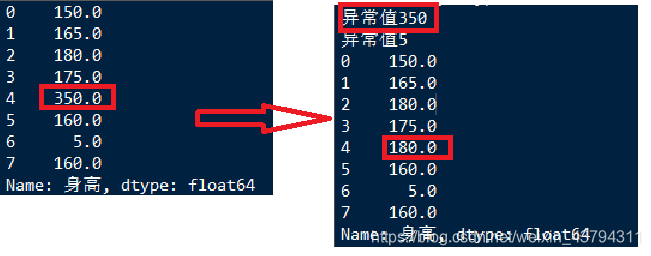
异常处理函数
先对数据计算出一个上限和下限,判断数据是否在这个范围内,可以进行替换等操作
常用计算函数:
分位数:df.身高.quantile(0.5) #一半分位数,也就是中位数
中位数:df.身高.median()
平均数:df.身高.mean()
标准差:df.身高.std()
描述函数:df.身高.describe()
判断是否有异常值any()
import pandas as pd
import numpy as np
df=pd.read_csv('test_innom.csv',encoding='gbk')
print(df.身高)
df_mean=df.身高.mean()
df_std=df.身高.std()
min_da=df_mean-df_std
max_da=df_mean+df_std
print(any((df.身高< min_da )| (df.身高 > max_da) ))
for x in df.身高:
if (x< min_da )| (x > max_da) :
print("异常值%d"%x)
print(df_mean)
print(df_std)
print(df.身高.describe())
print(df.身高.median())
print(df.身高.quantile(0.5))
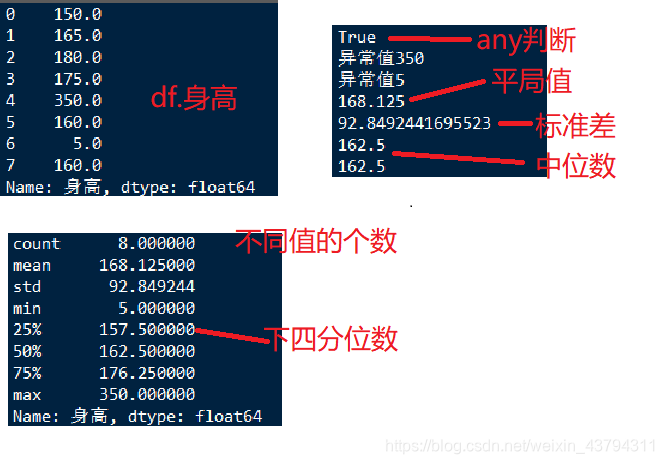
使用最大值替换超范围值
使用loc函数确定需要修改的数据位置,在对数据进行替换赋值,下面的例子将超出最大值的数据使用不超过最大值的数据替代
import pandas as pd
import numpy as np
df=pd.read_csv('test_innom.csv',encoding='gbk')
print(df.身高)
df_mean=df.身高.mean()
df_std=df.身高.std()
min_da=df_mean-df_std
max_da=df_mean+df_std
print(any((df.身高< min_da )| (df.身高 > max_da) ))
for x in df.身高:
if (x< min_da )| (x > max_da) :
print("异常值%d"%x)
rep_val_max=df.身高[df.身高<max_da].max()
df.loc[df.身高>max_da,'身高']=rep_val_max
print(df.身高)