本次分享一篇来自APNet2015的论文《Knowledge Base Completion Using Matrix Factorization》。
传统的知识库补全方法推理信息不足,忽略了隐含在各种知识库中的知识互补性,于是本文提出了跨知识库的补全。 本文提出了一种新的知识库补全矩阵分解模型,该模型综合了不同知识库中不同关系的相似信息。
1.由知识库转换为矩阵:
从各种知识库(由m个谓词和n个实体对组成)生成矩阵X很简单:矩阵中的每行对应一个关系r,每列对应一个实体对e。每个矩阵单元用Xer表示,矩阵的大小是m×n。当 (esubject,r ,eobject) ∈ F为真时,我们可以将知识库矩阵Xer的每个单元变量初始化为1。
2.矩阵分解
矩阵分解可以将原始矩阵表示成新的易于处理的形式,这种形式是两个或多个小矩阵的乘积。在实际计算时不再使用大矩阵,而是使用分解得到的多个小矩阵,即Xmxn=UTlxmVlxn
传统上,矩阵因式分解方法通过最小化以下各项来近似矩阵X:
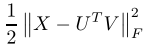
在传统方法上进行改进得到下式:
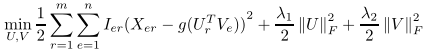
Ier是指示函数。g(X)=1/(1+e−x)
为了避免过拟合,增加了U和V的范数作为正则项,λ1,λ2>0作为正则参数。
3.不同知识库补全
在矩阵分解 (matrix factorization) 的基础上提出对不同知识库进行知识库补全,该方法将三元组中的关系描述为谓词, 而谓词对主体和客体都有类型要求,比如谓词 BirthIn 就会要求主体是人, 客体是地理位置或名称,如果不满足类型要求就说明该谓词无法正确联系主客体。此处等同于增加了谓词的类别约束。尽管知识库在构建时无法做到从定义到实现的完全一致,但是它们都会遵从三元组和知识模型的基本框架,因此可以比较容易地得到谓词的类别描述和谓词的特征,从而对不同知识库中的谓词相似性进行判断,以下公式用来衡量谓词的相似性:
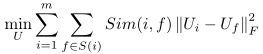
其中 S(i) 表示与谓词 ri 相似的谓词集合,Ui 和Uj 是这两个谓词在特征空间的潜在特征表示,Sim(i, f) 是用来描述谓词 ri 和谓词 rf 之间的相似度函数,定义如下:(有关余弦相似度的详细介绍:https://www.cnblogs.com/airnew/p/9563703.html)
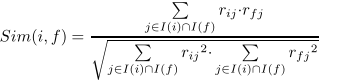
其中j是属于谓词ri 和谓词rf 两者都相关的项的子集,rij 是实体对j与谓词ri匹配的概率。从上述定义可以看出,Sim(i,f)中的VSS相似度在[0,1]范围内,值越大,则谓词ri 和rf 越相似。其总体目标函数定义如下:
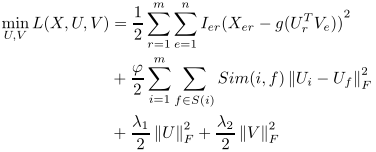
其中的 φ 是相似性度量的权重。
该方法在衡量相似谓词后可以发现相似谓词在不同知识库中的不同三元组,从而在类别约束下发现丢失的知识,即不存在的三元组。最终该方法在知识库 DBpedia3.9 和 YAGO-2s 上进行了测试并取得了较好的效果。