在实际工作中,我们一定遇到过在字符串中查找子字符串的需求。很多编程语言的字符串数据类型都提供了方便的方法。比如Python中的in、find(),Java中的indexOf()。
那如果我们自己实现一个字符串查找算法,该如何做呢?字符串匹配算法很多,这篇文章介绍两种比较简单的、好理解的算法,它们分别是:BF 算法和 RK 算法。这两种算法,都是单模式串匹配的算法,也就是在一个主串中查找一个模式串。
BF 算法
BF 算法中的 BF 是 Brute Force 的缩写,中文叫作暴力匹配算法,也叫朴素匹配算法
。从名字上大家可以感觉到,这个算法应该是很暴力、很直接,所有人都能理解的算法。
直接借助极客时间《数据结构与算法之美》里面的一个图片,来感受一下它有多么直接、逻辑多么简单。
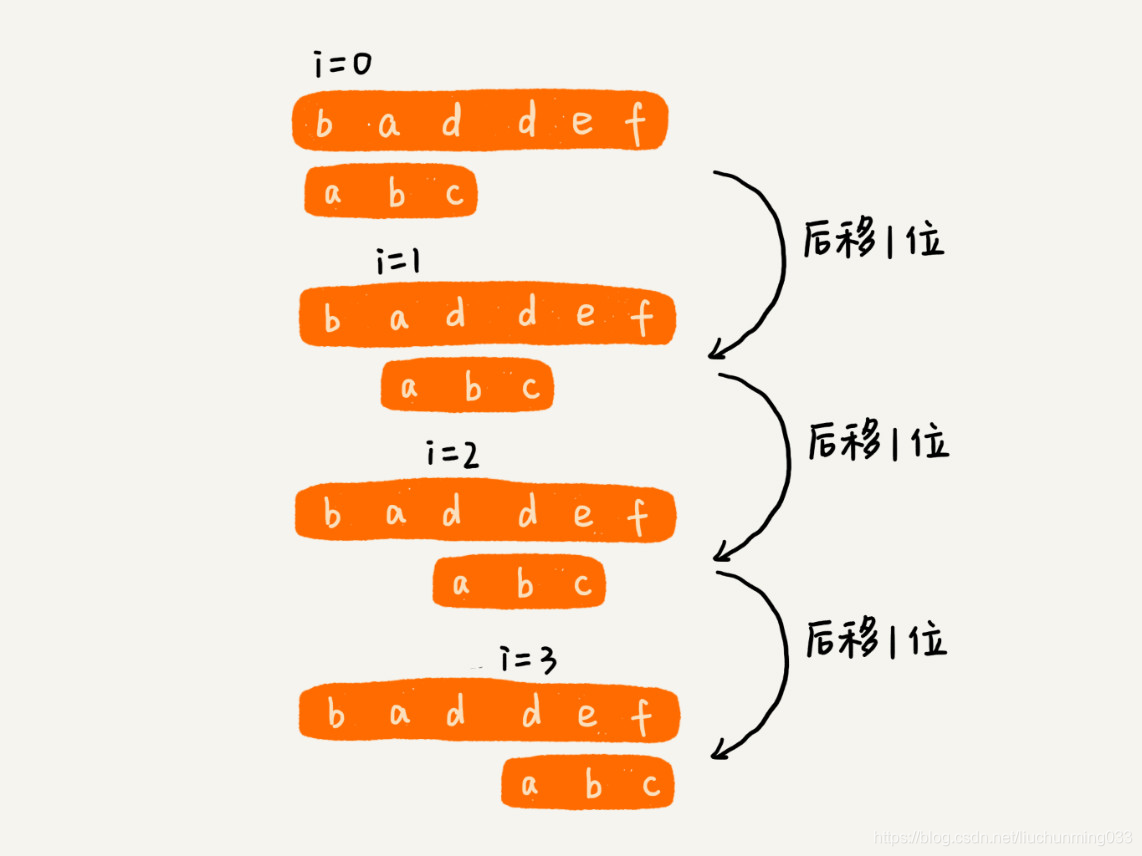
在这张图片中,主串baddef,长度记作n,模式串abc,长度记作 m。在主串中,从位置 0开始到n-m为止,长度为 m 的 n-m+1 个子串中,看有没有能跟模式串匹配的。如果有,我们记录主串下标i。
可以看到,BF算法思想简单,代码实现也会非常简单,简单意味着不容易出错,在工程实践中应用还是挺广泛的。另外,在工程实践大部分情况下,模式串和主串的长度都不会太长,而且每次模式串与主串中的子串匹配的时候,当中途遇到不能匹配的字符的时候,就可以就停止了,不需要把 m 个字符都比对一下。BF 算法虽然最坏的时间复杂度是O(m*n),但是这种最坏情况很少发生。
上面已经把算法逻辑讲清楚了,为了代码实现,我们再更加细致的分解一下具体的匹配比较动作。
第一轮,我们从主串的位置0开始,把主串和模式串的字符逐个比较:
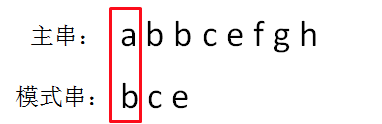
显然,主串的首位字符是a,模式串的首位字符是b,两者并不匹配。
第二轮,我们把模式串后移一位,从主串的第二位开始,把主串和模式串的字符逐个比较:
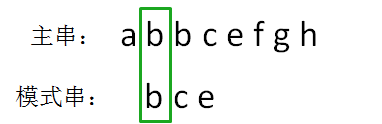
主串的第二位字符是b,模式串的第一位字符也是b,两者匹配,继续比较:
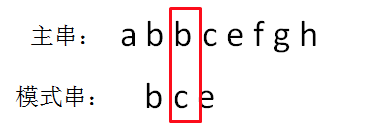
主串的第三位字符是b,模式串的第二位字符是c,两者并不匹配。
第三轮,把模式串再次后移一位,从主串的第三位开始,把主串和模式串的字符逐个比较:
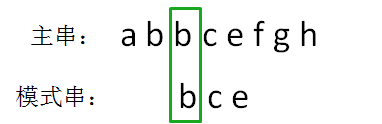
主串的第三位字符是b,模式串的第一位字符也是b,两者匹配,继续比较。
主串的第四位字符是c,模式串的第二位字符也是c,两者匹配,继续比较。
主串的第五位字符是e,模式串的第三位字符也是e,两者匹配,至此,模式串的每一个字符都与主串的子串中每一个字符匹配了。
由此得到结果,模式串 bce 是主串 abbcefgh 的子串,在主串第一次出现的位置下标是 2。如果只想找到主串的一个位置,那么代码就可以结束了。如果想在主串中找到更多的子串,还可以继续按照前面的逻辑寻找。
将上面的步骤转换成代码如下:
def brute_force_string_match(text, pattern):
m = len(pattern)
n = len(text)
for i in range(0, n - m + 1): # 模式串最大需要在主串中进行n-m+1个子串的比较
# +1 because range(0,1) is 1 , But we want it to include i at
j = 0 # 从模式串位置0开始
while j < m and pattern[j] == text[i + j]: # 模式串还没到最后一个字符,并且pattern[j] 与 text[i + j]匹配
print(j)
j = j + 1 # 比较模式串下一个字符
if j == m: # 注意这里是m,不是m-1,因为上面while循环最后j被加了1
return i
return -1
if __name__ == '__main__':
text = "abbcefgh"
pattern = "bce"
print(brute_force_string_match(text, pattern))
RK 算法
前面说到,BF 算法极端情况的时间复杂度是O(mn)。来看一个例子:

这个情况,比较过程如下:

两个字符串在每一轮都需要白白比较4次,显然非常浪费。这就是BF 算法最坏的情况了,时间复杂度是O(mn)。
聪明的计算机行业前辈 Rabin 和 Karp 发命令一种基于Hash算法的高效匹配算法。后人把他们发明的这个算法叫做 RK 算法。
RK 算法的思路是这样的:我们通过Hash算法对主串中的 n-m+1 个子串分别求hash值,然后逐个与模式串的hash值比较大小。如果某个子串的哈希值与模式串的hash值相等,那就说明对应的子串和模式串 可能 匹配了(有可能哈希冲突)。这时,再逐个比较模式串中的字符与子串中的字符。
这种算法高效的原因,就在于下进行Hash值的比较,因为哈希值是一个数字,数字之间比较是否相等是非常快速的,所以模式串和子串比较的效率就提高了。但是至于高效多少,这就取决于设计的hash算法的设计了。
整个 RK 算法包含三部分:
- 计算子串Hash值
- 比较模式串Hash值与子串Hash值
- Hash值相同时,逐个对比字符
前提是有一个合适的hash算法。
设计Hash算法
hash算法要尽量简单,又要尽可能避免hash冲突。这里介绍两种比较容易理解的hash算法比如按位加,或者按照进制加。
1. 按位相加
这是最简单的方法,我们可以把a当做1,b当做2,c当做3…然后把字符串的所有字符相加,相加结果就是它的hashcode。
bce = 2 + 3 + 5 = 10
但是,这个算法虽然简单,却很可能产生hash冲突,比如bce、bec、cbe的hashcode是一样的。
2. 按进制加
既然字符串只包含26个小写字母,那么我们可以把每一个字符串当成一个26进制数来计算。
bce = 2*(26^2) + 3*26 + 5 = 1435
这样做的好处是大幅减少了hash冲突,缺点是计算量较大,而且有可能出现超出整型范围的情况,需要对计算结果进行取模。
比较模式串Hash值与子串Hash值
这里我们采用第一种Hash算法,下面重点介绍一下流程。
第一步,计算模式串的Hash值。根据前面设计的Hash算法,计算模式串的Hash值。即bce = 2 + 3 + 5 = 10
第二步,在主串中计算第一个和模式串等长的子串的Hash值。即abb = 1 + 2 + 2 = 5: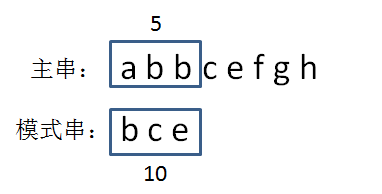
第三步,比较两个hash值。显然,5!=10,说明模式串和第一个子串不匹配,我们继续将模式串与下一个子串比较。
第四步,重复上面的第二步和第三步。生成主串当中第二个等长子串的hash值,bbc = 2 + 2 + 3 = 7。比较模式串的Hash值与这个子串的Hash值,显然,7!=10,说明模式串和第二个子串不匹配,我们继续下一轮比较。重复第四步。
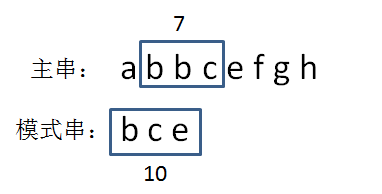
Hash值相同时逐个对比字符
发现主串中第三个等长子串的Hash值与模式串的Hash值相等,接着,我们对两个字符串逐个字符比较,最终判断出两个字符串匹配。
再来回顾一下这个Hash算法
我们发现后一个子串的Hash值的计算,都可以根据前面一个Hash值推导出来,而不需要重新累加计算。比如,
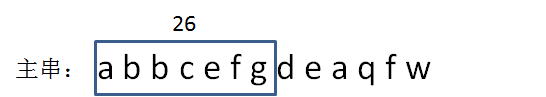
已知子串abbcefg的hash值是26,那么如何计算下一个子串,也就是bbcefgd的hash值呢?由于新子串的前面少了一个a,后面多了一个d,所以:
后一个子串hash值 = 前一个子串hash值 - 1 + 4 = 26-1+4 = 29。
代码实现
def rabin_karp_string_match(text, pattern):
m = len(pattern)
n = len(text)
pattern_hash = hash_code(pattern)
# 计算主串当中第一个和模式串等长的子串hash值
text_hash = hash_code(text[0: m])
# 用模式串的hash值和主串的局部hash值比较。如果匹配,则进行精确比较;如果不匹配,计算主串中相邻子串的hash值。
for i in range(0, n - m + 1):
if text_hash == pattern_hash and text[i: m+i] == pattern:
return i
# 如果不是最后一轮,更新主串从i到i+m的hash值
if i < n - m:
text_hash = next_hash(text, text_hash, i, m)
return -1
def hash_code(string):
"""
这里采用最简单的hashcode计算方式,把a当做0,把b当中1,把c当中2.....然后按位相加
:param string:
:return:
"""
hashcode = 0
for i in range(0, len(string)):
hashcode += ord(string[i]) - ord('a')
return hashcode
def next_hash(string, hash_code, start, end):
"""
根据前一个hash_code计算string中从start~end之间子串的hash_code
:param string:
:param hash_code:
:param start:
:param end:
:return:
"""
hash_code -= ord(string[start]) - ord('a')
hash_code += ord(string[start+end]) - ord('a')
return hash_code
if __name__ == '__main__':
text = "abbcefgh"
pattern = "bce"
print(rabin_karp_string_match(text, pattern))
复杂度分析
我们开头的时候提过,RK 算法的效率要比 BF 算法高,现在,我们就来分析一下,RK 算法的时间复杂度到底是多少呢?
整个 RK 算法包含两部分,计算子串哈希值和模式串哈希值与子串哈希值之间的比较。第一部分,我们前面也分析了,可以通过设计特殊的哈希算法,只需要扫描一遍主串就能计算出所有子串的哈希值了,所以这部分的时间复杂度是 O(n)。
模式串哈希值与每个子串哈希值之间的比较的时间复杂度是 O(1),总共需要比较 n-m+1 个子串的哈希值,所以,这部分的时间复杂度也是 O(n)。所以,RK 算法整体的时间复杂度就是 O(n)。
