一、聚类算法
1.概念:
聚类算法是一种典型的无监督学习算法,主要用于将相似的样本自动归到一个类别中。
在聚类算法中根据样本之间的相似性,将样本划分到不同的类别中,对于不同的相似度计算方法,会产生不同的聚类结果,常用的相似度计算方法有欧式距离。
2.聚类算法与分类算法最大的区别:
聚类算法是无监督学习,而分类算法是监督的学习算法。
3.聚类算法的分类
- 粗聚类
- 细聚类
4.聚类算法的API
-
sklearn.cluster.KMeans(n_clusters = 6)
- 参数:
- n_clusters:开始的聚类中心数量
- 整形,缺省值为6,生成的聚类树,其实就是产生的质心数
- n_clusters:开始的聚类中心数量
- 方法:
- estimator.fit_predict(x)
- 计算聚类中心并且预测每个样本属于哪个类别,相当于先调用fit(x)在调用predict(x)
- 参数:
4.1案例
随机创建不同二维数据集作为训练集,并结合k-means算法将其聚类,你可以尝试分别聚类不同数量的簇,并观察聚类效果:
import matplotlib.pyplot as plt
from sklearn.datasets.samples_generator import make_blobs
from sklearn.cluster import KMeans
from sklearn.metrics import calinski_harabaz_score
# 创建数据集
# X为样本特征,Y为样本簇类别, 共1000个样本,每个样本4个特征,共4个簇,
# 簇中心在[-1,-1], [0,0],[1,1], [2,2], 簇方差分别为[0.4, 0.2, 0.2, 0.2]
X,y = make_blobs(n_samples=1000,n_features=2,centers=[[-1,-1],[0,0],[1,1],[2,2]],cluster_std=[0.4,0.2,0.2,0.2],random_state=22)
# 数据可视化
plt.scatter(X[:,0],X[:,1],marker='o')
plt.show()
# 使用k-means进行聚类,并使用CH方法评估
y_predict = KMeans(n_clusters=2,random_state=22).fit_predict(X)
# 分别尝试n_cluses=2\3\4,然后查看聚类效果
plt.scatter(X[:,0],X[:,1],c=y_predict)
plt.show()
# 用Calinski-Harabasz Index评估的聚类分数
print(calinski_harabaz_scare(X,y_predict))
5.聚类算法实现流程
- k-means 其实包含两层内容:
- k:初始中心个数
- means:求中心点到其他数据点距离的平均值
1)K-means聚类步骤
- 1.随机设置k个点为初始的聚类中心
- 2.对于其他每个点都计算到k个中心的距离,将离中心最近的一些点划分为一个簇
- 3.然后重新计算出每个簇的新中心点
- 4.直到新的中心点与原中心点一样(质心不在移动),结束。否则重复执行2.3步。
缺点:
- 由于每次都要计算所有样本与每一个质心之间的相似度,所以在大规模的数据集上,k-means算法的收敛速度比较慢。
6.模型评估指标
1)误差平方和(SSE)
该统计参数计算的是拟合数据和原始数据对应点的误差的平方和,计算公式如下
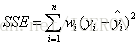
SSE越接近于0,说明模型选择和拟合更好,数据预测也越成功。
2)“肘”方法—K值确定
下降率突然变缓时即认为是最佳的k值。

3)轮廓系数法(SC)
结合了聚类的凝聚度和分离度,用于评估聚类的效果。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-AVPfIrua-1579076067973)(file:///C:/Users/%E6%B8%85%E9%A3%8E/Desktop/%E6%9C%BA%E5%99%A8%E5%AD%A6%E4%B9%A0%E8%AF%BE%E4%BB%B6/%E6%9C%BA%E5%99%A8%E5%AD%A6%E4%B9%A0%E8%AE%B2%E4%B9%89/%E6%9C%BA%E5%99%A8%E5%AD%A6%E4%B9%A0%EF%BC%88%E7%AE%97%E6%B3%95%E7%AF%87%EF%BC%89/%E8%81%9A%E7%B1%BB%E7%AE%97%E6%B3%95/images/sc.png)]](https://img-blog.csdnimg.cn/20200115161619641.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L1dhbmdUYW9UYW9f,size_16,color_FFFFFF,t_70)
目的:就是内部距离最小化,外部距离最大化。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-FubrSi5r-1579076067975)(file:///C:/Users/%E6%B8%85%E9%A3%8E/Desktop/%E6%9C%BA%E5%99%A8%E5%AD%A6%E4%B9%A0%E8%AF%BE%E4%BB%B6/%E6%9C%BA%E5%99%A8%E5%AD%A6%E4%B9%A0%E8%AE%B2%E4%B9%89/%E6%9C%BA%E5%99%A8%E5%AD%A6%E4%B9%A0%EF%BC%88%E7%AE%97%E6%B3%95%E7%AF%87%EF%BC%89/%E8%81%9A%E7%B1%BB%E7%AE%97%E6%B3%95/images/sc1.png)]](https://img-blog.csdnimg.cn/20200115161636549.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L1dhbmdUYW9UYW9f,size_16,color_FFFFFF,t_70)
计算样本i到同簇其他样本的平均距离ai,ai 越小样本i的簇内不相似度越小,说明样本i越应该被聚类到该簇。
计算样本i到最近簇Cj 的所有样本的平均距离bij,称样本i与最近簇Cj 的不相似度,定义为样本i的簇间不相似度:bi =min{bi1, bi2, …, bik},bi越大,说明样本i越不属于其他簇。
求出所有样本的轮廓系数后再求平均值就得到了平均轮廓系数。
平均轮廓系数的取值范围为[-1,1],系数越大,聚类效果越好。
簇内样本的距离越近,簇间样本距离越远
4)CH系数(CH)
Calinski-Harabasz:
类别内部数据的协方差越小越好,类别之间的协方差越大越好(换句话说:类别内部数据的距离平方和越小越好,类别之间的距离平方和越大越好),
这样的Calinski-Harabasz分数s会高,分数s高则聚类效果越好。
Calinski-Harabasz:
类别内部数据的协方差越小越好,类别之间的协方差越大越好(换句话说:类别内部数据的距离平方和越小越好,类别之间的距离平方和越大越好),
这样的Calinski-Harabasz分数s会高,分数s高则聚类效果越好。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-9Mgw9ghA-1579076067975)(file:///C:/Users/%E6%B8%85%E9%A3%8E/Desktop/%E6%9C%BA%E5%99%A8%E5%AD%A6%E4%B9%A0%E8%AF%BE%E4%BB%B6/%E6%9C%BA%E5%99%A8%E5%AD%A6%E4%B9%A0%E8%AE%B2%E4%B9%89/%E6%9C%BA%E5%99%A8%E5%AD%A6%E4%B9%A0%EF%BC%88%E7%AE%97%E6%B3%95%E7%AF%87%EF%BC%89/%E8%81%9A%E7%B1%BB%E7%AE%97%E6%B3%95/images/ch1.png)]](https://img-blog.csdnimg.cn/20200115161654885.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L1dhbmdUYW9UYW9f,size_16,color_FFFFFF,t_70)
tr为矩阵的迹, Bk为类别之间的协方差矩阵,Wk为类别内部数据的协方差矩阵;
m为训练集样本数,k为类别数。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-aPaFKUGk-1579076067976)(file:///C:/Users/%E6%B8%85%E9%A3%8E/Desktop/%E6%9C%BA%E5%99%A8%E5%AD%A6%E4%B9%A0%E8%AF%BE%E4%BB%B6/%E6%9C%BA%E5%99%A8%E5%AD%A6%E4%B9%A0%E8%AE%B2%E4%B9%89/%E6%9C%BA%E5%99%A8%E5%AD%A6%E4%B9%A0%EF%BC%88%E7%AE%97%E6%B3%95%E7%AF%87%EF%BC%89/%E8%81%9A%E7%B1%BB%E7%AE%97%E6%B3%95/images/ch2.png)]](https://img-blog.csdnimg.cn/20200115161707745.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L1dhbmdUYW9UYW9f,size_16,color_FFFFFF,t_70)
使用矩阵的迹进行求解的理解:
矩阵的对角线可以表示一个物体的相似性
在机器学习里,主要为了获取数据的特征值,那么就是说,在任何一个矩阵计算出来之后,都可以简单化,只要获取矩阵的迹,就可以表示这一块数据的最重要的特征了,这样就可以把很多无关紧要的数据删除掉,达到简化数据,提高处理速度。
CH的目的:
用尽量少的类别聚类尽量多的样本,同时获得较好的聚类效果。
