0、前言
聚类是一种强大的非监督分类机器学习方法,其根据数据在特征空间中的邻近性挖掘数据背后隐藏的群体分布模式,因此被广泛应用于信息科学、生物学、地球学和经济学等领域。尽管已有不计其数的聚类方法被提出,但现实数据分布中普遍存在的密度异质和弱连接特性仍然给聚类分析带来巨大挑战,导致不同密度的类簇很难通过统一的聚类参数设置被完整识别,而存在弱连接的不同聚类簇容易被误合并,严重制约了聚类分析的精度与鲁棒性。论文《Clustering by measuring local direction centrality for data with heterogeneous density and weak connectivity》提出的局部方向中心性聚类算法CDC,通过度量每个点的K最近邻(KNN)分布均匀性来区分内部点和边界点。由于边界点能够形成封闭的笼子约束内部点的连接,从而防止跨簇连接,实现弱连接簇的有效分离,也避免了密度异质对类簇识别的影响。该研究在48个不同类型数据集上(单细胞RNA序列、质谱流式细胞、合成数据集、UCI数据集,人声语料库,人脸图像)将CDC与38种专业或通用基准算法进行了性能对比,结果表明CDC较主流聚类方法有更高的精度和参数鲁棒性。结论:CDC能够有效克服现实数据分布中普遍存在的密度异质和弱连接性问题,从而提升聚类的精度与稳定性,论文通过多类数据集上与基准算法的对比实验验证了算法具有较好的鲁棒性与数据适应性,因此具有巨大的潜在应用价值。
1、CDC算法理论
CDC背后的核心理念是通过度量每个点的K最近邻(KNN)分布均匀性,来区分边界点和内部点(公式1-2)。边界点勾勒出聚类的形状,并生成约束内部点的连接(公式3-4)。簇的内部点在各个方向上都有被相邻点包围的倾向,而边界点只包括一定方向范围内的相邻点(如图1b所示)。CDC算法实现流程图例如下(此图来源于论文):

a:jisuan每个点与其K最近邻(KNN)角度;
b:计算角度方差(局部的方向中心性度量),用来表征每个点的K最近邻(KNN)分布均匀性:即方差越小分布越均匀,即目标点的K最近邻(KNN)均匀分布在其四周,像包裹着目标点;方差越大分布越不均匀,即目标点的K最近邻(KNN)偏向于分布在单一方向上,无法被K最近邻(KNN)包围;
c:基于局部的方向中心性度量,设定阈值,划分边界点和内部点,其中边界点的DCM值大于阈值,内部点的DCM值小于阈值。如图c中蓝色点为边界点,红色点为内部点。
d:与图C同理,划分边界点和内部点(蓝色点为边界点,红色点为内部点)
e-f:边界点勾勒出聚类的形状,下一步是生成约束内部点的连接,即划分每个簇。具体方法是:计算边界点与每个内部点的最近距离
;计算内部点之间的距离
,如果
则内部点
和同簇,反之不同簇。
g:基于上述步骤可以进一步实现图c中不同簇的划分
f:同理,基于上述步骤可以进一步实现图c中不同簇的划分
定义了在2D空间中的KNNs形成的角度的方差作为局部方向中心性度量(DCM):


计算边界点与每个内部点的最近距离

内部点簇划分依据:

边界点簇确定依据:各个边界点与其距离最近的内部点同簇 。

动态展示:
2、 CDC聚类效果
选择3个不同形状的数据集,对比K-means,CDP,DBSCAN,LGC四种典型聚类方法与CDC方法,聚类结果如图2所示。

Fig. 2 Comparison with four typical clustering algorithms on three synthetic datasets (DS1-DS3). The three datasets shown in the three rows contain 999, 459 and 7247 points respectively. Each color represents a cluster(此图来源于论文)
CDC算法在部分其他数据集上的聚类效果:




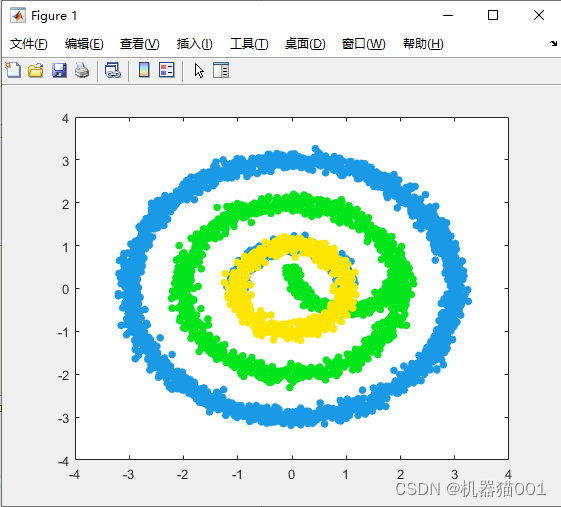
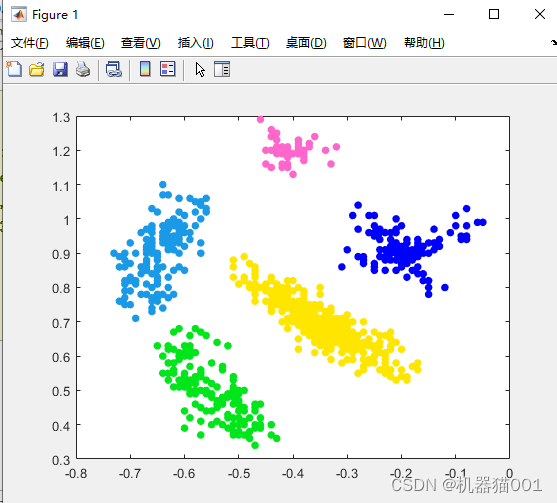
3、CDC应用实践
CDC是一种无监督聚类算法,可以将其应用于分类场景,论文作者将其在语音识别问题上进行了实践,流程及结果如下:
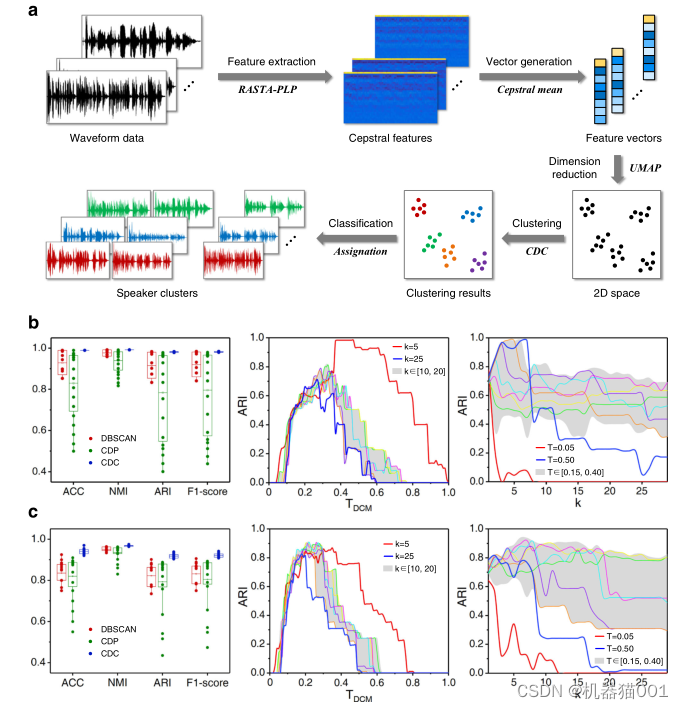
同理,也可以应用于图像识别、故障诊断等领域。当输入数据维度较大时,需要进行特征提取及降维工作。论文作者首先应用NMAP特征降维方法将语音、图片等高维数据降为2维特征空间数据,然后采用CDC进行聚类分析,最后实现分类。
4、CDC应用扩展
(1)CDC是一种无监督聚类方法,在已标记样本不足情况下,可以将大量未标记数据与少量已标记数据结合,应用CDC进行无监督聚类,并联合CDC聚类结果和少量已有的标签信息为大量未标记样本赋予一个伪标签,提升后期分类模型建模的精度。
(2)CDC核心思想是找到边界点和被边界点包围的内部点,采用这种方式很容易得到各簇的形状和边界,然后再基于各簇边界尽可能远离的思想设计无监督特征降维算法是不是相较于传统无监督的PCA算法更具优势呢?
(3)CDC是否可以应用于图像特征工程,实现图像纹理检测呢?