简述
看这篇论文,并实现一下这个。(如果有能力实现的话)
实时任意风格转换(用自适应Instance Normalization)
instanceNorm = batchsize=1 的 batchNorm 1
Abstract
Gatys et al. 最近介绍了一种神经网络算法,以另外一个图片的样式来呈现一个内容图片,实现了一个被称之为风格迁移的东西。然而,他们的框架需要慢慢的迭代优化过程,这限制了它的实际应用。(你敢信?我试了下这个框架,跑了一晚上才跑完1/20(虽然我是用cpu,但我的cpu也有16个核啊…))用了前向传播神经网络的方法被提出来了,去加速神经风格转换。但不幸的是,这样的速度提升是有代价的:这样的网络往往都被绑定在一个固定的风格当中,不能应用在任意一个新的风格上。在这篇论文当中,我们提出一个简单,但是有效的方法使得,第一个能够实时地进行任意风格转换。在我们方法的核心,是一个新奇的自适应实例正则化层(AdaIN),来使得内容特征的均值和方差与风格特征的均值和方差对齐。(看到这,我其实完全不知道这个论文在写什么了…但是有点不明觉厉的感觉…)我们的方法的速度跟最快的方法可以媲美,但是却对数据集没有限制。此外,我们的方法允许灵活的用户进行一些操控,比如,内容和风格权衡,风格插值,色彩和空间的控制,所有的这一切,都是用一个前向传播的神经网络实现。

Introduction
Gatys et al.的基础工作表示,深度神经网络不仅可以编码内容信息,也可以编码一张图片的风格信息。此外,图片的风格和内容居然是可以分隔的,这使得可能去改变一张图片的风格同时还保留它的内容。这个风格转换的方法足够灵活去将内容和任意一张图片的风格组合在一起。然而,它依赖于一个非常缓慢的过程优化过程。
在提高速度上已经有了非常有意义的贡献了,尝试去训练一个前向传播的神经网络,结果表现出风格上的相近。关于绝大多数前向传播网络来说,一个最大的限制,就是每个网络被单个的风格给限制住了。这有了一些算法来解决了这个问题,但是他们任然被一些有限的风格给限制住了,又或者速度比单个风格的要慢很多。
在这个工作当中,我们解决了这个神经网络的风格转换上的这个基本的灵活度和速度的两难的问题。我们的方法可以实时地转换任意的新风格,同时保证了优化框架的灵活性和速度上接近最快的前馈神经网络。我们的方法是被IN(Instance normalization)层给启发的,这个在风格转换上有很令人惊讶的效果。为了解释这个instance normalization的成功,我们提出了一个新的
展示(instance normalization通过正则化图片特征统计)。被这个效果给刺激到了,我们做了点改进提出了自适应的instance normalization(AdaIN).给了一个内容的输入和一个效果的输入,AdaIN简单地调整内容图片的均值和方差,去匹配风格图片。通过实验,我们发现AdaIN有效地通过调整特征统计量,来保证内容和风格。一个解码的神经网络,是学会去生成一个最后的风格话的图片,通过倒置这个AdaIN的输出到原来的图片空间。我们的方法接近快三个量级,而且还没有牺牲灵活性(可以使用任意的风格)。此外,我们的方法提供了丰富的用户控制,还不用修改训练的过程。


【PS】:看完这个,我只能说这个论文我只能说这个也太强了吧…怪不得发到了cvpr
Backgroud
和往常一样,这里我也不会看related worked.主要是我现在水平不够,看也看不太懂。在这个领域我也只看过这个风格转换的第一个论文的一个简单的解析。
Batch Normalization
Ioffe和Szegedy初始的工作,介绍了一个batch normalization层,通过正则化特征统计量,可以明显地使得前网络的训练的过程变得简单了。
BN一开始是被设计是为了给训练判别式网络进行提速的。但是发现在图像生成的模型上也挺有效的。 给一个输入
,(这个表达在pytorch上很常见(后来发现这个是用torch实现的,算是同源吧(torch用的是lua))),BN 正则了这个均值和标准差给每一个单独的特征通道。
其中那两个额外的参数就是放射参数(可以理解为线性映射),这两个参数是从数据中学习到的。
注意,这里是关于通道C进行遍历的

所以其实还是非常好理解的。
Instance Normalization
和BN的区别就是不是在BATCH的,也就是说这里不使用这个N个维度的数据,而是把N和C一起考虑。很明显这样会增加更多的变量,也就考虑的更细致了。
就是说在计算在均值和方差的时候多考虑下N这个变量
所以,计算出来的均值和方差是有N*C个
Conditional Instance Normalization
这个就是在IN的基础上,加了一个状态的说法。然后构造出在不同的状态下的instance normalization
Adaptive Instance Normalization
如果说IN,就是把输入正则化到一个风格(用仿射的参数来区分),这有可能去应用到任意给的一个风格上么?这里,我们提出一个在IN上的改进(Adaptive Instance Normalization)
AdaIN 收到内容的输入和风格的输入,分别标记为x和y。
不像BN,IN和CIN,AdaIN没有可以学习的仿射参数。而是,这里适应性计算这个映射参数。
然后,我们这里只是简单的使用标准值来作为scale参数,然后均值作为偏置参数。(看到这简直忍不住叫好!太秀了吧!)

Experimental Setup
论文中说把代码放到了github上了。但是是用torch写的,所以语言是lua,真的没学过这个哇…看不太懂…
whatever,还是先看文章吧,如果能把实验部分看懂了,估计也是可以实现的吧??
Architecture
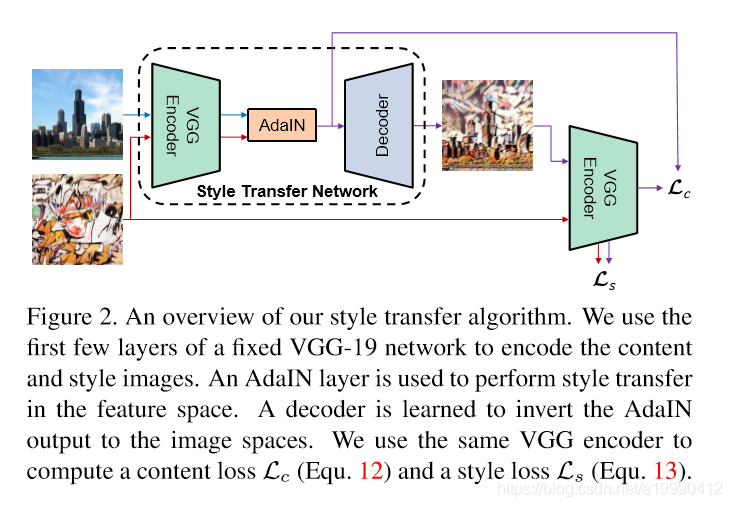
我们的风格转换网络T获取一个内容图片 ,并且任意的一张风格图片s作为输入,并且合成一张图片(内容图的内容,并且也有风格图的风格的)。我们采用一个简单的encode-decode,编码器 是被放在了先训练好的VGG-19的前几层(在relu4_1之前的). 在编码器之后,内容图和风格图都被放在了特征空间中。我们同时培养特征映射到AdaIN层,标定内容特征的均值和方差到对应的风格特征上,产生目标图片
一个随机的初始化的解码器g被训练去映射t到图片空间。
生成有了风格的图片T(c,s)
Training
(关键过程):
- 使用adam optimizer
- a batch size of 8 content-style image pairs.
- 先resize每个图片的最小的维度到512,在保留图片的比例的情况下,随机裁剪到256*256
- 使用VGG-19去计算损失函数去训练decoder
- 分别对应内容上的损失和在风格上的损失。才加一个风格的损失权重。
- 内容上的损失使用的是 Euclidean distance(欧氏距离),用AdaIN来生成t作为内容的目标。
- 风格上,这里就不使用Gram矩阵,而是使用AdaIN的均值和方差这些统计量了。
- 风格上使用了VGG,然后relu1 1, relu2 1, relu3 1, relu4 1用这些层。这些层的结果的损失和作为风格上的损失,而不是算Gram矩阵。
1 ↩︎