刚开始接触网络爬虫,记录自己的学习历程。
开发环境:python 3.6 IDLE
爬取对象及任务:爬取学院网站上教师的信息,将教师照片保存在某一文件下。
url = 'http://cmee.nwafu.edu.cn/szdw/gjzcry/index.htm'
程序代码:
import requests
import bs4
import os
from bs4 import BeautifulSoup
import re
#获得url文本信息并返回
def getHTMLText(url):
try:
r = requests.get(url, timeout = 30)
r.raise_for_status()
r.encoding = r.apparent_encoding
return r.text
except:
return ""
#使用BeautifulSoup类进行解析,将a标签中的内容存入列表中
def fillName(ulist, html):
soup = BeautifulSoup(html, "html.parser")
for tag in soup.find_all('a'):
ulist.append([tag.string, tag.attrs['href']])
#获得每个教师的名字信息和href属性中的网站信息,并打印出来。可参考图1
def getName(ulist):
tplt = "{:^10}\t{:<50}"
print(tplt.format("姓名", "网址"))
for i in range(len(ulist)):
try:
u = ulist[i]
print(tplt.format(u[0], u[1]))
except:
continue
#获取href链接中 教师的照片,命名为教师的名字并保存
def getInfo(ulist):
root = "F://pics//"
for i in range(15,len(ulist)-1):
personinfo = ulist[i]
personname = personinfo[0]
personurl = personinfo[1]
path = root + personname +'.png'
personhtml = getHTMLText(personurl)
soup = BeautifulSoup(personhtml, "html.parser")
"""
print("教师名字:"+personname)
for tag in soup.find_all('p'):
print(tag.string)
"""
try:
match = re.search(r'src\=\"\.\.\/\.\.\/images\/content\/.*?g',personhtml)
strurl = match.group(0)
except:
continue
if not os.path.exists(root):
os.mkdir(root)
pictureurl = 'http://cmee.nwsuaf.edu.cn/i' + strurl.split('i')[-1]
r = requests.get(pictureurl)
with open(path, 'wb') as f:
f.write(r.content)
f.close()
def main():
uinfo = []
url = 'http://cmee.nwafu.edu.cn/szdw/gjzcry/index.htm'
html = getHTMLText(url)
fillName(uinfo, html)
getName(uinfo)
getInfo(uinfo)
main()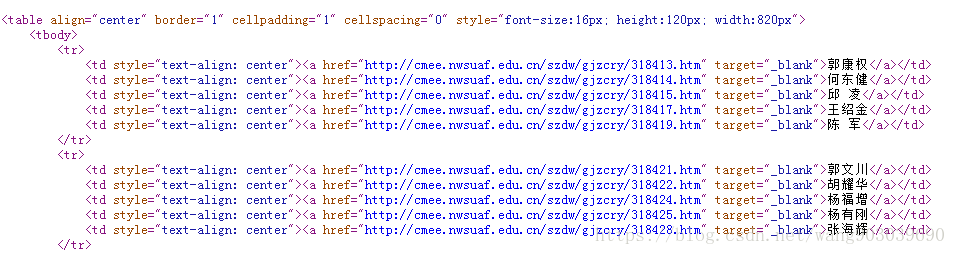
图1 ‘http://cmee.nwafu.edu.cn/szdw/gjzcry/index.htm’源代码
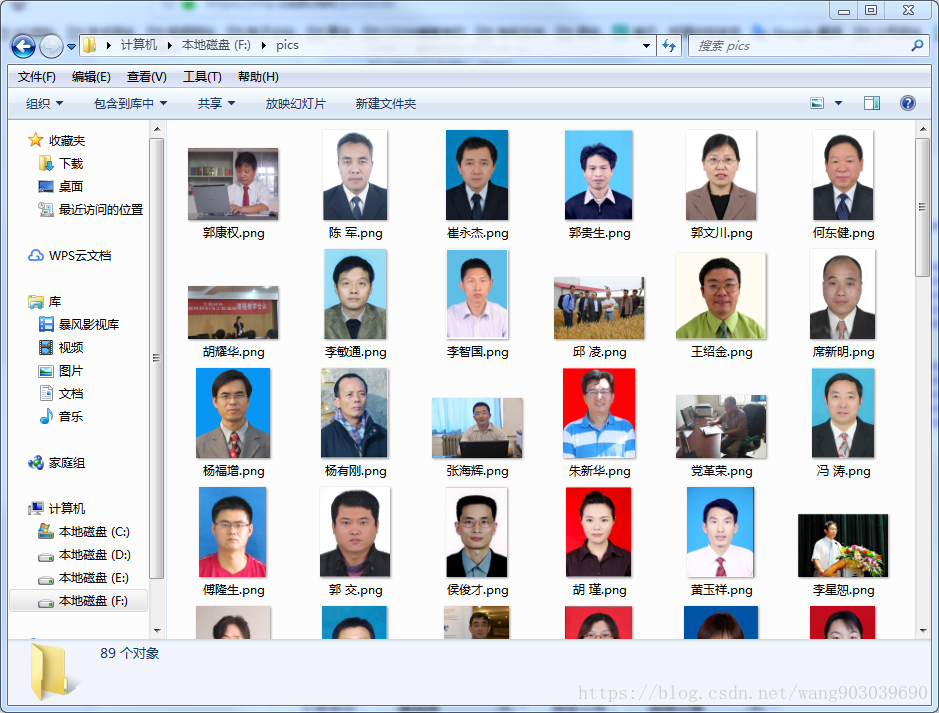
运行结果。
学习总结:requests库爬取信息速度和能力十分有限,本例代码通用性几乎为0,只是针对特定的url进行爬取,信息存在HTML页面中的固定url。