实验环境: win7 python3.5 bs4 0.0.1 requests 2.19
实验日期:2018-08-07
爬取网站:http://www.xhsd.cn/
现在的网站大多有复杂的交互,地方政府的网站又太简单,体现不出bs4的解析过程; http://www.xhsd.cn/ 这个网站,还算现代,很可贵的是它还是直接在服务端返回的,客户端没有渲染;
2018-08-07 它的预览是这样的(爬取之前,先通过chrome浏览器 检查 页面元素,了解页面html构造)
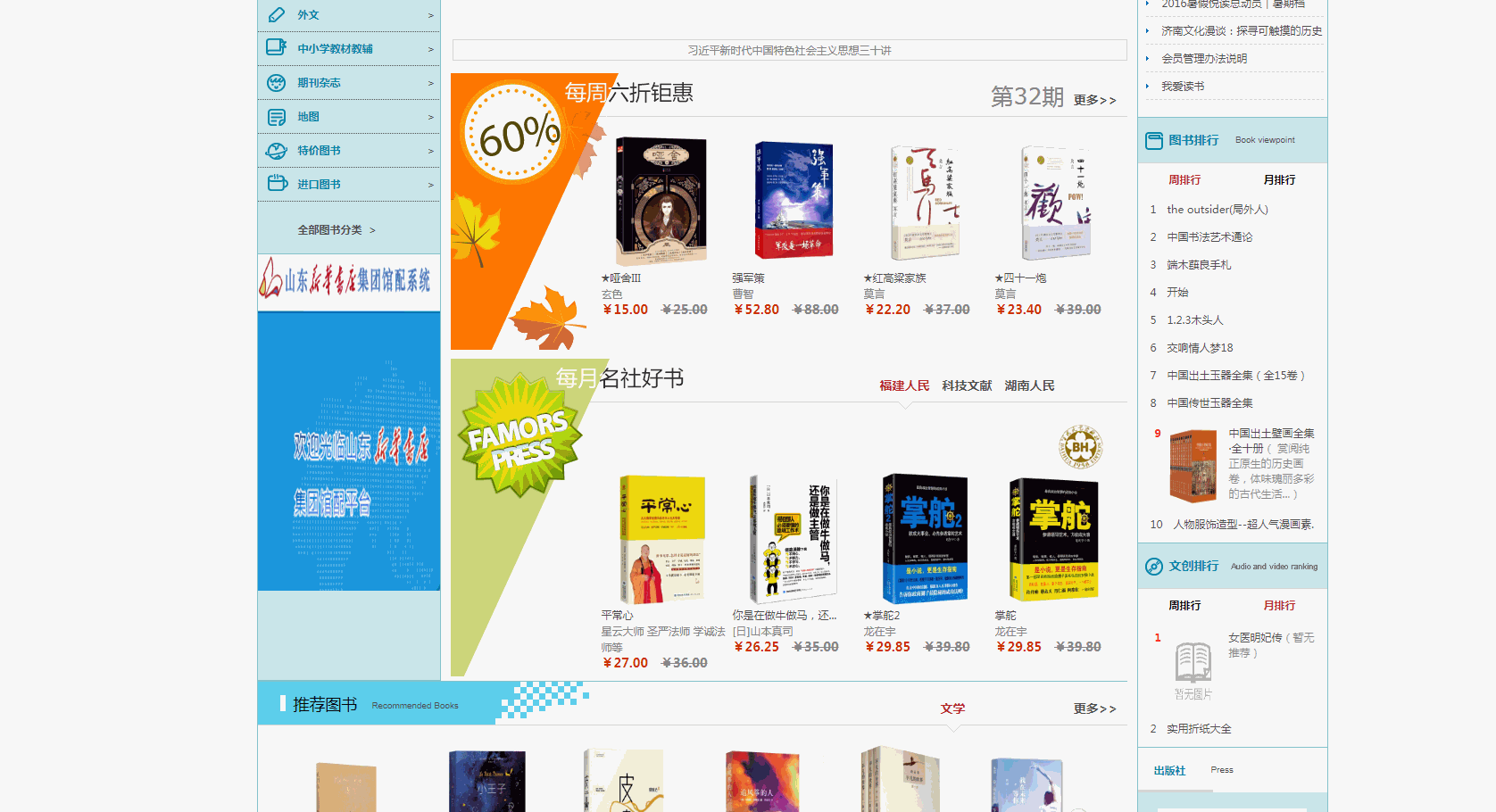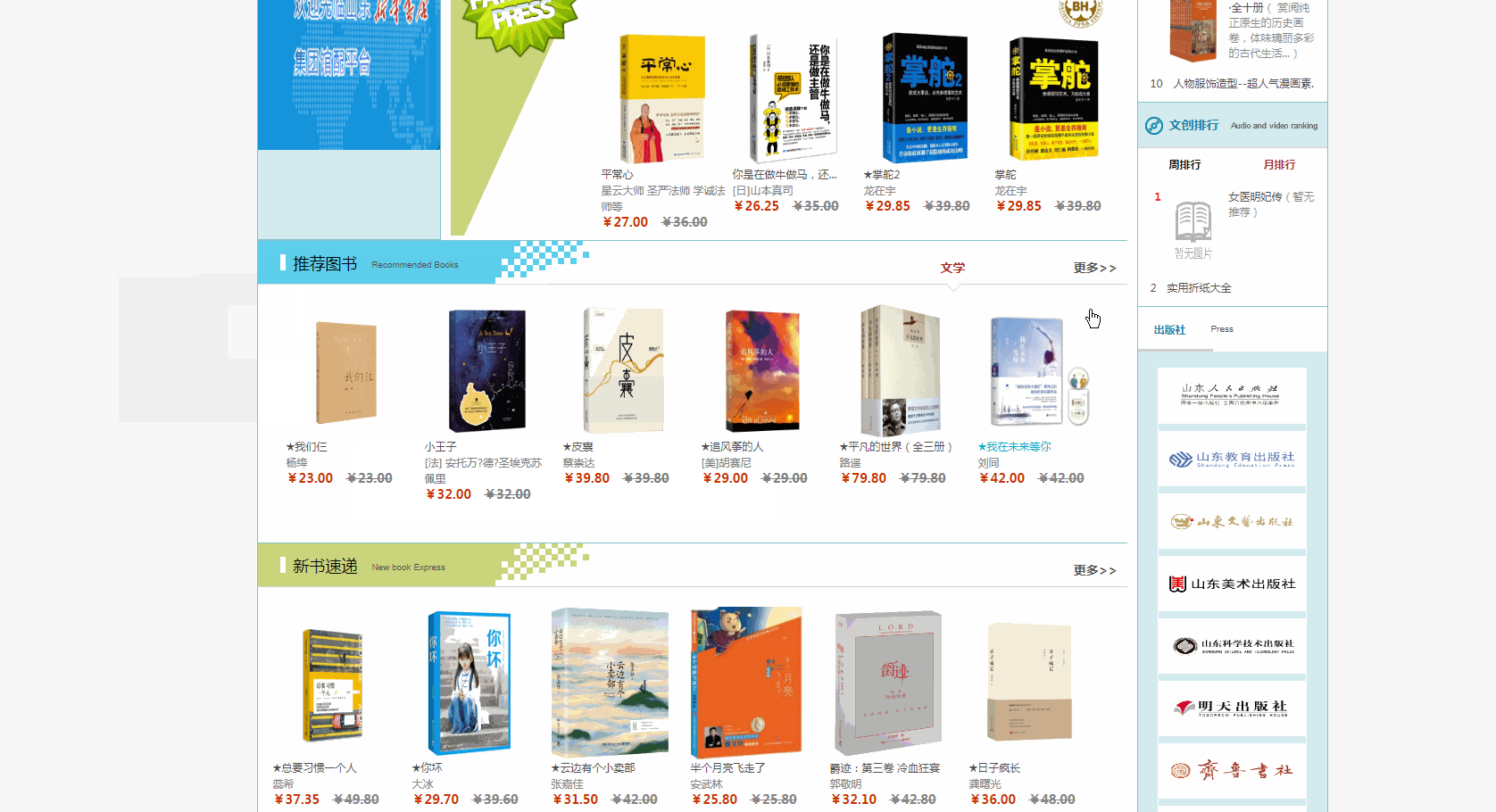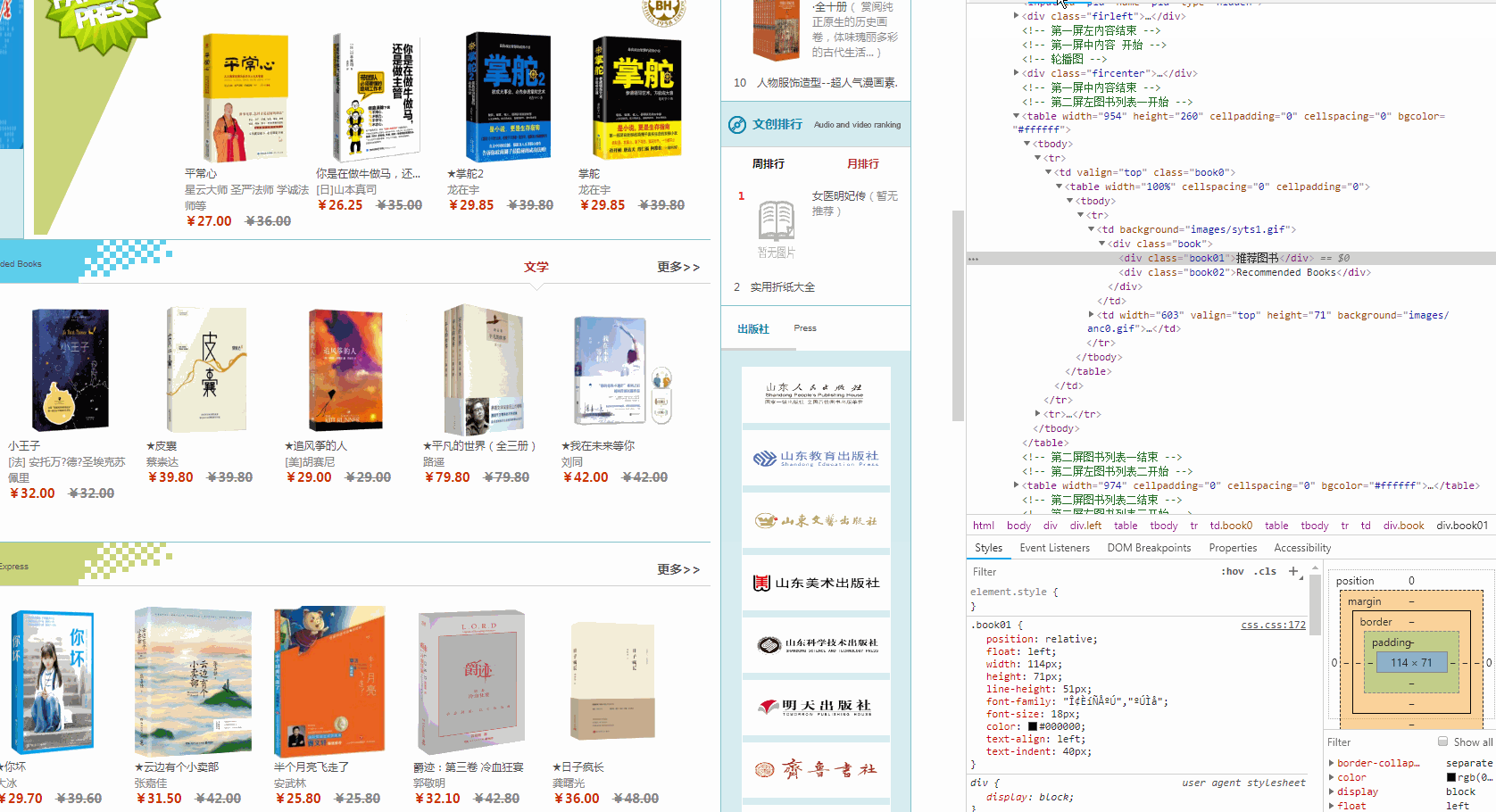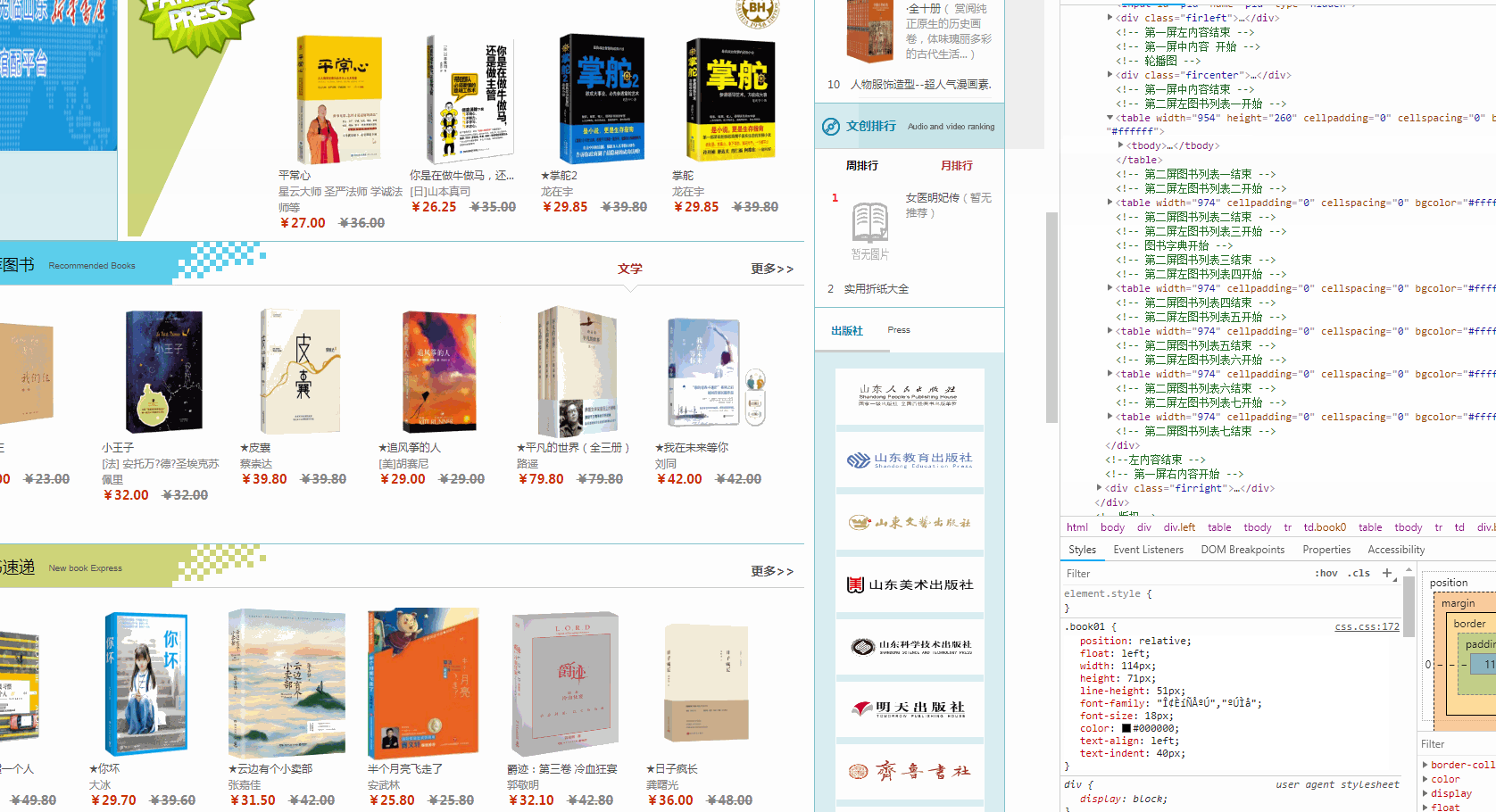
希望抓取 推荐图书 新书速递 考试用书等
python 抓取代码
import requests
import bs4
import pandas as pd
import re
url="""http://www.xhsd.cn/"""
r=requests.get(url)
html=r.text
soup=bs4.BeautifulSoup(html,'lxml')
tables=soup.find_all('table',bgcolor="#ffffff")
def etr(tb):
content={}
arr=list(filter(lambda x:len(str(x))>2,tb.children))
tr1=arr[0]
tr2=arr[1]
label=next(tr1.stripped_strings)
content['label']=label
print(label)
a_s=tr2.find_all('a',title=True)
cs=[]
for a in a_s:
try:
cts=list(a.stripped_strings)
#print(cts)
book,auth,price_now,price_before=cts
img=a.find('img')['src']
tmp={"book":book,"auth":auth,"price_now":price_now,"price_before":price_before,"image":img}
cs.append(tmp)
except:
continue
content["contents"]=cs
return content
tables=tables
dfs=[]
for tb in tables:
content=etr(tb)
df_tmp=pd.DataFrame(data=content['contents'])
df_tmp['label']=content['label']
dfs.append(df_tmp)
df=pd.concat(dfs,ignore_index=True)

图片的处理
爬取下来的数据中,有df['image'] 以http://www.xhsd.cn//upload/2017/7/1500881045493.jpg 为例
['http://www.xhsd.cn//upload/2017/7/1500881045493.jpg', 'http://www.xhsd.cn//upload/20160701\\9787201077642.JPG', 'http://www.xhsd.cn//upload/20160621\\9787201088945.JPG', 'http://www.xhsd.cn//upload/2017/6/1498807359861.jpg']
下一张博客讲下载图片 和简单处理