与DP不同的是,我们不需要完全知道环境的模型,MC只需要experience,就是模拟出来的一个个数据。Monte Carlo方法是求所有episodes的returns均值,因此是episode-by-episode场景。
1.Monte Carlo Prediction
First-visit Monte Carlo方法的Policy Evaluation是将无数个episode观察到的第一个状态s之后累积的returns进行平均,直到收敛到期望值。

DP的backup diagram展示了所有可能的后继状态,而MC只有被sample到的episode;DP只包括一步转移,而MC是一直走到episode的结束。简单来说,DP对当前状态函数值的估计要建立在后继的状态值上面,而MC的各个状态都是相互独立的-------DP需要bootstrap,而MC不需要。

2.Monte Carlo Control
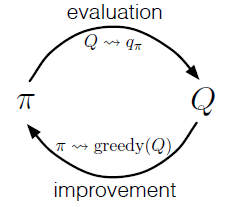
在这里我们有两个假设,一个是episode有探索性的开始,而是通过无穷的episode,policy evaluation可以完成。针对第二个假设,有两种解决方法。
1. 假设theta,当 小于theta的时候,我们可以保证收敛;2.不等到policy evaluation完成之后,再进行提升,而是使用value iteraion的方法,每一次迭代,都提升一次。
小于theta的时候,我们可以保证收敛;2.不等到policy evaluation完成之后,再进行提升,而是使用value iteraion的方法,每一次迭代,都提升一次。
因为,MC方法要等到episode结束后,才能进行Policy evaluation 和 Policy improvement;但是有的场景下一个episode要经历很长时间,或者说就没有终止的时候,所以,这也是MC的不好之处。另外,因为MC是对sample到episodes的reuturns进行取平均求估计,这就会导致一些出现过的场景在其他地方不能直接进行利用,适用性不强。
3.去除Exploring Starts
这个是对2.中的另外一个假设的解释,当系统内没有Exploring Starts的时候,有些action可能不会被选择到,那么评估Q(s,a)的时候就会出现错误。
解决的办法就是采用epsilon-greedy的policy,这样的话,即使是没有Exploring Starts,也会有epsilon的概率能够选择到其他的动作,这样可以解决一直选择最大Q(s,a)的动作(可能不是最优)问题。
4.Off-policy Prediction via Importance Sampling
前面介绍的policy,因为它最终得到的最有policy是epsilon-greedy poliy,仍然不是最好的greedy policy。如果我们想得到最优的greedy policy,就需要off-policy。使用off-policy需要evaluation和improvement不是同一个policy,那么就要借助于importance sampling将evaluation policy里sample出来的data转化为improvement policy的data。简单来说,需要两个policy,一个是target policy(learn),一个是behaviou policy(data)。
4.1 weighted improtance sampling 和 ordinary sampling
这里又分为两种importance sampling,一种是ordinary sampling,一种是weighted improtance sampling。
区别是:weighted是有偏差,低方差;ordinary 是 无偏差,高方差。实践中,更喜欢用weighted 的方法。
5. off-policy MC control
总的来说,就是使用behaviour policy的data根据Q(s,a)采用greedy得到optimal policy π。这里要注意的是,b的policy 要包含 π,即π里面的选择的动作,b也能选到。

6.总结
1.MC对于DP来说的3个优点
(1)不需要环境model
(2)可以使用模拟或者sample model
(3)对于一部分数据,我们可以只分析其中有用部分的数据,使用MC方法,很有效率。
2.MC的问题
由于需要Exploring Starts ,所以,当去掉这个假设之后,很可能只会选择当前sample到的action,那么更好的action可能就会永远也选不到。所以,on-policy MC得到的最优policy 是epsilon-greedy policy。