第一次第一次用MarkDown来写博客,先试试效果吧!
昨天2018俄罗斯世界杯拉开了大幕,作为一个伪球迷,当然也得为世界杯做出一点贡献啦。
于是今天就编写了一个爬虫程序将腾讯新闻下世界杯专题的相关新闻和链接提取出来,同时也再复习一下
Python爬虫类库的使用。
爬取前相关库文件的安装
1.python安装,如果还没有安装可以去Python官网去下载安装相应的版本,这里我使用的是Python3.6.1。
2.requests库安装,使用cmd命令打开命令行,接着
pip install requests,等待一些时间后安装就完成啦。同时这里不在介绍requests库的详细使用,如果想查看更多的使用,可以前往http://docs.python-requests.org/zh_CN/latest/user/quickstart.html进行学习。
3.bs4安装,这次使用到的解析工具是BeautifulSoup,所以在写代码前需要安装好,还是在命令行输入
pip install bs4进行安装。BeautifulSoup的学习可以前往https://www.crummy.com/software/BeautifulSoup/bs4/doc/index.zh.html。
网页分析
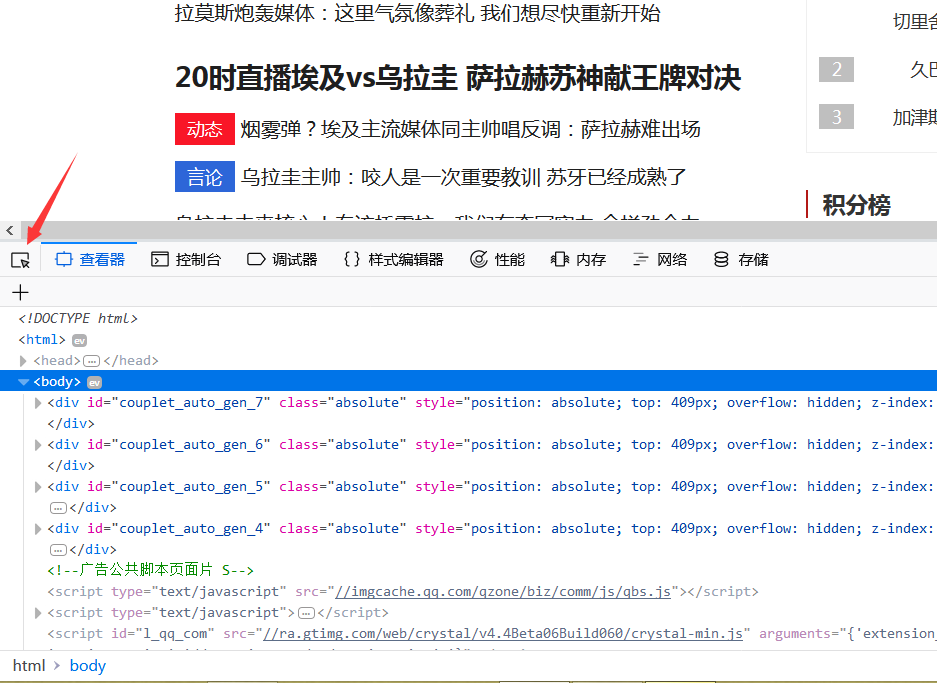
1.首先观察页面,找到我们想要提取的数据在哪。

2.接着打开F12开发者工具,点击下图所示的箭头再点击网页上的内容,查看它出现在真正网页的位置。

3.复制这则新闻的链接,查看网页源代码并Ctrl+F搜索该链接是否在网页源码中。
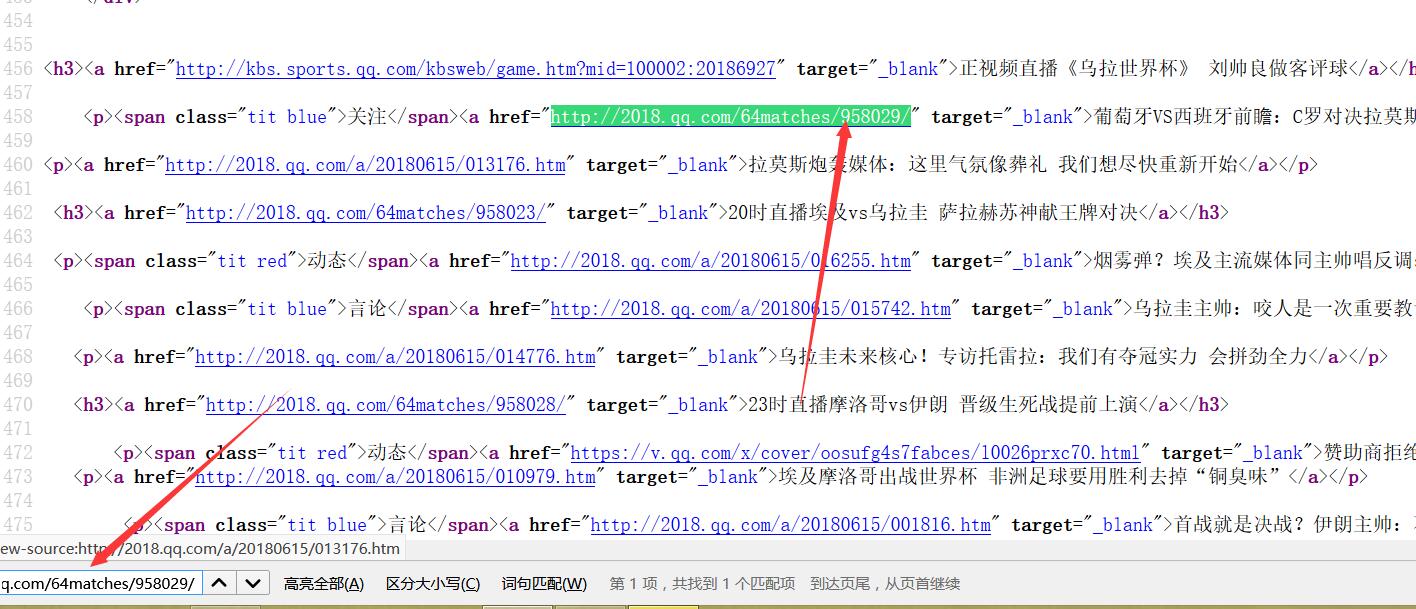
4.可以看到这个网页的新闻信息并没有通过其它方式来加载,而是处在网页的源代码中,这就为我们的提取省了不少时间。
5.返回到页面,查看网页代码结构可以发现所有的新闻都处于一个class为yaowen的div下的p标签内,我们只要能够提取出这些p标签,再从中得到a标签就可以得到我们想要的这个页面的新闻标题以及链接。
代码的编写
import requests
from bs4 import BeautifulSoup
import json
# 构造headers
headers = {
"User-Agent":"Mozilla/5.0 (Windows NT 6.3; WOW64; rv:60.0) Gecko/20100101 Firefox/60.0",
}
def get_html(url):
# 使用requests构造get请求
response = requests.get(url=url, headers=headers)
# 根据返回的状态来判断是否请求成功
if response.status_code == 200:
# 通过text属性来获取网页的源代码
html = response.text
print(html)
else:
print(response.status_code)
def main():
url = "http://2018.qq.com/"
html = get_html(url)
if __name__ == '__main__':
main()这里首先用一个get_html()函数来得到网页的源代码,执行后结果如下:

接下来使用parse_html()来对得到的源代码进行解析
def parse_html(html):
# 使用字典来保存
infos = {}
# 创建BeautifulSoup对象
soup = BeautifulSoup(html, 'lxml')
# 使用css选择器来选择出所有的a标签,返回一个列表
news = soup.select("div.yaowen a[href^='http://2018.qq.com/a/']")
# 遍历列表存入信息到字典
for new in news:
infos[new.get_text()] = new.get("href")
return infos执行结果如下,可以看到我们想要的该页面新闻标题以及新闻链接都提取下来了。

最后将得到的数据存入到文件中
def save_to_file(news):
# 将字典转化为字符串格式再存入文件中
news = json.dumps(news, ensure_ascii=False)
with open("news.txt", "w", encoding="utf-8") as f:
f.write(news)
print("保存至文件成功")打开news.txt文件,查看内容
