接着上一篇博客的代码,对细节作了一些修改和完善,并用pyinstaller -F XXX.py生成.exe应用程序,可直接运行。
爬取对象url = http://cmee.nwafu.edu.cn/szdw/gjzcry/index.htm
下面给出所有代码:
import requests
import bs4
import os
from bs4 import BeautifulSoup
import re
#用requests获取url页面中的文本信息,返回r.text
def getHTMLText(url):
try:
r = requests.get(url, timeout = 30)
r.raise_for_status()
r.encoding = r.apparent_encoding
return r.text
except:
return ""
#利用BeautifulSoup获取教师姓名和打开简历的url,存储到ulist列表中并返回
def fillName(ulist, html):
soup = BeautifulSoup(html, "html.parser")
for tag in soup.find_all('a'):
ulist.append([tag.string, tag.attrs['href']])
#打印出ulist列表中的教师姓名和打开简历的url
def getName(ulist):
tplt = "{:^10}\t{:<50}"
print(tplt.format("姓名", "网址"))
for i in range(len(ulist)):
try:
u = ulist[i]
print(tplt.format(u[0], u[1]))
except:
continue
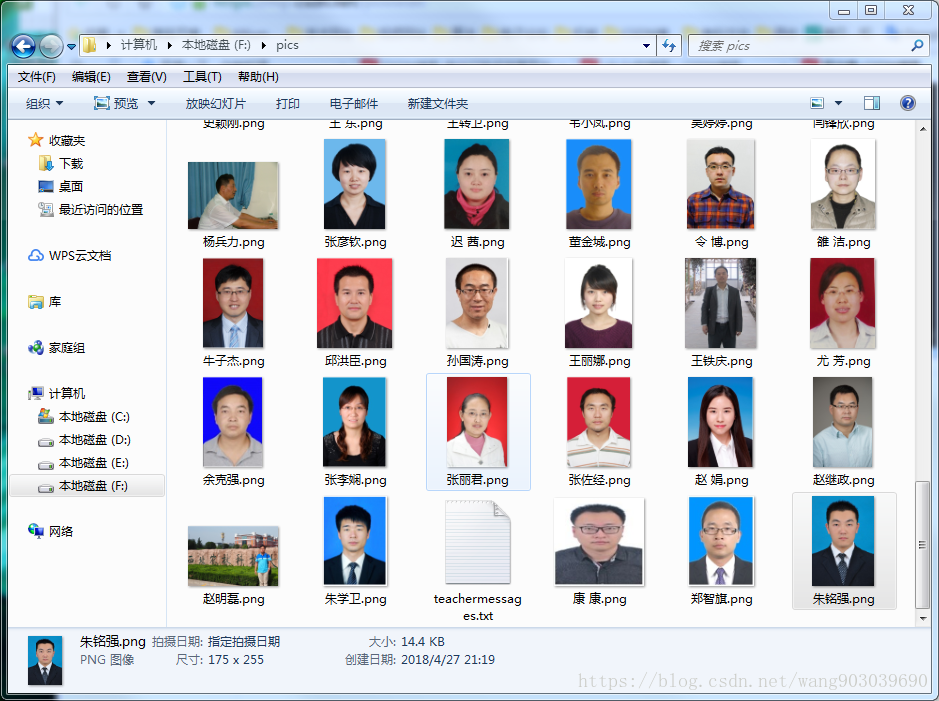
#创建F:/pics文件夹,保存教师的照片,并把所有 教师简历信息 写入teachermessages.txt文件中
def getInfo(ulist):
root = "F://pics//"
count = 0
for i in range(15,len(ulist)-1):
personinfo = ulist[i]
personname = personinfo[0]
personurl = personinfo[1]
path = root + personname +'.png'
personhtml = getHTMLText(personurl)
soup = BeautifulSoup(personhtml, "html.parser")
if not os.path.exists(root):
os.mkdir(root)
for tag in soup.find_all('p'):
with open('F://pics//teachermessages.txt', 'a', encoding = 'utf-8') as f:
f.write(str(tag.string) + '\n')
f.close()
try:
match = re.search(r'src\=\"\.\.\/\.\.\/images\/content\/.*?g',personhtml)
strurl = match.group(0)
except:
continue
pictureurl = 'http://cmee.nwsuaf.edu.cn/i' + strurl.split('i')[-1]
r = requests.get(pictureurl)
with open(path, 'wb') as f:
f.write(r.content)
f.close()
count = count + 1
print('\r爬取进度:{:.2f}%'.format(count*100/(len(ulist)-20)),end='')
print('爬取完成')
#主函数,运行
def main():
uinfo = []
url = 'http://cmee.nwafu.edu.cn/szdw/gjzcry/index.htm'
html = getHTMLText(url)
fillName(uinfo, html)
getName(uinfo)
getInfo(uinfo)
input("Press <enter>")
if __name__ == '__main__':
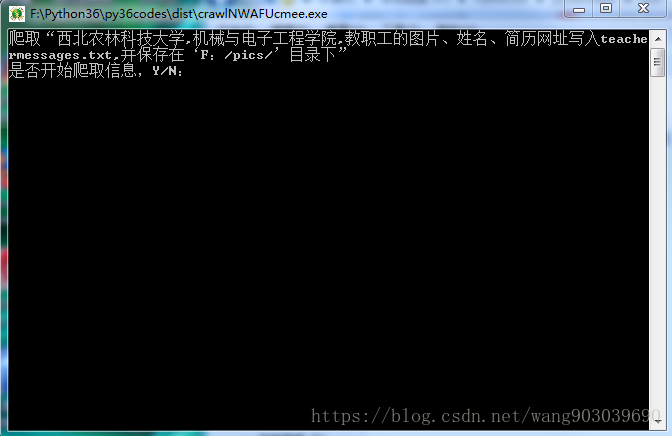
print('爬取“西北农林科技大学,机械与电子工程学院,教职工的图片、'\
'姓名、简历网址写入teachermessages.txt,并保存在‘F:/pics/’目录下”')
comd = input("是否开始爬取信息,Y/N:")
if comd in ['Y','y','是','开始']:
main()
代码分为 三 大块:一、利用requests相关方法获取url的文本信息并返回;二、解析第一步返回的文本信息,这里用了bs4库中的BeautifulSoup类方法来对r.text信息进一步整理(也可以利用re库的正则表达式获取),将检索的信息存储到ulist列表中,以待后续调用;三、输出,或者叫获取、调用,第三步将信息更好的解析出来,输出或者保存为想要的格式
刚开始学习,记录和督促一下自己。
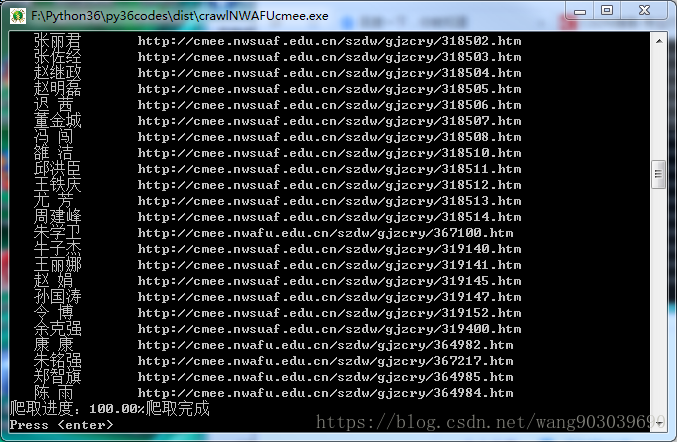
运行实例: