Python爬虫(一)
要爬取网站的信息,
首先,要了解服务器与本地的交换机制;
其次,我们还要了解解析真实网页的办法。
一、服务器与本地的交换机制
我们知道,网页在浏览器中显示内容,都是网页向所部署的服务器进行请求,也就是 Request,然后服务器进行相应,也就是 Response,这也就是 HTTP 协议的大致方式。
九成以上的网页都只使用 GET 和 POST 方法,在浏览器中 F12 打开开发者工具,网页的所有信息都能查看到。
二、具体实现
首先导入库 BeautifulSoup 和 requests,然后进行 get 请求:
from bs4 import BeautifulSoup
import requests
url = "https://blog.csdn.net/qq_42650988"
wb_data = requests.get(url)
soup = BeautifulSoup(wb_data.text, "lxml")
print(soup)
这里请求的就是我的博客地址,看打印出来的 soup:
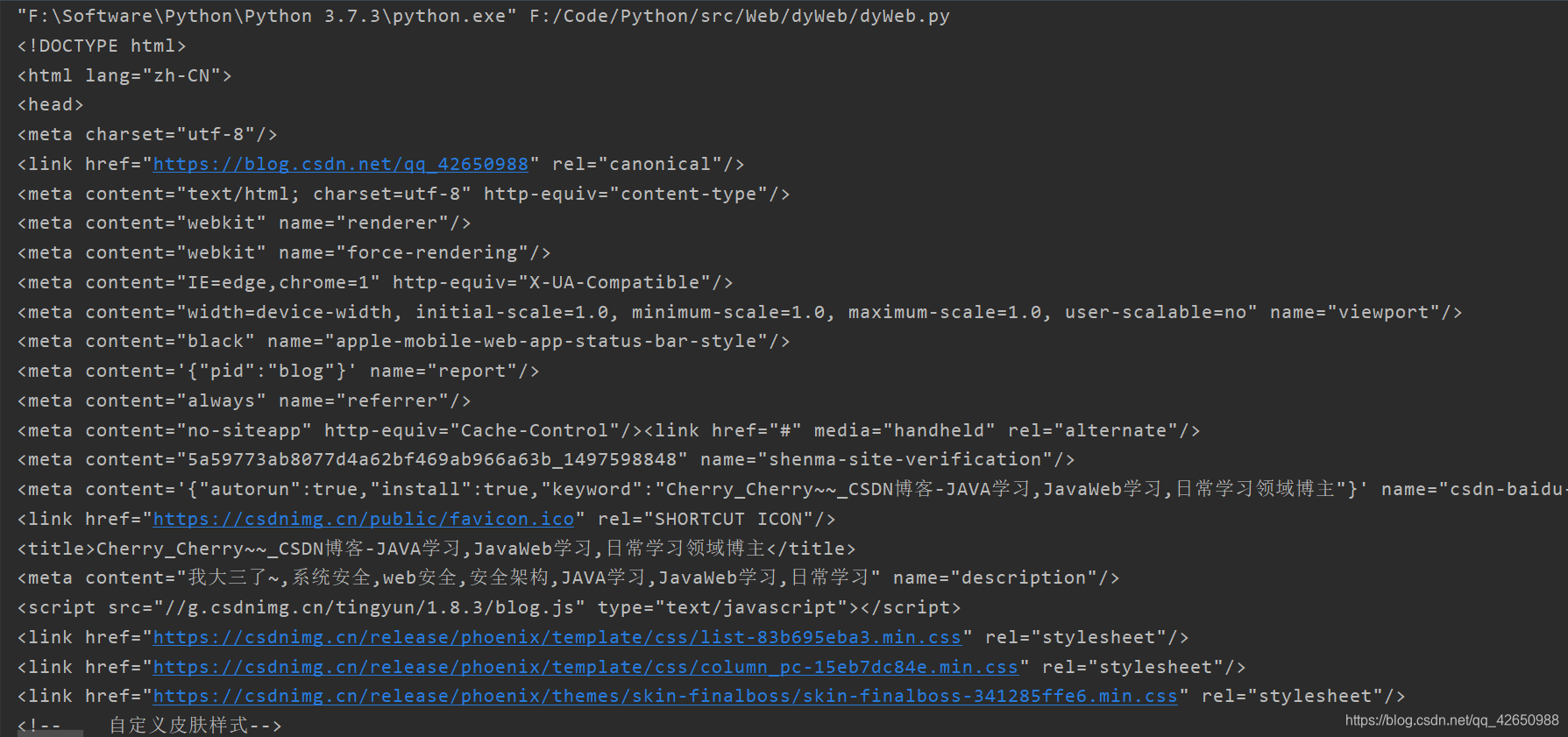
可以看到其实就是网页源代码。
然后找到标题,右键点击 检查,会显示出代码位置:
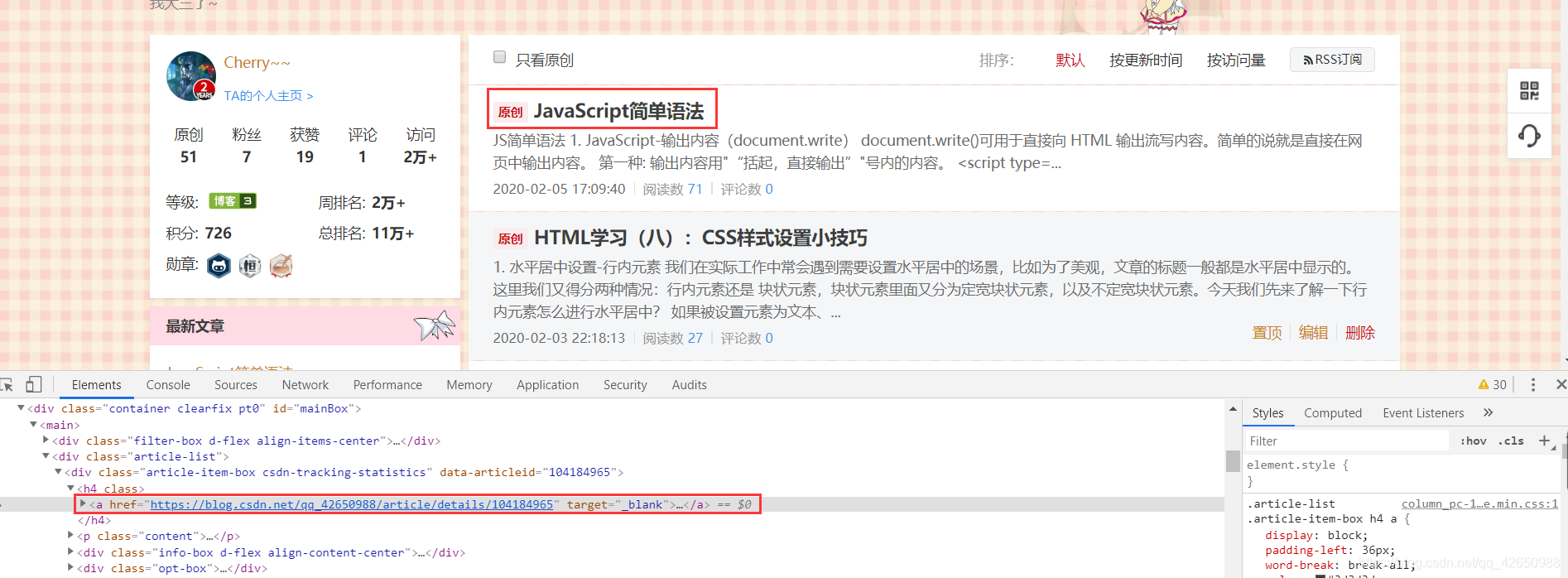
然后在代码上右键选择 Copy 中的 Copy Selector,在python中键入:
titles = soup.select('#mainBox > main > div.article-list > div:nth-child(1) > h4 > a')
print(titles)
查看打印信息:

对于 select 函数,若想要找设定图片宽度为某一特定值,比如100px,可以这样写:
imgs = soup.select('img[width="100px"]')
这样可以找到网页中特定的元素。
另外,看这行代码:
titles = soup.select('# mainBox > main > div.article-list > div:nth-child(1) > h4 > a')
只能找到 div-article-list 下的第一个 div 标签中的标题,但是我们想获得该网页下的所有标题,可以将标签的属性 nth-child(n) 去掉,就表明是获得 div-article-list 下的所有 div 标签,代码如下:
titles = soup.select('#mainBox > main > div.article-list > div > h4 > a')
这时我们用 object.get_text() 方法获得标签内的元素,打印内容如下:
[{'title': 'JavaScript简单语法'}, {'title': 'HTML学习(八):CSS样式设置小技巧'}, {'title': 'HTML学习(七):盒模型代码简写以及单位和值'}, {'title': 'HTML学习(六):CSS布局模型'}, {'title': 'HTML学习(五):CSS盒模型'}, {'title': 'JavaWeb世界(十三):过滤器和监听器'}, {'title': 'JavaWeb世界(十二):验证码的实现和防止表单重复提交'}, {'title': 'JavaWeb世界(十一):购物车的设计与实现'}, {'title': 'JavaWeb世界(十):简单的登录与注销'}, {'title': 'Execl的导入与导出'}, {'title': 'JavaWeb世界(九):文件上传与下载'}, {'title': 'JavaWeb世界(八):MVC思想与合并Servlet'}, {'title': 'Windows10新版本启动虚拟机报错问题'}, {'title': 'Linux点点滴滴(三):SCP免密传输以及在Linux上设置和Windows的共享文件夹'}, {'title': '迈入操作系统的大门(二):环境配置'}, {'title': '迈入操作系统的大门(一)'}, {'title': 'Linux点点滴滴(二):在Linux上安装GNU工具链并进行编译'}, {'title': 'Linux点点滴滴(一):SSH协议'}, {'title': 'CLion中无法用相对路径读入文件'}, {'title': 'JavaWeb世界(七):EL与JSTL'}, {'title': 'Jython使用'}, {'title': 'JavaWeb世界(六):动态网页和JSP'}, {'title': 'JavaWeb世界(五):Web之间组件共享、Servlet三大作用域对象'}, {'title': 'JavaWeb世界(四):Servlet映射与线程、Cookie、Session'}, {'title': 'JavaWeb世界(三):Servlet的请求和相应'}, {'title': 'JavaWeb世界(二):Servlet'}, {'title': 'JavaWeb世界(一):JavaWeb简介、Web项目部署和HTTP协议'}, {'title': 'Windows环境下更新pip和安装ipython'}, {'title': 'Java之路(十二):模拟Hibernate'}, {'title': 'Java之路(十一):DAO优化'}, {'title': 'Java之路(十):JDBC及DAO'}, {'title': 'Android中ListView对Item设置点击事件无效的情况'}, {'title': 'ContentProvider'}, {'title': 'Android studio 引用 butterKnife包错误解决'}, {'title': '接口回调'}, {'title': 'Markdown常用特殊符号'}, {'title': '数据库学习(MySQL)一:表'}, {'title': 'Java之路(九):JavaBean规范、内省机制及注解'}, {'title': 'Java之路(八):枚举类和lambda表达式'}, {'title': 'Java中用String创建对象详解'}]
我们再来观察网页的布局,看到在 a 标签下还有一个 span 标签:

span 标签便是标记该博客是否为原创还是转载等,真正的 a 标签的内容变裸露在外面(其实也可以再用一个text之类的标签再包一下),当我们获得 a 标签的内容时,其实是获得了 span 标签和 a 标签的两个内容:
for title in titles:
data = {
'title': title.get_text()
}
print(data)
这样获得的内容为:
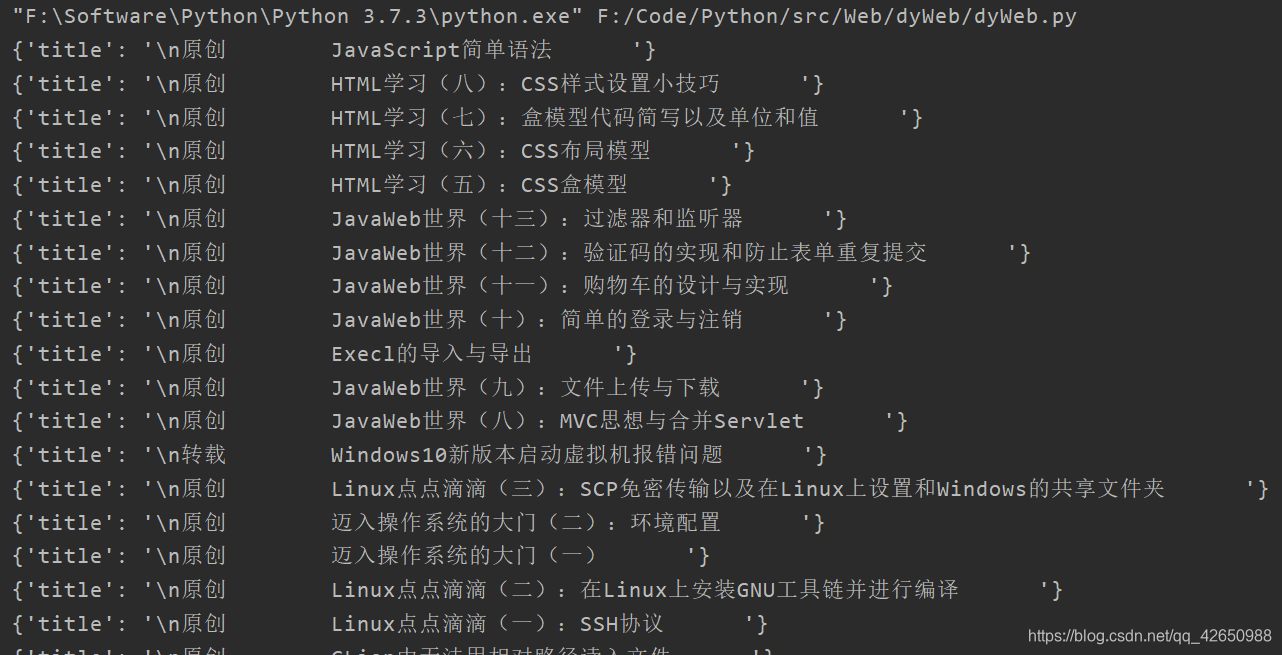
是这个样子的,两个标签的元素在同一个集合中,可以使用函数 object.stripped_strings 将两个元素分开,用 list 存放起来,是这样的: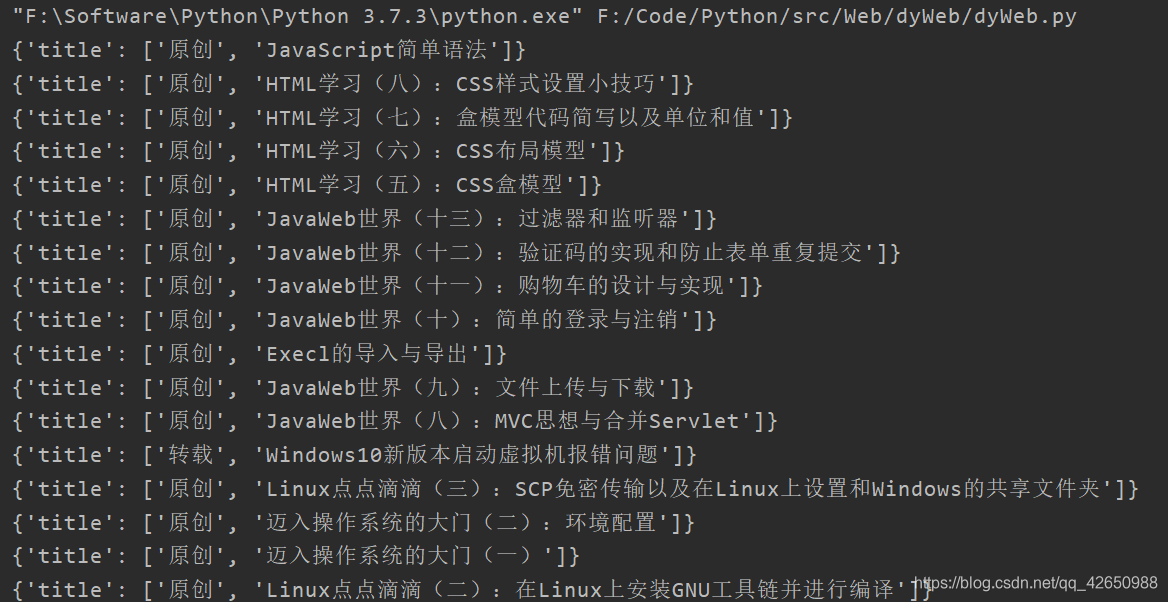
for title in titles:
data = {
'title': list(title.stripped_strings)
}
print(data)
这就将其分开了。

这样做的好处是:因为网页中的标签有很多是一对多的关系,就是一个标签下有很多其他标签,比如一个标题下有两张图片,并且只要获取其中的第二张图片,如果仅仅是使用 get_text() 方法的话,标题有十个,图片有二十张,这样很难将第二张图片提取出来,因此要把每一个标题下的内容单独放在列表中,便于后面的操作。
最终,我们将网页的标题、内容和阅读数都提取了出来。
很简单的一段代码:
from bs4 import BeautifulSoup
import requests
url = "https://blog.csdn.net/qq_42650988"
wb_data = requests.get(url)
soup = BeautifulSoup(wb_data.text, "lxml")
# print(soup)
titles = soup.select('#mainBox > main > div.article-list > div > h4 > a')
contents = soup.select('#mainBox > main > div.article-list > div > p > a')
readers = soup.select(
'#mainBox > main > div.article-list > div > div.info-box.d-flex.align-content-center > p:nth-child(3) > span > span')
for title, content, reader in zip(titles, contents, readers):
data = {
'title': list(title.stripped_strings),
'content': content.get_text(),
'readers': reader.get_text()
}
print(data)
打印结果:

三、网站加密和登录状态情况
有些网站会进行加密,使用了反爬取技术,防止不法爬取网站信息。例如会将图片地址通过各种手段加密,将真正的地址放到 js 代码块中,用一个其他字段进行映射:

这种情况下,我们便很难提取出网站图片的真实地址。但是后面会介绍一种比较简单可行的方法来解决这一问题。
还有一种情况,当想获取需要登录才能得到的内容时,比如每个人收藏的内容,只有当登录的时候才能看到,我们观察:
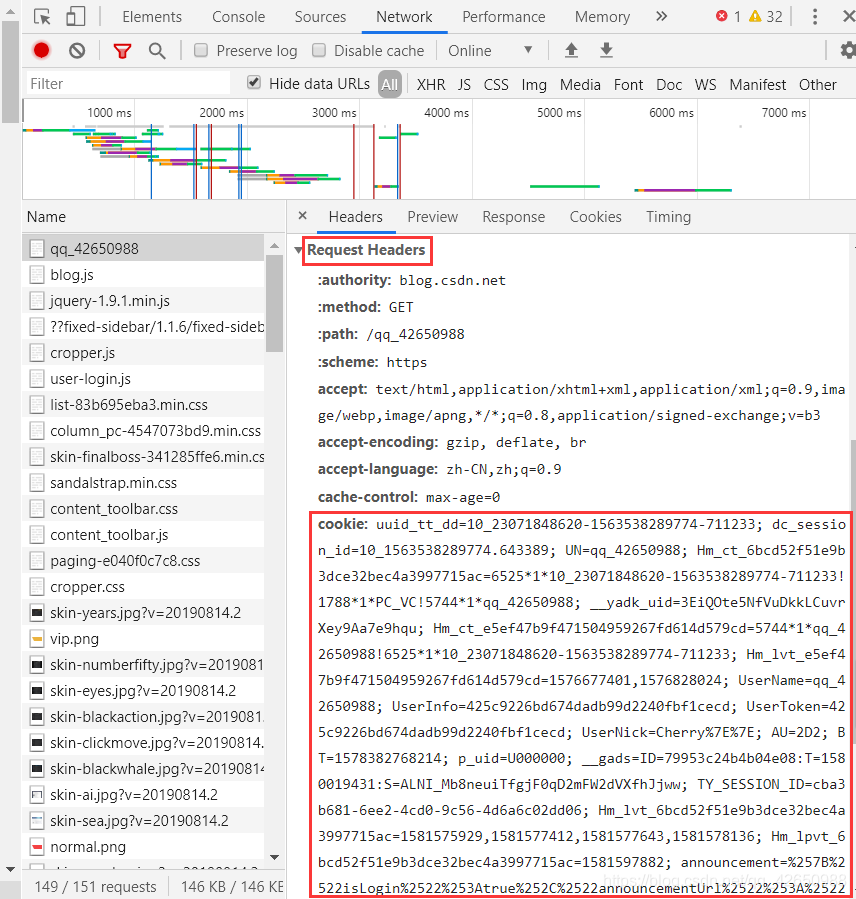
每次登录时,在请求头当中,都会有代表身份识别的一个参数 Cookie,我们只要将请求头中加入 Cookie 参数,就可以向服务器提交伪造登录的状态。
类似下面的代码:
headers {
'user-agent': '',
'cookie': ''
}
...
wb_data = requests.get(url, headers=headers)
...
这样就可以获取到需要登录状态的信息了。
四、爬取网页中的多页信息
一般情况下,网页中的每一页都是一个链接,当然我们不可能为每一页都写一个函数去爬取,因此需要一些手段来自动获取。
然而有些网站的地址是以 ?page= 结尾,来定位到某一页,但是有的网站不是这样,但是都是大同小异,需要仔细观察网页的地址。

可以这样写来列出所有页的地址:
str = ['https://blog.csdn.net/qq_42650988/article/list/{}'.format(str(i)) for i in range(1, 10)]
打印出来就是这样的:
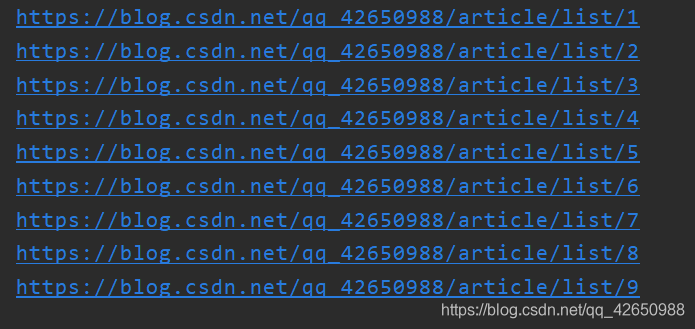
然后再循环依次获取就可以了。
五、完整代码
from bs4 import BeautifulSoup
import requests
import time
url = "https://blog.csdn.net/qq_42650988"
headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.108 Safari/537.36',
'cookie': 'uuid_tt_dd=10_23071848620-1563538289774-711233; dc_session_id=10_1563538289774.643389; UN=qq_42650988; Hm_ct_6bcd52f51e9b3dce32bec4a3997715ac=6525*1*10_23071848620-1563538289774-711233!1788*1*PC_VC!5744*1*qq_42650988; __yadk_uid=3EiQOte5NfVuDkkLCuvrXey9Aa7e9hqu; Hm_ct_e5ef47b9f471504959267fd614d579cd=5744*1*qq_42650988!6525*1*10_23071848620-1563538289774-711233; Hm_lvt_e5ef47b9f471504959267fd614d579cd=1576677401,1576828024; UserName=qq_42650988; UserInfo=425c9226bd674dadb99d2240fbf1cecd; UserToken=425c9226bd674dadb99d2240fbf1cecd; UserNick=Cherry%7E%7E; AU=2D2; BT=1578382768214; p_uid=U000000; __gads=ID=79953c24b4b04e08:T=1580019431:S=ALNI_Mb8neuiTfgjF0qD2mFW2dVXfhJjww; TY_SESSION_ID=cba3b681-6ee2-4cd0-9c56-4d6a6c02dd06; Hm_lvt_6bcd52f51e9b3dce32bec4a3997715ac=1581575929,1581577412,1581577643,1581578136; Hm_lpvt_6bcd52f51e9b3dce32bec4a3997715ac=1581597882; announcement=%257B%2522isLogin%2522%253Atrue%252C%2522announcementUrl%2522%253A%2522https%253A%252F%252Fblog.csdn.net%252Fblogdevteam%252Farticle%252Fdetails%252F103603408%2522%252C%2522announcementCount%2522%253A0%252C%2522announcementExpire%2522%253A3600000%257D; dc_tos=q5n4qp'
}
def get_attractions(url, data=None):
wb_data = requests.get(url)
time.sleep(2)
soup = BeautifulSoup(wb_data.text, "lxml")
titles = soup.select('#mainBox > main > div.article-list > div > h4 > a')
contents = soup.select('#mainBox > main > div.article-list > div > p > a')
readers = soup.select(
'#mainBox > main > div.article-list > div > div.info-box.d-flex.align-content-center > p:nth-child(3) > span > span')
for title, content, reader in zip(titles, contents, readers):
data = {
'title': list(title.stripped_strings),
'content': content.get_text(),
'readers': reader.get_text()
}
print(data)
url = 'https://me.csdn.net/follow/qq_42650988'
def get_fav(url, data=None):
wb_data = requests.get(url, headers=headers)
soup = BeautifulSoup(wb_data.text, 'lxml')
fans = soup.select(
'body > div.me_wrap.clearfix > div.me_wrap_l.my_tab_page.clearfix > div.me_chanel_det.clearfix > div.chanel_det_list.clearfix > ul > li > div > p > a')
for fan in fans:
data = {
'fan': list(fan.stripped_strings)
}
print(data)
urls = ['https://blog.csdn.net/qq_42650988/article/list/{}'.format(str(i)) for i in range(1, 3)]
for single_url in urls:
get_attractions(single_url)
六、利用手机端的浏览来爬取被加密的内容
有的时候在电脑上浏览的网页会通过各种手段加密,但是在手机上,可能有些浏览器无法完整的加载所有 js 部分,因此整体结构会相对比较简单。我们打开监视器,点击左上角的手机图标,调整手机型号,然后刷新一下,就可以展现出在手机端的页面了:
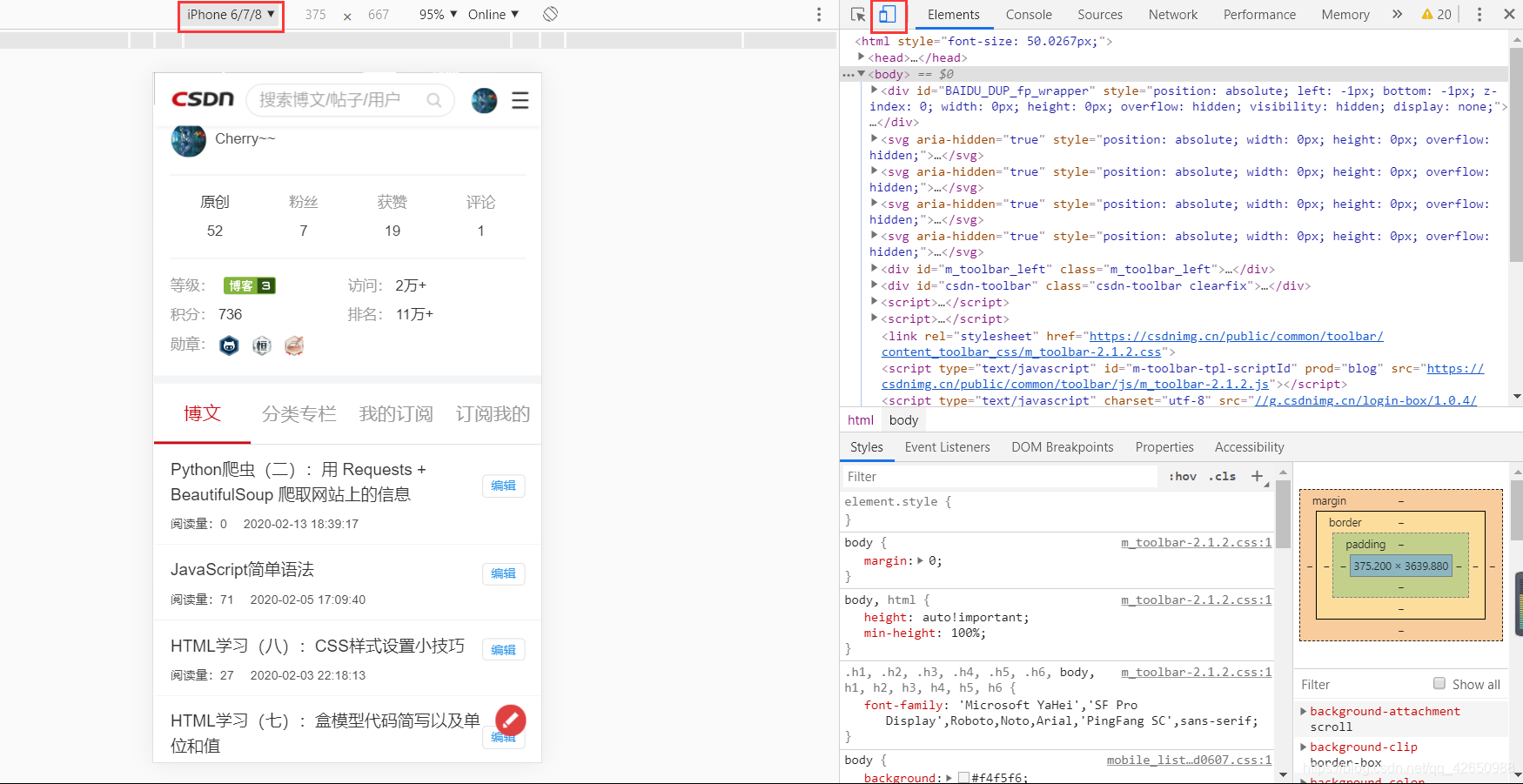
因此我们需要获取到请求头中的信息来伪造是用手机访问。
headers = {
'User-Agent': 'Mozilla/5.0 (iPhone; CPU iPhone OS 11_0 like Mac OS X) AppleWebKit/604.1.38 (KHTML, like Gecko) Version/11.0 Mobile/15A372 Safari/604.1'
}
七、获取动态数据
有时候我们浏览一个网页的时候,所有内容不是一次性加载完毕,而是点击类似于 加载更多 后者鼠标滚轮往下滑动的时候会自动加载。这些都是通过 JS 代码来实现的。这也就是所谓数据的 异步加载。最典型的就是我们的QQ空间,往下拉到底的时候会继续加载更早的内容。
其实很简单,跟同事获取多页的数据是一样的,要观察获取更多数据的请求的特点,就可以用代码构造出响应的请求去获取数据。
因为刚开始学习,时间有限,又是比较基础的东西,具体的示例将来有机会再写。
