版权声明:本文为博主原创文章,未经博主允许不得转载。 https://blog.csdn.net/lxfHaHaHa/article/details/80469073
python3爬虫实战之二
有时候有比赛通知了也不清楚,就写了个爬虫,里面两种方法,一个是通过邮件方式实时获得最新比赛信息,一个是获得最近的一些比赛信息
环境先安装requests库、beautifulsiup库
qq邮箱配置方法: https://jingyan.baidu.com/article/6d704a133a245f28db51caf5.html
看心情,啥时候补个详细步骤介绍,如果我有动力的话= =
spider_contest.py
# coding:utf-8
## 先安装环境python3、pip环境
## pip3 install requests
## pip3 install BeautifulSoup4
## sudo apt-get install python3-lxml 或者 pip3 install lxml
## 杭电官网比赛信息爬取
## 需要修改的地方是send_email方法里面的smtpServer、emailAddr、emailPass,换成自己的邮箱地址
## qq邮箱配置方法: https://jingyan.baidu.com/article/6d704a133a245f28db51caf5.html
## 在主函数里面修改选择需要使用的方法
## 直接运行即可 python3 spider_contest.py
## 测试环境为win10-python3
## author: lxfhahaha
## date: 2018年5月27日13:59:21
import requests
from bs4 import BeautifulSoup
import smtplib
from email.mime.text import MIMEText
from email.header import Header
import time
class ContestNews: ##比赛信息类
def __init__(self,newsName='0',url='0',newsTime='0'):
self.name=newsName #标题
self.time=newsTime #通知时间
self.url=url #通知地址
def __str__(self):
return '地址:'+str(self.url)+' 发布时间:'+str(self.time)+' 发布内容:'+str(self.name)
def send_email(content,subject): #发送邮件代码 ,用的是qq邮箱,发送给自己
#初始化邮箱设置
# smtp服务器的地址
smtpServer = "smtp.qq.com"
# 邮箱服务器端口
stmpPort=25
# 发件箱的地址
emailAddr = "XXXXXXXX"
# smtp口令
emailPass = "XXXXXXXXXX"
# 自己发自己邮箱不容易被当垃圾邮箱拦截
targetAddr=[emailAddr]
try:
message = MIMEText(content, 'html', 'utf-8')
message['from'] = Header("moocclub小助手", 'utf-8')
message['to'] = Header("Administar", 'utf-8')
message['subject'] = Header(subject, 'utf-8')
server=smtplib.SMTP(smtpServer,stmpPort)
server.starttls()
server.login(emailAddr,emailPass)
server.sendmail(emailAddr,targetAddr,message.as_string())
server.quit()
print ("Success: 邮件发送成功")
except Exception as e:
print ("Error: 无法发送邮件--"+str(e))
def newsLatestList(): ##获得一些最新的比赛消息列表
re=requests.get(url,headers=headers)
listAll=[]
soup=BeautifulSoup(re.text,'lxml')
for one in soup.select('.newsList ul li'):
new=ContestNews(one.find('a').get_text(),urlBase+ one.find('a').get('href'),one.find('span').get_text())
listAll.append(new)
print(new)
return listAll
def newsLatestOne(): ##获得最新的一条消息
newsOld=ContestNews()
while True:
re=requests.get(url,headers=headers)
soup=BeautifulSoup(re.text,'lxml')
one=soup.select('.newsList ul li')[0]
new=ContestNews(one.find('a').get_text(),urlBase+ one.find('a').get('href'),one.find('span').get_text())
if(new.url!=newsOld.url):
content=("<p>名称:"+str(new.name)+"</p>"
+"信息发布时间:"+str(new.time)+"</p>"
+"信息链接:<a href='"+str(new.url)+"'>"+str(new.url)+"</a></p>")
subject='杭电比赛最新消息-'+str(new.name)
send_email(content,subject)
newsOld=new
time.sleep(300) #每5min查询一次
if __name__ == '__main__': ##主函数入口
url='http://jwc.hdu.edu.cn/node/400.jspx'
urlBase='http://jwc.hdu.edu.cn/'
headers={
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/65.0.3325.181 Safari/537.36',
'Referer': 'http://jwc.hdu.edu.cn/'
}
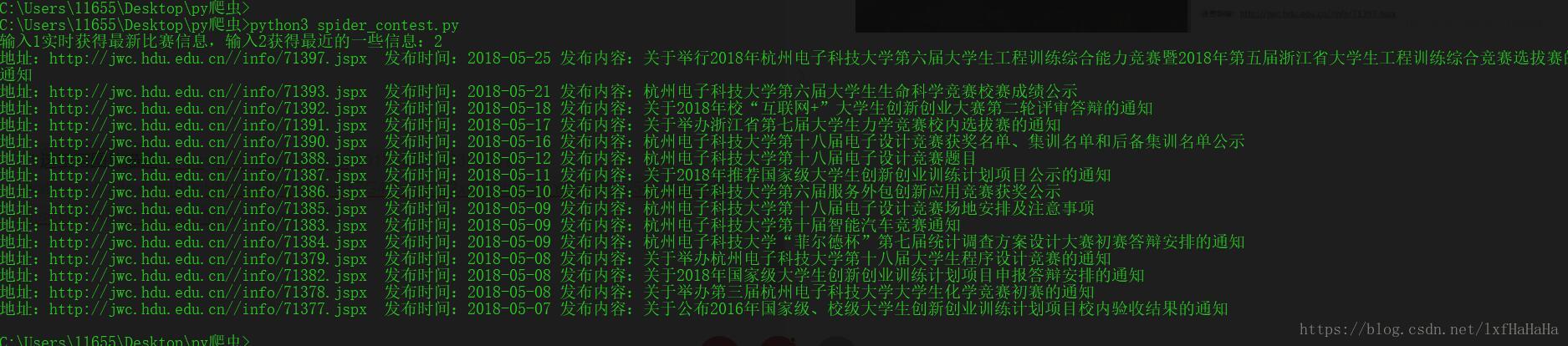
a=input('输入1实时获得最新比赛信息,输入2获得最近的一些信息:')
if a=='1':newsLatestOne()
if a=='2':newsLatestList()
选择1:
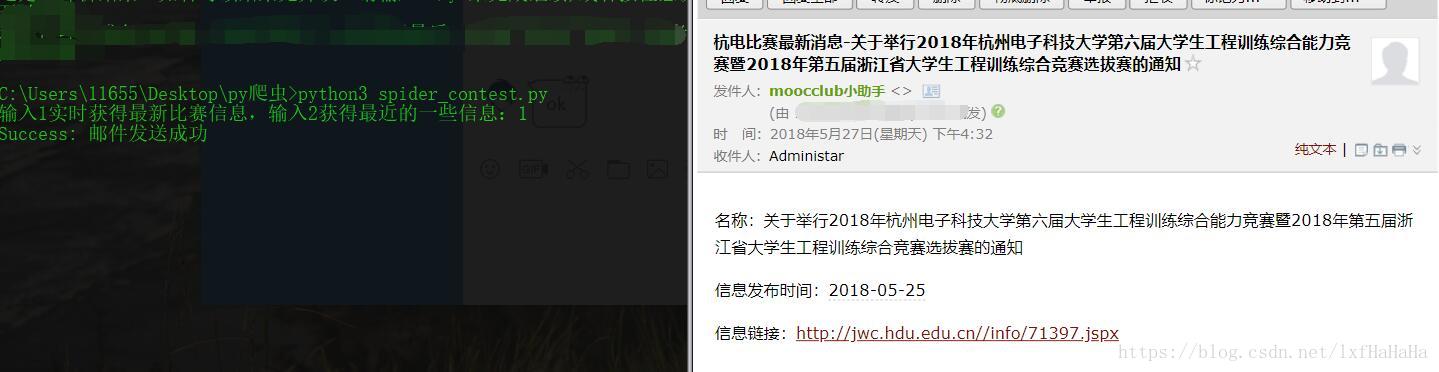
选择2: