安装scrapy
解决方案
通过在https://www.lfd.uci.edu/~gohlke/pythonlibs/#twisted,然后下载:

CP后是python 版本,32或者64是windows版本
我使用的Python3.6,win10 64位,win+r,cmd,跳转文件保存目录下执行
pip3 install Twisted‑18.9.0‑cp36‑cp36m‑win_amd64.whl
成功后继续pip install scrapy即可
Scrapy架构图:
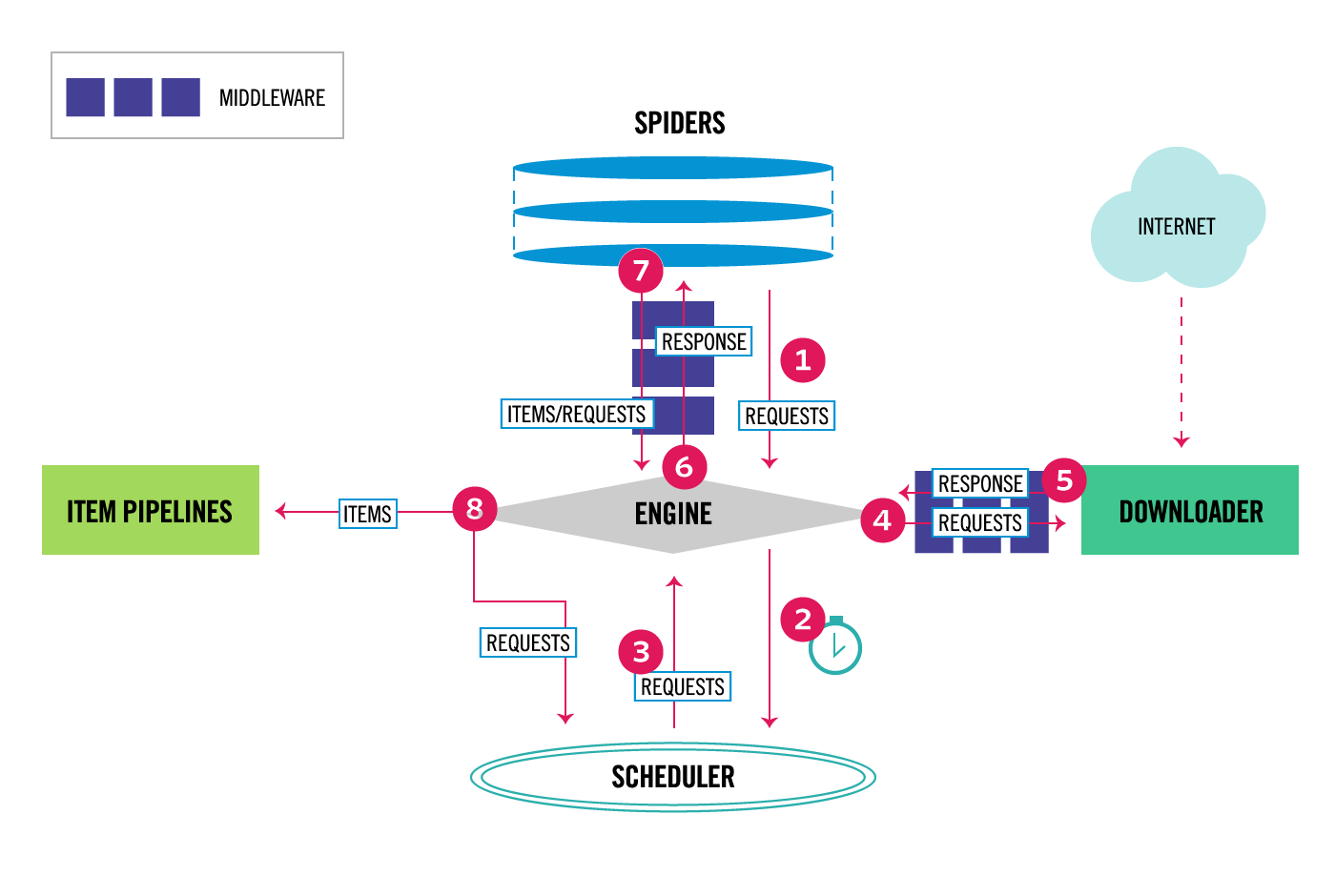
Scrapy Engine(引擎):负责Spider, ItemPipeline, Dowmloads, Scheduler 中间件的通讯, 信号,数据的传递等.
Scheduler(调度器): 他负责接受引擎发过来的Request请求,并按照一定的方式进行整理排序,入队,当引擎需要时,交还给引擎.
Downloads(下载器):
Spider(爬虫):
Item Pipeline(管道):
Downloads Middlewares(下载中间件):
Spider Middlewares(Spider中间件):
制作Scrapy爬虫一共需要四步:
新建项目: scrapy startproject
明确目标: 编写items.py
制作爬虫: spider/xxspider.py
存储内容: