换矩阵。实验表明我们的模型能够达到最优。在未来工作,我们将探究最优的稀疏模式用于投影矩阵。
