- 聚类模型可以建立在无类标记的数据上,是一种无监督学习算法。 适合处理连续型数据,对于离散型数据效果不好
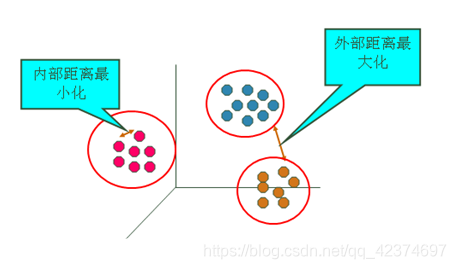
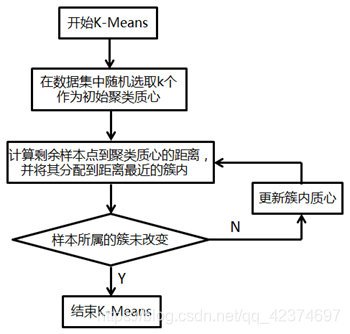

K-Means聚类算法中,
1)连续属性
对于连续属性,要先对各属性值进行标准化,再进行距离的计算。
一般需要度量样本之间的距离、样本与簇之间的距离以及簇与簇之间的距离。
- 度量样本之间的相似性最常用的是
- 欧几里得距离
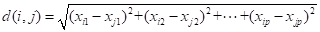
- 曼哈顿距离
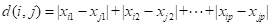
- 闵可夫斯距离
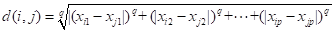
- 样本与簇之间的距离可以用样本到簇中心的距离 ;
- 簇与簇之间的距离可以用簇中心的距离。
- 簇 的聚类中心 计算公式为:
Python实现k-means聚类算法
import numpy as np
import pylab as pl
import random as rd
import imageio
import math
#1
#生成随机点列
x = np.random.randn(50)
y= np.random.randn(50)
#聚类个数
k_Cluster = 4
#迭代
iteration=0
frames = []
#2
#计算平面两点的欧氏距离
def distance(a, b):
return math.sqrt((a[0]- b[0]) ** 2 + (a[1] - b[1]) ** 2)
#3
#K均值算法
def k_means(x, y, k_Cluster):
#k_count为要聚类的个数,首先从n个数据对象任意选择 k 个对象作为初始聚类中心;
dot_count = len(x) #点的个数
#随机选择K个点
k = rd.sample(range(dot_count), k_Cluster) #K个对象作为初始的聚类中心
k_Initial = [[x[i], [y[i]]] for i in k] #保证有序(X,Y)
k_Initial.sort()
global frames
global iteration
while True:
#根据每个聚类对象的均值(中心对象),计算每个对象与这些中心对象的距离;并根据最小距离重新对相应对象进行划分;
Cluster_index = [[] for i in range(k_Cluster)] #存储每个簇的索引
#遍历所有点
for i in range(dot_count):
dot_all = [x[i], y[i]] #当前点
#计算dot_all点到所有质心的距离
Center_dt = [distance(k_Initial[j], dot_all) for j in range(k_Cluster)]
#dot_all点到那个质心最近
min_index = Center_dt.index(min(Center_dt))
#把dot_all点并入第i簇
Cluster_index[min_index].append(i)
#更换聚类中心
iteration+=1
k_new = []
for i in range(k_Cluster):
_x = sum([x[j] for j in Cluster_index[i]]) / len(Cluster_index[i])
_y = sum([y[j] for j in Cluster_index[i]]) / len(Cluster_index[i])
k_new.append([_x, _y]) #新的k个聚类对象
k_new.sort() #排序、保证有序
#使用Matplotlab画图
pl.rcParams['font.sans-serif']=['SimHei'] #用来正常显示中文标签
pl.rcParams['axes.unicode_minus']=False #用来正常显示负号
pl.figure() #画布
pl.title("点的个数=%d,聚类个数=%d 迭代次数:%d"%(dot_count,k_Cluster,iteration)) # 标题
color=['.r','.g','.b','.y']#颜色种类
dcolor=['*r','*g','*b','*y']#颜色种类
for j in range(k_Cluster):
pl.plot([x[i] for i in Cluster_index[j]], [y[i] for i in Cluster_index[j]], color[j%4])
pl.plot(k_Initial[j][0], k_Initial[j][1], dcolor[j%4])
pl.savefig("1.jpg")
frames.append(imageio.imread('1.jpg'))
if (k_new != k_Initial):#一直循环直到聚类中心没有变化
k_Initial = k_new
else:
return Cluster_index
Cluster_index = k_means(x, y, k_Cluster)#调用
imageio.mimsave('D:\\k-means.gif', frames, 'GIF', duration = 0.5)#生成gif动图
