论文地址:https://www.aaai.org/Papers/AAAI/2020GB/AAAI-LiW.3470.pdf
github地址:https://liweileev.github.io/FET-GAN/
Motivation
本文提出针对few-shot的自适应实例归一化的字体风格迁移。即要解决的问题为在只有少量新的字体样本的情况下如何将现有风格的字体转换为新的字体样式,并且保持字不变。为此,作者提出了FET-GAN,端到端的学习框架。此外,作者也构建了一个字体数据库,包含了中文与英文两种字符集。
Methods
FET-GAN的框架图如下图所示。

该框架由编码器E,生成器G,判决器D组成。待转换的字体风格为源域数据,而目标字体分格为目标域数据,编码器E分别将源域和目标域中的样本下采样映射到特征子空间中,经过自适应实例归一化后分别取平均得到各自的特征表示。E的学习采用few-shot的方式,即只有K个目标域样本。
之后将特征表示与源域样本一起输入到生成器G中。生成器根据E所传入的特征表示生成一张图像,该图像中文本内容与输入图像保持一致,同时字体风格为特征表示对应的字体风格。根据特征表示的不同,可将生成图像分为重建图像Reconstructed Image和迁移图像Transfered Image。
为了生成样本的多样性,作者提出C分类判决器,其中C为风格种类数。这样使得网络可以处理多域的迁移学习。判决器的结构如下图所示。在实际训练中,每次只计算输入所在类别的通道上的损失函数。

在目标函数的设计上,作者使用了4种loss。
首先,编码一致性损失函数,旨在约束编码器对相似的样本生成相似的特征表示。
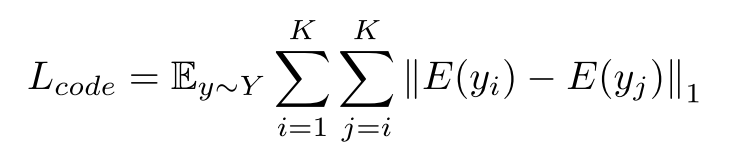
其次,迁移损失,旨在使得通过特征表示生成的目标域字体与真实的目标域字体尽可能接近。

第三,,重建损失,旨在通过特征表示生成的源域字体与真实的源域字体尽可能接近,即与输入的字体图像接近。
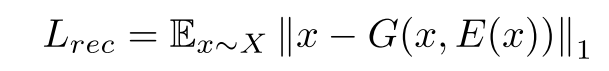
第四,对抗损失。对于源域字体和重建的源域字体,对抗loss如下所示。其中作者采用hinge形式的对抗损失,在输入为真实样本时在loss中加入对梯度的惩罚正则项以保证收敛和稳定。类似地,对于目标域字体和迁移所得目标域字体,对抗loss如下。


因此整体的目标函数即为:

对于unseen的字体风格迁移,作者提出一种微调的方式,这种方式只需要少量甚至一个新的字体样本。对于新的字体样本,首先通过数据增强得到一个临时的小数据集。在构建好数据集后,使用预训练参数初始化模型,并进行微调。由于新的字体不在原本的类别集中,因此在判决器D的输出中新增一个通道。该通道的初始化参数通过在原来的通道中选择一个通道的参数作为其初始化参数:随机选择一个batch的新类别样本输入到预训练后的判决器中,选择预测值最大的通道。
在微调阶段,源域数据和目标域数据应为同一个域中的样本,即临时的数据集的样本。

Experiments
数据集:Fonts-100,部分样本如下图所示
K-shot:训练时使用4-shot,测试时使用1-shot

Results


Thoughts
这篇的框架我觉得是adversarial few-shot learning的一个比较典型的框架,可以尝试在其他任务中。具体的尝试方案已在前几日做过讨论,形成了一个初步的方案。