Hello,我是 Alex 007,为啥是007呢?因为叫 Alex 的人太多了,再加上每天007的生活,Alex 007就诞生了。
这几天一直在练车,只能在中间休息的时候写一写博客,可怜去年报的名到现在还没有拿到小本本,当然练车只是副技能,主技能还是coding,不断学习才能不被淘汰。
最近在学爬虫的 scrapy 框架,以前虽然拿 GoLang 玩过爬虫,可惜没有太深入,这次拿 Python 好好学一学。
学习爬虫过程中的代码都放在了GitHub上:https://github.com/koking0/Spider
小生才疏学浅,如有谬误,恭请指正。
文章目录
一、初探 Scrapy
先来看一下官网的定义:
Scrapy is a fast high-level web crawling and web scraping framework, used to crawl websites and extract structured data from their pages.
Scrapy是一个快速的高级web抓取框架,用于抓取网站和从网页中提取结构化数据。
It can be used for a wide range of purposes, from data mining to monitoring and automated testing.
它可以用于广泛的用途,从数据挖掘到监控和自动化测试。

没学习过爬虫和框架的人可能就懵逼了,不知道爬虫是什么的可以先花两分钟看一下网络机器人之爬虫这篇文章,不知道框架是什么的,我简单说一下,大佬可以屏幕向下滚动200px。
1.什么是框架?
所谓框架,顾名思义,就是一个具有很强通用性并且集成了很多功能的项目模板,可以应用在不同的项目需求中。
也就是说,框架是别人造好的轮子,一个项目的半成品,我们只需要拿过来编写自己的业务逻辑填空即可。
2.怎么学习框架?
对于刚接触编程或者小白来讲,一个新的框架只需要掌握该框架的作用及其各个功能的使用即可。
说白了就是会用就行,对于框架的底层实现和原理,在逐步进阶中慢慢深入即可。
Scrapy 可以说在爬虫界是非常出名也非常强悍的,为爬取网站结构性数据而生,其内部集成了诸如高性能异步下载、队列、分布式、持久化等功能,可以说是爬虫利器。
1.Scrapy 的安装
- Windows 操作系统
四行代码,复制粘贴,简单粗暴。
pip install wheel
pip install twisted
pip install pywin32
pip install scrapy
如果安装太慢的话可以用阿里云镜像。
pip install -i http://mirrors.aliyun.com/pypi/simple --trusted-host mirrors.aliyun.com twisted
pip install -i http://mirrors.aliyun.com/pypi/simple --trusted-host mirrors.aliyun.com pywin32
pip install -i http://mirrors.aliyun.com/pypi/simple --trusted-host mirrors.aliyun.com scrapy
简单解释一下除了 scrapy 之外的两个东西是啥:
- twisted
Twisted 是用 Python 实现的基于事件驱动的网络引擎框架,提供了允许阻塞行为但不会阻塞代码执行的方法,比较适合异步的程序。
关于 Twisted 异步与多线程的比较可以参考:Scrapy与Twisted
- pywin32
pywin32 主要的作用是方便 Python 开发者快速调用 Windows API的一个模块库。
也就是说,twisted 和 pywin32 可以配合起来让 scrapy 的异步爬取更加丝滑顺畅,哈哈,开玩笑,没这两个库 scrapy 根本安装不上,三个步骤一步都不能报错。
- Linux 操作系统
pip install scrapy
- Mac 操作系统
pip install scrapy
安装完成后可以测试一下安装结果,在终端输入 scrapy,执行后没有报错即安装成功:
(venv) G:\Python\Spider>scrapy
Scrapy 2.0.1 - no active project
Usage:
scrapy <command> [options] [args]
Available commands:
bench Run quick benchmark test
fetch Fetch a URL using the Scrapy downloader
genspider Generate new spider using pre-defined templates
runspider Run a self-contained spider (without creating a project)
settings Get settings values
shell Interactive scraping console
startproject Create new project
version Print Scrapy version
view Open URL in browser, as seen by Scrapy
[ more ] More commands available when run from project directory
Use "scrapy <command> -h" to see more info about a command
2.第一个 scrapy 项目
使用 scrapy 大体上可以分为5个步骤,这里说的可不是代码的编写,而是从项目的创建到执行需要5步:
- 创建项目
scrapy startproject firstScrapy
- 进入项目目录
cd firstScrapy
- 创建爬虫文件
scrapy genspider baiDuwww.baidu.com
- 编写代码
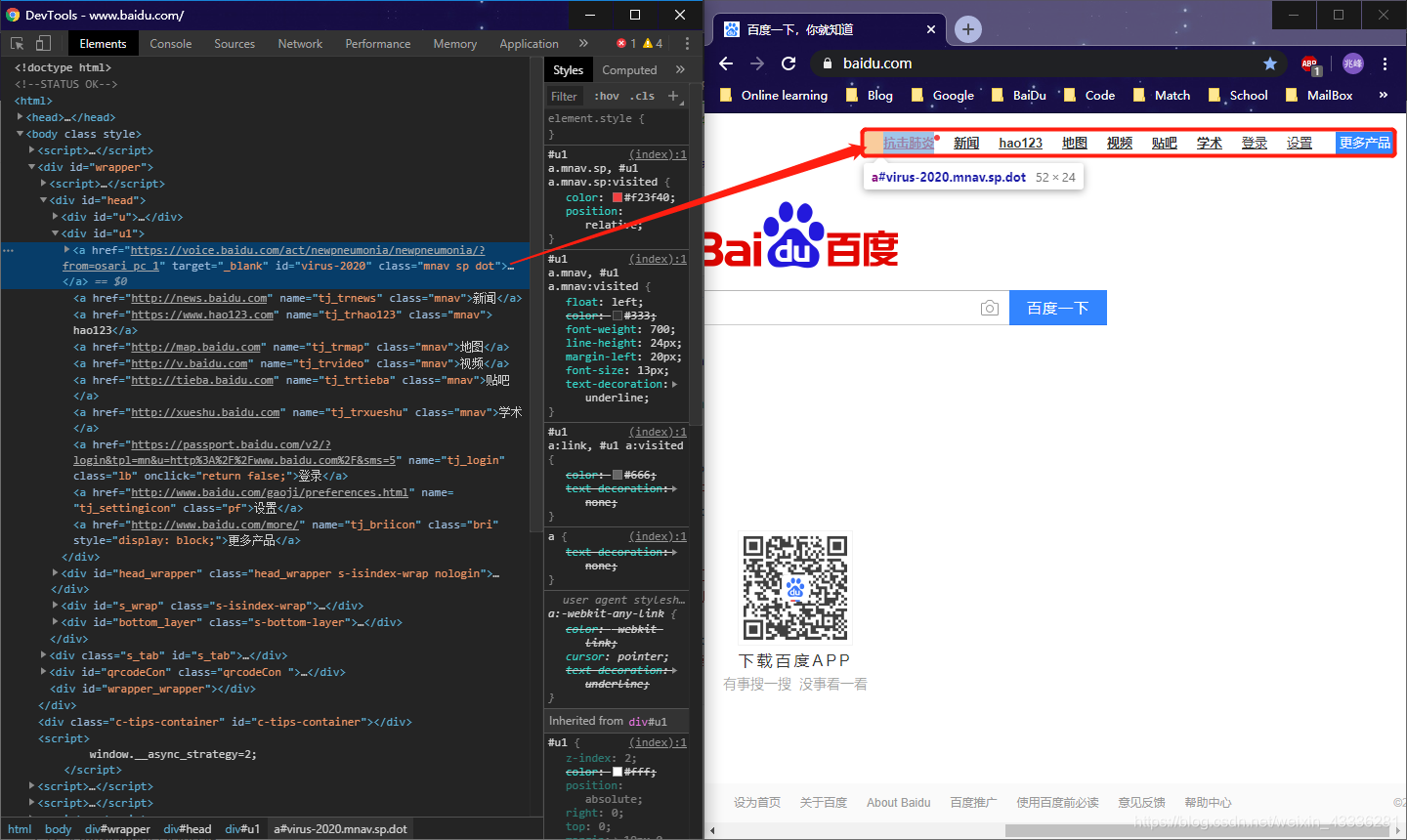
这里简单做一个爬取百度首页顶部菜单的爬虫。
# baiDu.py
# -*- coding: utf-8 -*-
import scrapy
class BaiduSpider(scrapy.Spider):
# 爬虫应用名称
name = 'baiDu'
# 允许爬取的域名,如果不是该域名下的 url 则不会爬取
allowed_domains = ['www.baidu.com']
# 起始爬取 url
start_urls = ['http://www.baidu.com/']
# 将爬取起始 url 的结果作为 response 参数传入该函数,函数的返回值必须是可迭代对象或 null
def parse(self, response):
# 字符串类型响应对象内容
# print(response.text)
# 字节类型响应对象内容
# print(response.body)
# xpath 为 response 的方法,可以直接写 xpath 表达式
aList = response.xpath('//*[@id="u1"]/a')
for item in aList:
name = item.xpath('.//text()')[0].extract()
url = item.xpath('./@href')[0].extract()
print(name, url)
# settings.py
from fake_useragent import UserAgent
# ......
# Crawl responsibly by identifying yourself (and your website) on the user-agent
# 设置全局 UA 伪装
user_agent = UserAgent()
USER_AGENT = user_agent.random
# Obey robots.txt rules
# 忽略 robots 协议
ROBOTSTXT_OBEY = False
- 执行项目
scrapy crawl baiDu
如果你的代码逻辑没有出错的话,可以看到如下结果:
(venv) G:\Python\Spider\6.scrapy框架\firstScrapy>scrapy crawl baiDu
2020-04-09 21:48:46 [scrapy.utils.log] INFO: Scrapy 2.0.1 started (bot: firstScrapy)
2020-04-09 21:48:46 [scrapy.utils.log] INFO: Versions: lxml 4.5.0.0, libxml2 2.9.5, cssselect 1.1.0, parsel 1.5.2, w3lib 1.21.0, Twisted 20.3.0, Py
thon 3.7.4 (default, Aug 9 2019, 18:34:13) [MSC v.1915 64 bit (AMD64)], pyOpenSSL 19.1.0 (OpenSSL 1.1.1f 31 Mar 2020), cryptography 2.9, Platform
Windows-10-10.0.18362-SP0
2020-04-09 21:48:46 [scrapy.utils.log] DEBUG: Using reactor: twisted.internet.selectreactor.SelectReactor
2020-04-09 21:48:46 [scrapy.crawler] INFO: Overridden settings:
{'BOT_NAME': 'firstScrapy',
'EDITOR': '~/AppData/Roaming/GitPad/GitPad.exe',
'NEWSPIDER_MODULE': 'firstScrapy.spiders',
'SPIDER_MODULES': ['firstScrapy.spiders'],
'USER_AGENT': 'Mozilla/5.0 (X11; CrOS i686 3912.101.0) AppleWebKit/537.36 '
'(KHTML, like Gecko) Chrome/27.0.1453.116 Safari/537.36'}
2020-04-09 21:48:46 [scrapy.extensions.telnet] INFO: Telnet Password: 2ca333daee7184fb
2020-04-09 21:48:46 [scrapy.middleware] INFO: Enabled extensions:
['scrapy.extensions.corestats.CoreStats',
'scrapy.extensions.telnet.TelnetConsole',
'scrapy.extensions.logstats.LogStats']
2020-04-09 21:48:47 [scrapy.middleware] INFO: Enabled downloader middlewares:
['scrapy.downloadermiddlewares.httpauth.HttpAuthMiddleware',
'scrapy.downloadermiddlewares.downloadtimeout.DownloadTimeoutMiddleware',
'scrapy.downloadermiddlewares.defaultheaders.DefaultHeadersMiddleware',
'scrapy.downloadermiddlewares.useragent.UserAgentMiddleware',
'scrapy.downloadermiddlewares.retry.RetryMiddleware',
'scrapy.downloadermiddlewares.redirect.MetaRefreshMiddleware',
'scrapy.downloadermiddlewares.httpcompression.HttpCompressionMiddleware',
'scrapy.downloadermiddlewares.redirect.RedirectMiddleware',
'scrapy.downloadermiddlewares.cookies.CookiesMiddleware',
'scrapy.downloadermiddlewares.httpproxy.HttpProxyMiddleware',
'scrapy.downloadermiddlewares.stats.DownloaderStats']
2020-04-09 21:48:47 [scrapy.middleware] INFO: Enabled spider middlewares:
['scrapy.spidermiddlewares.httperror.HttpErrorMiddleware',
'scrapy.spidermiddlewares.offsite.OffsiteMiddleware',
'scrapy.spidermiddlewares.referer.RefererMiddleware',
'scrapy.spidermiddlewares.urllength.UrlLengthMiddleware',
'scrapy.spidermiddlewares.depth.DepthMiddleware']
2020-04-09 21:48:47 [scrapy.middleware] INFO: Enabled item pipelines:
[]
2020-04-09 21:48:47 [scrapy.core.engine] INFO: Spider opened
2020-04-09 21:48:47 [scrapy.extensions.logstats] INFO: Crawled 0 pages (at 0 pages/min), scraped 0 items (at 0 items/min)
2020-04-09 21:48:47 [scrapy.extensions.telnet] INFO: Telnet console listening on 127.0.0.1:6023
2020-04-09 21:48:47 [scrapy.downloadermiddlewares.redirect] DEBUG: Redirecting (302) to <GET https://www.baidu.com/> from <GET http://www.baidu.com
/>
2020-04-09 21:48:47 [scrapy.core.engine] DEBUG: Crawled (200) <GET https://www.baidu.com/> (referer: None)
抗击肺炎 https://voice.baidu.com/act/newpneumonia/newpneumonia/?from=osari_pc_1
新闻 http://news.baidu.com
hao123 https://www.hao123.com
地图 http://map.baidu.com
视频 http://v.baidu.com
贴吧 http://tieba.baidu.com
学术 http://xueshu.baidu.com
登录 https://passport.baidu.com/v2/?login&tpl=mn&u=http%3A%2F%2Fwww.baidu.com%2F&sms=5
设置 http://www.baidu.com/gaoji/preferences.html
更多产品 http://www.baidu.com/more/
2020-04-09 21:48:47 [scrapy.core.engine] INFO: Closing spider (finished)
2020-04-09 21:48:47 [scrapy.statscollectors] INFO: Dumping Scrapy stats:
{'downloader/request_bytes': 732,
'downloader/request_count': 2,
'downloader/request_method_count/GET': 2,
'downloader/response_bytes': 53325,
'downloader/response_count': 2,
'downloader/response_status_count/200': 1,
'downloader/response_status_count/302': 1,
'elapsed_time_seconds': 0.491685,
'finish_reason': 'finished',
'finish_time': datetime.datetime(2020, 4, 9, 13, 48, 47, 901362),
'log_count/DEBUG': 2,
'log_count/INFO': 10,
'response_received_count': 1,
'scheduler/dequeued': 2,
'scheduler/dequeued/memory': 2,
'scheduler/enqueued': 2,
'scheduler/enqueued/memory': 2,
'start_time': datetime.datetime(2020, 4, 9, 13, 48, 47, 409677)}
2020-04-09 21:48:47 [scrapy.core.engine] INFO: Spider closed (finished)
scrapy 给我们输出了很多很多东西,我们的打印结果被放在了中间,其它的内容其实是日志信息,scrapy 帮我们自动生成了日志,如果你觉得碍眼的话,可以通过 settings.py 文件中的设置只保留错误信息:
LOG_LEVEL = 'ERROR'
二、基本操作
接下来了解一下 scrapy 框架的一些基本操作,比如爬取数据的持久化存储啦,对网站的全站爬取啦还有图片下载等功能。
1.持久化存储
爬取到的数据只有保存到本地的电脑上才是自己的,不然只在内存里,用完就没了。
(1)基于终端指令的持久化存储
在前边的小试牛刀中我们可以看到控制台的输出,其实基于终端指令的持久化存储就是将终端的输出结果重定向到一个本地文件中。
使用基于终端指令的持久化存储必须保证爬虫文件中的 parse 方法中有可迭代对象返回,通常是列表或者字典。
我们把爬取百度顶部菜单栏的爬虫 parse 方法升级一下:
def parse(self, response):
# xpath 为 response 的方法,可以直接写 xpath 表达式
aList = response.xpath('//*[@id="u1"]/a')
data = {}
for item in aList:
name = item.xpath('.//text()')[0].extract()
url = item.xpath('./@href')[0].extract()
data[name] = url
return data
然后在 settings.py 文件中写一下文件编码的配置,保证使用的是 utf-8 编码方式:
FEED_EXPORT_ENCODING = 'UTF8'
接下来,在启动项目的时候可以用如下指令:
scrapy crawl baiDu -o baidu.json
这样就可以将爬取的结果持久化存储到 baidu.json 文件中:

类似的方法还有:
scrapy crawl spiderName-o xxxx.txt
scrapy crawl spiderName-o xxxx.xml
scrapy crawl spiderName-o xxxx.csv
(2)基于管道的持久化存储
使用终端保存文件的方式在 Windows 操作系统貌似不是很常见,Linux 下倒是正常操作。
scrapy 框架中集成了高效、便捷的持久化存储功能,并且在创建项目的时候也帮我们自动创建好了文件:
1.items.py:数据结构模板,定义存储数据的字段
2.pipelines.py:管道文件,接收数据(item)进行持久化存储
基于管道的持久化存储流程:
- 将爬虫文件爬取到的数据封装到 items 对象中
items.py
# -*- coding: utf-8 -*-
# Define here the models for your scraped items
#
# See documentation in:
# https://docs.scrapy.org/en/latest/topics/items.html
import scrapy
class FirstscrapyItem(scrapy.Item):
# define the fields for your item here like:
name = scrapy.Field() # 存储菜单名
url = scrapy.Field() # 存储菜单 url
pass
- 使用 yield 将 items 对象提交给 pipelines 管道持久化存储
baiDu.py
def parse(self, response):
# xpath 为 response 的方法,可以直接写 xpath 表达式
aList = response.xpath('//*[@id="u1"]/a')
for data in aList:
# 将解析到的数据封装到 items 对象中
item = FirstscrapyItem()
item["name"] = data.xpath('.//text()')[0].extract()
item["url"] = data.xpath('./@href')[0].extract()
yield item
- 管道文件中的 process_item 方法接收并处理爬虫文件提交过来的 item 对象
pipelines.py
# -*- coding: utf-8 -*-
# Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: https://docs.scrapy.org/en/latest/topics/item-pipeline.html
class FirstscrapyPipeline(object):
def __init__(self):
self.fp = None
def open_spider(self, spider):
"""开启爬虫时执行一次"""
print("爬虫启动!")
self.fp = open("data.txt", "w")
def process_item(self, item, spider):
self.fp.write(f'{item["name"]}:{item["url"]}\n')
return item # 注意:一定要有 return item 这一步
def close_spider(self, spider):
"""结束爬虫时执行一次"""
self.fp.close()
print("爬虫结束!")
- 配置文件 settings.py 中开启管道
取消两行注释即可,后边的300表示优先级,值越小优先级越高:
# Configure item pipelines
# See https://docs.scrapy.org/en/latest/topics/item-pipeline.html
ITEM_PIPELINES = {
'firstScrapy.pipelines.FirstscrapyPipeline': 300,
}
如此这般,当我们再次执行 scrapy 项目的时候:
(venv) G:\Python\Spider\6.scrapy框架\firstScrapy>scrapy crawl baiDu
爬虫启动!
爬虫结束!
就会生成一个 data.txt 文件:
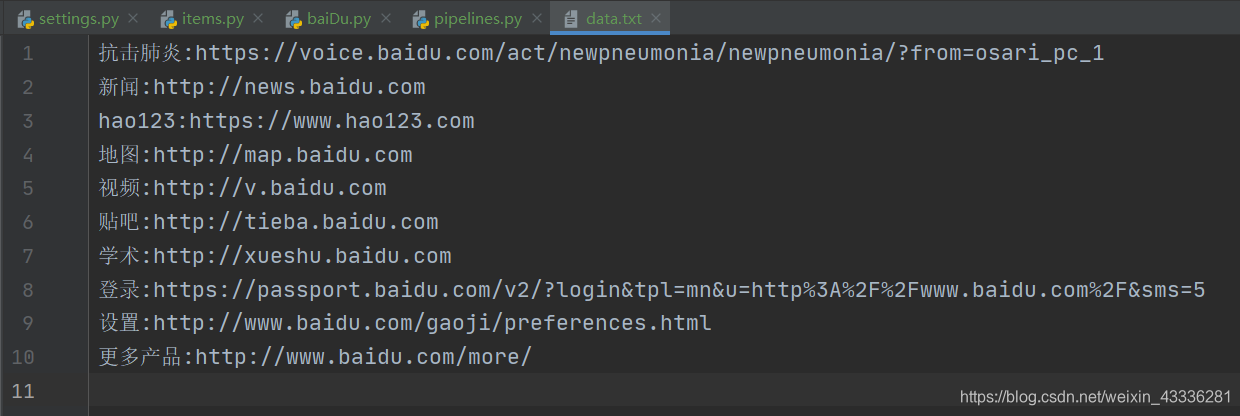
如果你想将爬取到的数据一式两份,一份存储到磁盘文件中,一份存储到数据库中,那么就需要在 pipelines.py 文件中再定制一个存储到数据库的管道类:
class DataBasePipeline(object):
def __init__(self):
self.connect, self.cursor = None, None
def open_spider(self, spider):
self.connect = pymysql.Connect(host="127.0.0.1", port=3306, user="root", password="20001001", db="test", charset="utf8")
def process_item(self, item, spider):
self.cursor = self.connect.cursor()
try:
sql = 'INSERT INTO scrapy1 VALUES ("%s", "%s");' % (item["name"], item["url"])
self.cursor.execute(sql)
self.connect.commit()
except Exception as e:
print(e)
self.connect.rollback()
return item # 注意:一定要有 return item 这一步
def close_spider(self, spider):
self.connect.close()
self.cursor.close()
然后在 settings.py 文件中注册该类:
ITEM_PIPELINES = {
'firstScrapy.pipelines.FirstscrapyPipeline': 300,
'firstScrapy.pipelines.DataBasePipeline': 301,
}
这样就可以将爬取到的数据存储到数据库中了:

2.全站数据爬取
现在大部分的网站展示的数据都进行了分页操作,因此将所有页码对应的页面进行爬取变成了普遍的要求,scrapy 也帮我们定制好了全站数据爬取的功能。
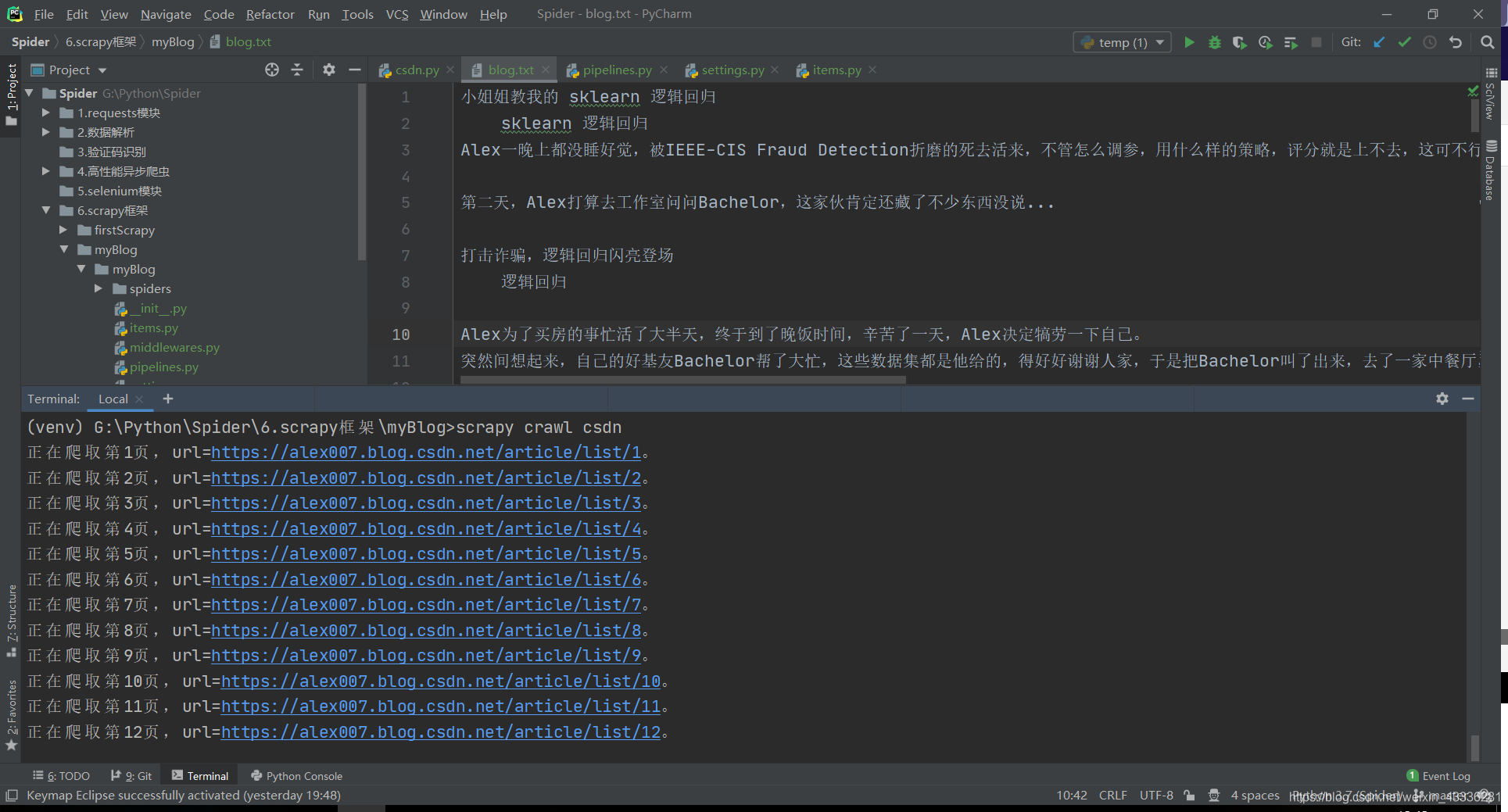
以我自己的 CSDN 博客为例,我现在想把所有我写博客的标题和摘要爬取下来:
- Elements 分析

每一篇博客的盒子 xpath 表达式://*[@id="mainBox"]/main/div[2]/div
博客名称 xpath 表达式:./h4/a/text()
博客摘要 xpath 表达式:./p/a/text()
- Page 分析
第一页:https://alex007.blog.csdn.net/article/list/1
第二页:https://alex007.blog.csdn.net/article/list/2
第三页:https://alex007.blog.csdn.net/article/list/3
……
第 n 页:https://alex007.blog.csdn.net/article/list/n
在 Scrapy 中可以使用 Request 方法手动对每一个页面发起请求。
import time
import scrapy
from myBlog.items import MyblogItem
class CsdnSpider(scrapy.Spider):
name = 'csdn'
start_urls = ['https://alex007.blog.csdn.net/']
pageNumber = 1
pageUrl = 'https://alex007.blog.csdn.net/article/list/%d'
def parse(self, response):
print(f"正在爬取第{self.pageNumber}页,url={self.pageUrl % self.pageNumber}。")
divList = response.xpath('//*[@id="mainBox"]/main/div[2]/div')
for div in divList:
item = MyblogItem()
item["name"] = ("".join(div.xpath('.//h4/a/text()').extract())).strip("\n").strip()
item["content"] = ("".join(div.xpath('.//p/a/text()').extract())).strip("\n").strip()
yield item
if self.pageNumber < 21:
self.pageNumber += 1
time.sleep(1)
url = format(self.pageUrl % self.pageNumber)
# 递归爬起数据,callback 参数为回调函数
yield scrapy.Request(url=url, callback=self.parse)
如此这般,就可以将我的所有博客文章题目和摘要都爬取下来了:
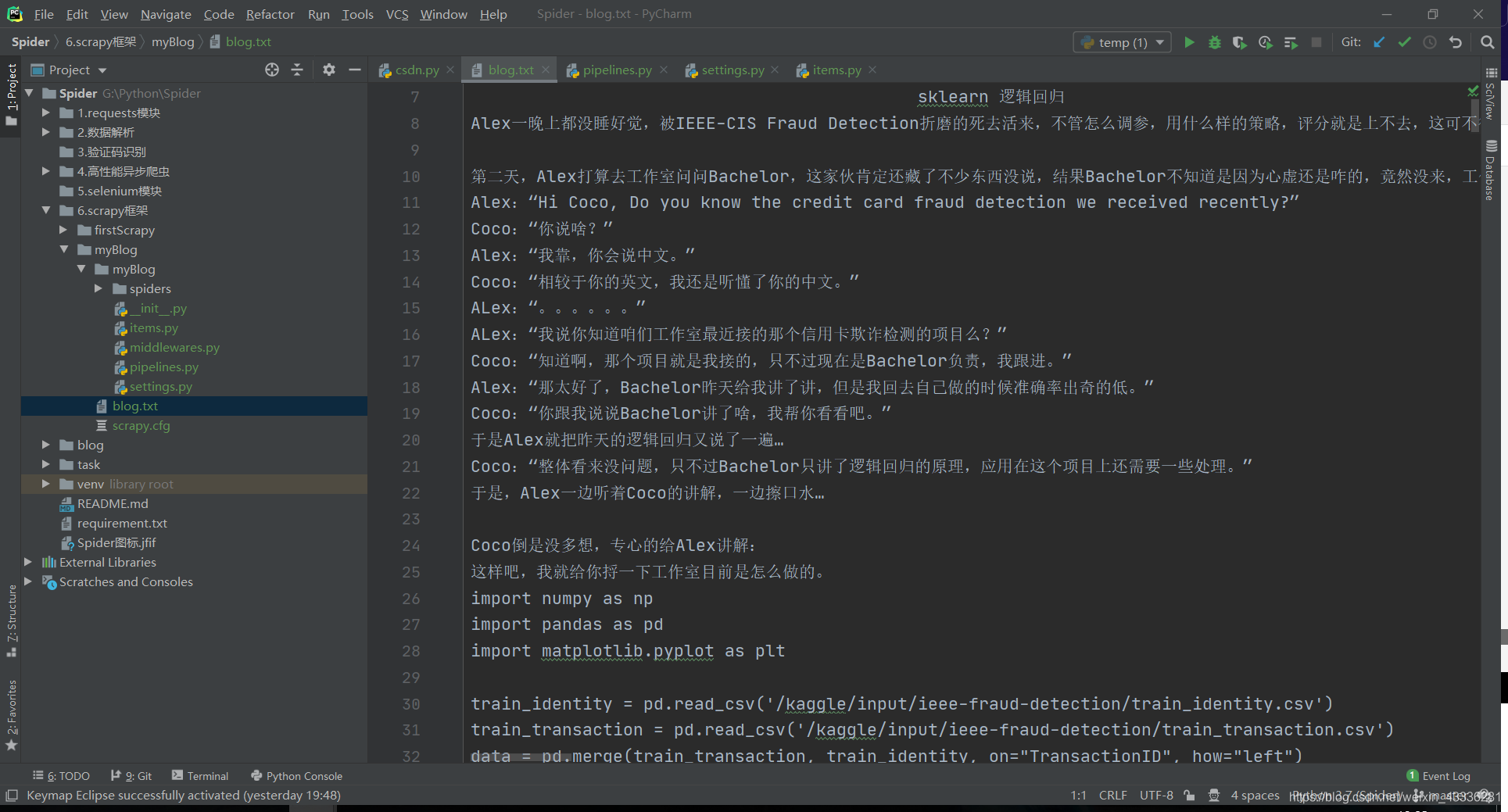
请求传参
如果我现在的需求升级一下,对于每一篇博客,摘要不要了,替换为博客文章全部内容,这样的话,我们就得通过在一级页面拿到 url 访问二级页面,这时候就需要用到请求传参。
也就是说,当我们使用爬虫想要爬取的数据没有存在于同一张页面的时候,则必须使用请求传参。
import time
import scrapy
from myBlog.items import MyblogItem
class CsdnSpider(scrapy.Spider):
name = 'csdn'
start_urls = ['https://alex007.blog.csdn.net/']
pageNumber = 1
pageUrl = 'https://alex007.blog.csdn.net/article/list/%d'
def parse(self, response):
print(f"正在爬取第{self.pageNumber}页,url={self.pageUrl % self.pageNumber}。")
divList = response.xpath('//*[@id="mainBox"]/main/div[2]/div')
for div in divList:
item = MyblogItem()
item["name"] = ("".join(div.xpath('.//h4/a/text()').extract())).strip("\n").strip()
contentUrl = div.xpath('.//h4/a/@href').extract_first()
print(f"正在爬取第文章{item['name']},url={contentUrl}。")
time.sleep(2)
yield scrapy.Request(url=contentUrl, callback=self.parseContent, meta={'item': item})
if self.pageNumber < 2:
self.pageNumber += 1
url = format(self.pageUrl % self.pageNumber)
# 递归爬起数据,callback 参数为回调函数
yield scrapy.Request(url=url, callback=self.parse)
def parseContent(self, response):
item = response.meta["item"]
item["content"] = "".join(response.xpath('//*[@id="content_views"]//text()').extract())
yield item
我们通过meta={'item': item}将item传递给处理二级页面函数,然后直接在其中yield item就可以将结果传递给管道函数,爬取结果如下:
3.图片下载
图片下载也是爬虫的基本需求,那么 Scrapy 当然也帮我们封装好了一个专门基于图片请求和持久化存储的管道类 ImagesPipeline。
- 在爬虫文件中解析出图片的地址
# -*- coding: utf-8 -*-
import scrapy
from beauty.items import BeautyItem
class ImagesSpider(scrapy.Spider):
name = 'images'
start_urls = ['http://wuming3175.lofter.com//']
pageNumber = 1
pageUrl = "http://wuming3175.lofter.com/?page=%d"
def parse(self, response):
divList = response.xpath('/html/body/div[3]/div')
for div in divList:
item = BeautyItem()
imageSrc = div.xpath('.//div[2]/div[1]/div[1]/a/img/@src').extract_first()
if imageSrc:
item["image_urls"] = imageSrc.split("?")[0]
yield item
if self.pageNumber < 22:
self.pageNumber += 1
url = format(self.pageUrl % self.pageNumber)
yield scrapy.Request(url=url, callback=self.parse)
2.使用 ImagesPipeline 类
class BeautyImagesPipeline(ImagesPipeline):
def get_media_requests(self, item, info):
"""用于请求方法"""
print(f'开始下载{item["image_urls"]}')
yield scrapy.Request(url=item["image_urls"])
def file_path(self, request, response=None, info=None):
"""指定文件存储路径"""
return request.url.split('/')[-1]
def item_completed(self, results, item, info):
return item # 该返回值会传递给下一个即将被执行的管道类
- 在 settings.py 文件中配置管道和图片存储路径
ROBOTSTXT_OBEY = False
LOG_LEVEL = 'ERROR'
# ......
IMAGES_STORE = "./images"
ITEM_PIPELINES = {
'beauty.pipelines.BeautyImagesPipeline': 300,
}
好了,关于 Scrapy 的入门就先讲到这里,再写多了看着都累,如果还想看可以点赞、收藏+关注哦。
写在最后:
小生才疏学浅,如有谬误,恭请指正。

