版权声明:本文为博主原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接和本声明。
 我们经常看到各种大学排行榜
我们经常看到各种大学排行榜
那能不能通过爬虫随时知道学校的排名呢
当然可以
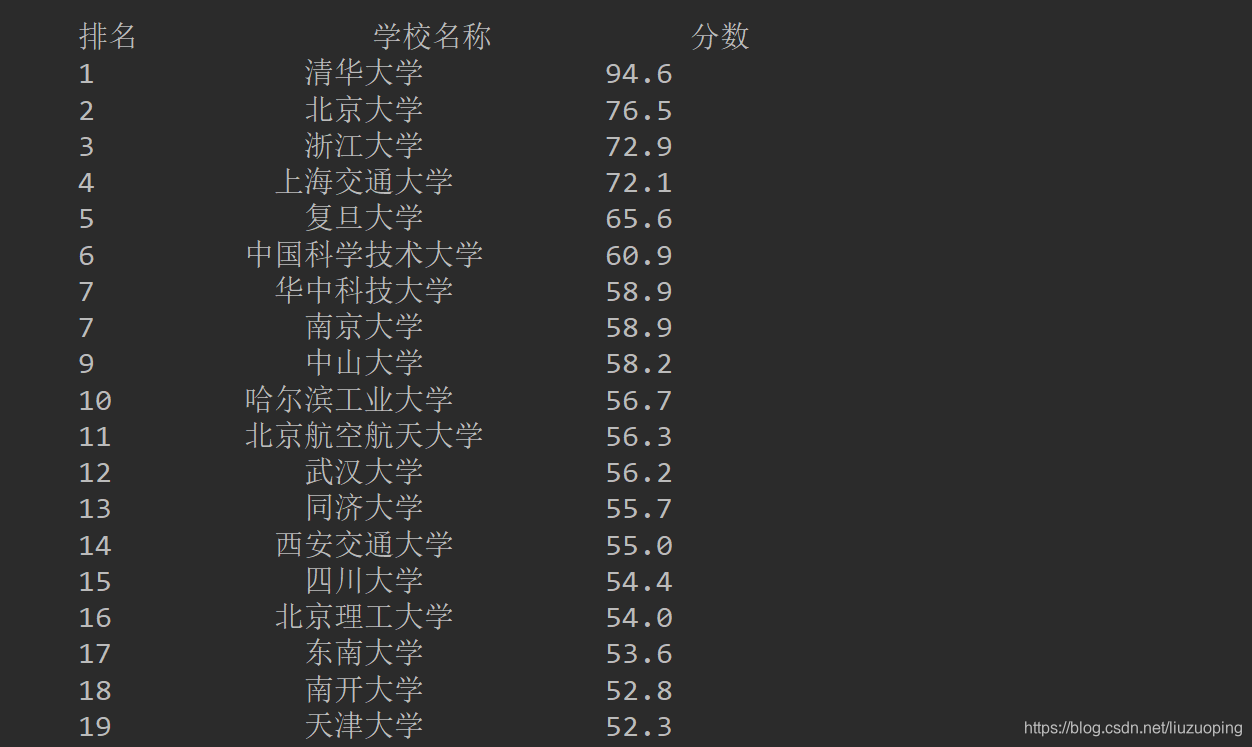
看看下面抓取的效果图
 那么具体怎么实现呢
那么具体怎么实现呢
实现工具
pycharm+BeautifulSoup+requests
具体代码
import requests
from bs4 import BeautifulSoup
import bs4
def getHTMLText(url):
try:
r = requests.get(url,timeout = 30)
r.raise_for_status()
r.encoding = r.apparent_encoding
return r.text
except:
print("getError")
return ""
return ""
def fillUnivList(ulist,html):
soup = BeautifulSoup(html,"html.parser")
for tr in soup.find('tbody').children:
print(tr)
if isinstance(tr,bs4.element.Tag):
tds = tr('td')
ulist.append([tds[0].string,tds[1].string,tds[3].string])
def printUnivList(ulist,num):
tplt = "{0:^10}\t{1:{3}^10}\t{2:^10}"
print(tplt.format("排名","学校名称","分数",chr(12288)))
for i in range(num):
u = ulist[i]
print(tplt.format(u[0],u[1],u[2],chr(12288)))
def main():
unifo = []
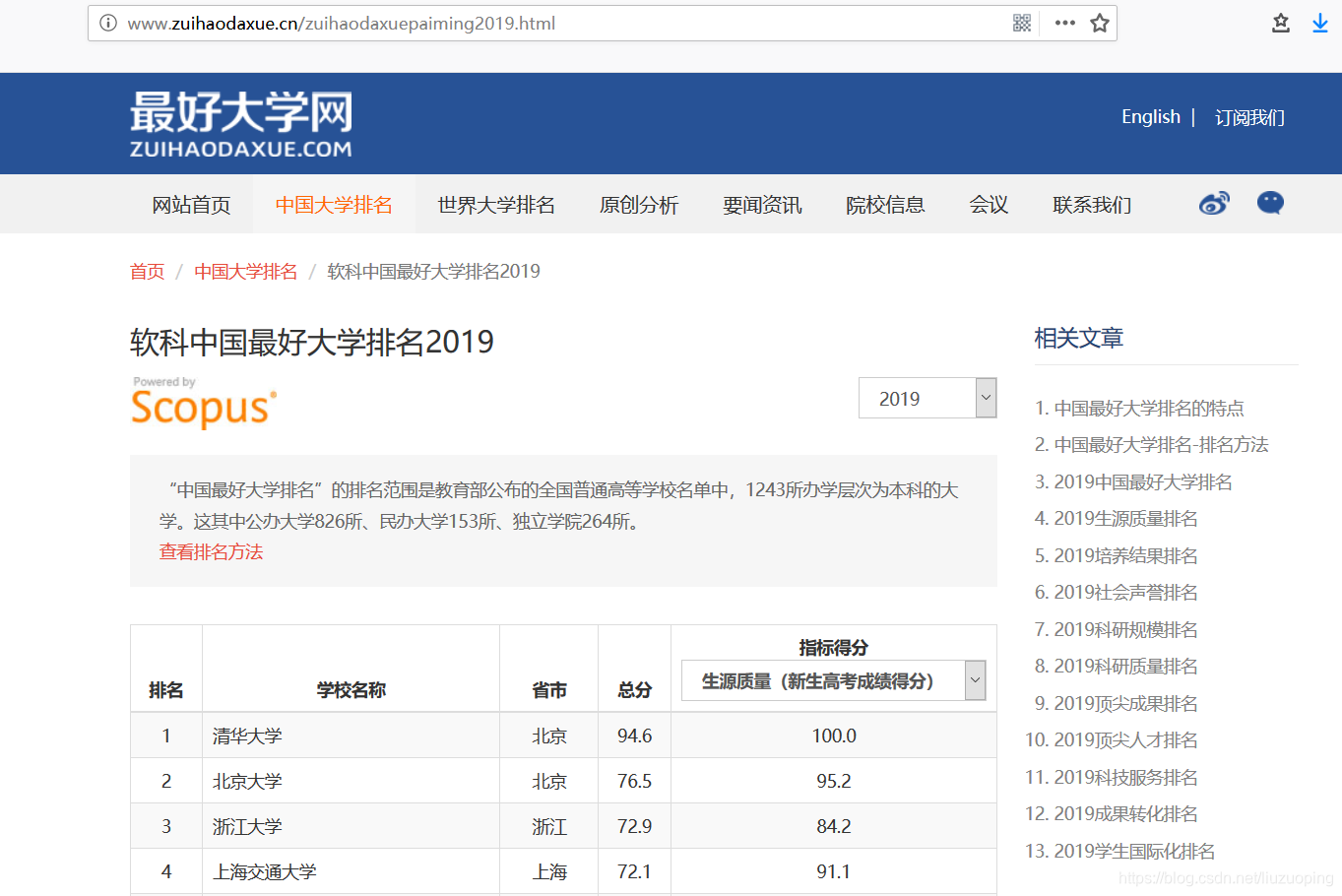
url = "http://www.zuihaodaxue.cn/zuihaodaxuepaiming2019.html"
html = getHTMLText(url)
fillUnivList(unifo,html)
printUnivList(unifo,100)
main()
代码分析
网站分析
这次我们爬取的是最好大学网2019年的大学排名
 首先用requests请求网页
首先用requests请求网页
并且加上异常处理
def getHTMLText(url):
try:
r = requests.get(url,timeout = 30)
r.raise_for_status()
r.encoding = r.apparent_encoding
return r.text
except:
print("getError")
return ""
return ""
然后使用Beautifulsoup解析网页
结构分析
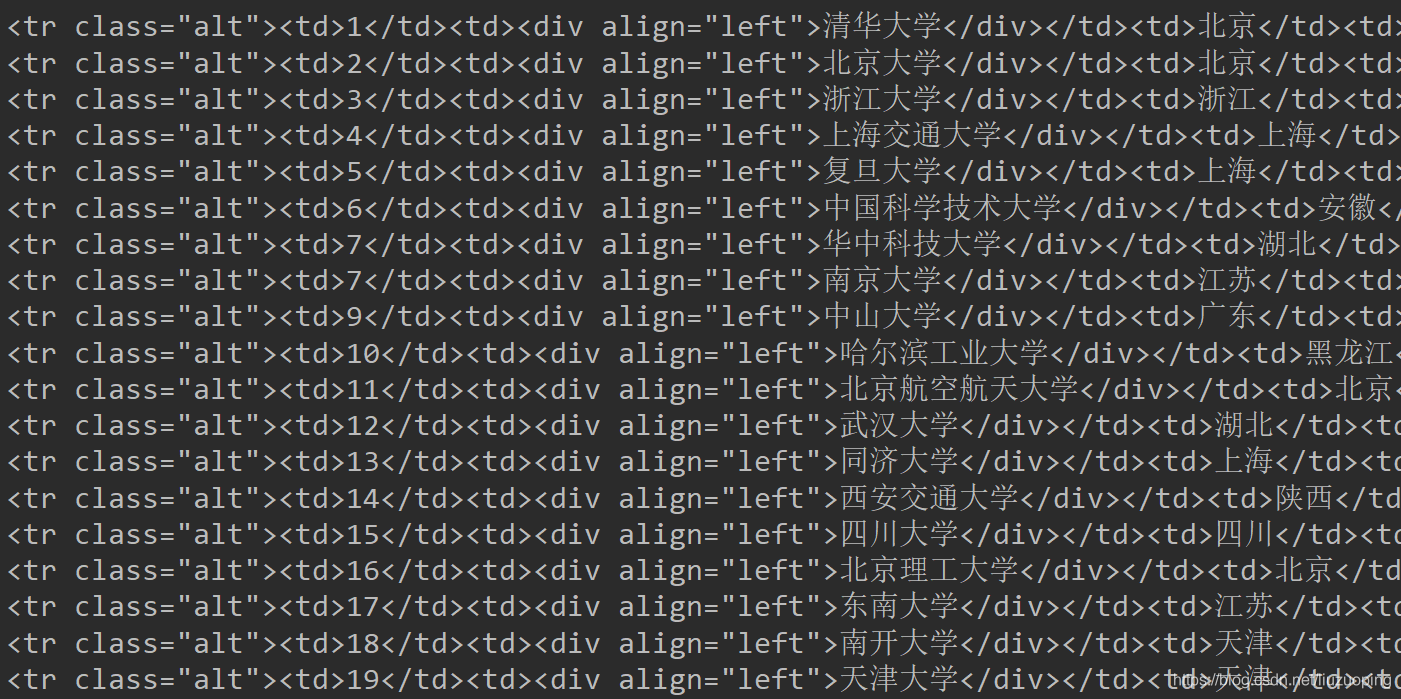
排名位于tbody标签下
每个tr标签是一个学校的信息
tr标签下有多个td标签,保存有该学校的各类指标
遍历tr标签 tr标签是tbody标签的孩子

def fillUnivList(ulist,html):
soup = BeautifulSoup(html,"html.parser")
for tr in soup.find('tbody').children:
print(tr)
if isinstance(tr,bs4.element.Tag):
# 获取tr标签下的td标签
tds = tr('td')
# 获取相关指标 只需要第 0 1 3 个相关td标签,分别是学校名称,排名,分数
ulist.append([tds[0].string,tds[1].string,tds[3].string])
打印前100的榜单
def printUnivList(ulist,num):
# 优化,解决中文不对齐问题
#^num num代表占位
tplt = "{0:^10}\t{1:{3}^10}\t{2:^10}"
# chr(12288)是中文空白符
print(tplt.format("排名","学校名称","分数",chr(12288)))
for i in range(num):
u = ulist[i]
print(tplt.format(u[0],u[1],u[2],chr(12288)))
最后成功发现了我的学校

