转自: https://blog.csdn.net/s2638358892/article/details/77529008?locationNum=2&fps=1
本文参考了多篇CSDN、知乎以及百度的文章,如果侵犯了您的权益,请及时联系,这是自己写的第一篇博客,有很多不足之处,请原谅。
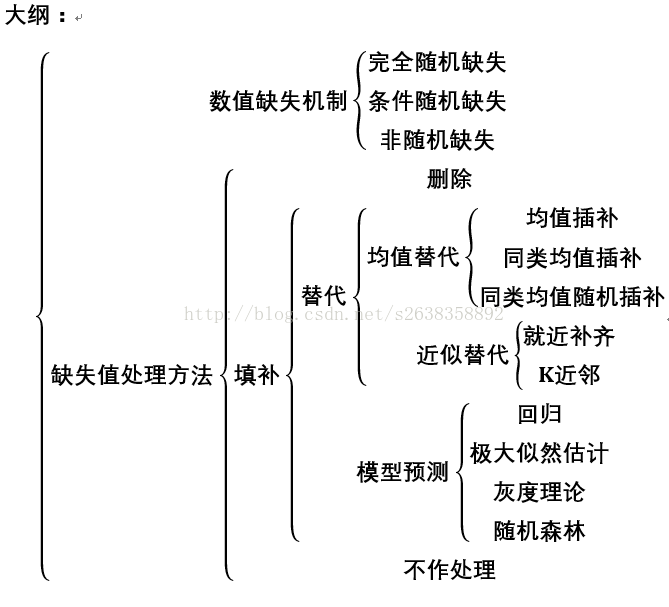
文章将常见的自己能理解的一些缺失值的处理方法以及方法的优缺点做了简单介绍。其中,多重插补、EM算法对缺失值的处理尚未掌握,因此并未放上来。
一、数值缺失机制
1.完全随机缺失(MCAR):缺失数据与该变量的真实值无关,与其他变量的数值也无关。
举例:一位老师抱着批改完的卷子走在路上,不小心摔倒丢失了几张卷子,因此有几位同学没有成绩。这种成绩缺失不是因为成绩这个变量本身高或低而丢失的,而是随机丢失的;也与性别等无关,不会出现男生卷子丢失概率高,女生卷子丢失概率低的问题。
2.条件随机缺失(MAR):缺失数据与其他变量有关。
举例:我们的目标是要统计一个班学生的基本信息,包括名字、性别、身高、体重等。而此时如果某一学生的体重这一变量缺失,这一事件最可能发生在哪些人身上呢?一般来说,是女生。因此体重缺失与已知变量性别相关,这就叫做条件随机缺失。
3.非随机缺失(NNAR):缺失数据依赖于该变量本身。
举例:通常在收集数据时收入一栏很容易缺失,发生这种情况的原因可能是填写人收入过高或过低。因此收入缺失与填写人本身收入有关,这就叫做非随机缺失。
4.完全变量:数据集中不含缺失值的变量称为完全变量。
5.不完全变量:数据集中含有缺失值的变量称为不完全变量。
PS:缺失值不仅包括NULL,也包括用于表示数值缺失的一些特殊数值(比如,在系统中用-999来表示数值不存在)。
二、缺失值处理方法
缺失值的处理,从总体上来说分为删除存在缺失值的个案和缺失值插补两种。但对于主观数据,人将影响数据的真实性,存在缺失值的记录的其他属性的真实值也不能保证,那么依赖于这些属性值的插补也是不可靠的,所以对于主观数据一般不推荐插补的方法。插补主要针对客观数据,它的可靠性有保证。
(一)删除
删除有缺失数据的样本;
删除有过多缺失数据的变量。
删除法是最简单直接、很多时候也是最有效的方法,缺点是会导致信息丢失。
如果缺失数据属于完全随机缺失,简单删除法的后果仅仅是减少了样本量,导致信息量减少。但缺失数据通常都不是MCAR,若采用简单删除法就会使得估计系数出现偏误。
如何判断是否MCAR?
用其他变量预测缺失情况,如果某些系数显著,则不属于MCAR
(二)填补
以最可能的值来插补缺失值比删除全部不完全样本所产生的信息丢失要少。在数据挖掘中,面对的通常是大型的数据库,它的属性有几十个甚至几百个,因为一个属性值的缺失而放弃大量的其他属性值,这种删除是对信息的极大浪费。
1.替代
(1)均值插补
1)均值插补、众数插补
利用均值、中位数、众数、随机数等进行插补
缺点:人为增加了噪声
2)同类均值插补
利用聚类方法预测缺失记录种类,再以该类均值对缺失值进行插补。
3)同类均值随机插补
在利用上述方法进行均值插补时,会存在一个问题:但凡是同类样本,对该变量的预测值都是相同的。为了解决这一问题,在进行数值插补时,我们可以生成正态随机数,其中均值为该类样本均值,方差为该类样本方差。
(2)近似替代
1)就近补齐
对于一个包含空值的对象,就近补齐在完整数据中找到一个与它最相似的对象,然后用这个相似对象的值来进行填充。不同的问题可能会选用不同的标准来对相似进行判定。该方法概念上很简单,且利用了数据间的关系来进行空值估计。这个方法的缺点在于难以定义相似标准,主观因素较多。
2)K近邻
先根据欧式距离或相关分析来确定距离缺失数据最近的K个样本,将这K个值加权平均来估计该样本的缺失数据。
2.模型预测
利用其它变量做模型进行缺失变量的预测
缺陷:如果其它变量与缺失变量无关,则预测的结果毫无意义。如果预测结果相当准确,则又说明这个变量完全没有必要进行预测。一般情况下,会介于两者之间;填补缺失值之后引入了自相关,这会给后续分析造成障碍。
利用模型预测缺失变量的方法无穷无尽,这里仅简单介绍几种。
1)回归
基于完整的数据集,建立回归方程。对于包含空值的对象,将已知属性值代入方程来估计未知属性值,以此估计值来进行填充。当变量不是线性相关或预测变量高度相关时会导致有偏差的估计。
2)极大似然估计
在缺失类型为随机缺失的条件下,假设模型对于完整的样本是正确的,通过观测数据的边际分布可以对缺失数据进行极大似然估计。
重要前提:适用于大样本。有效样本的数据量足以保证ML估计值是渐进无偏的并且服从正态分布。但这种方法可能会陷入局部极值,收敛速度也不是很快,并且计算很复杂。
极大似然估计要求模型的形式必须准确,如果参数形式不正确,将得到错误的结论。
3)灰度理论
4)随机森林
(三)不作处理
在实际应用中,一些模型无法应对具有缺失值的数据,因此要对缺失值进行处理;然而还有一些模型本身就可以应对具有缺失值的数据,此时无需对数据进行处理。
缺点:模型的选择上有所局限
1.把缺失值当做变量的一种特例
比如性别,原本只有男、女两种取值,现在变为男、女、缺失三种。
2.引入虚拟变量
将性别映射为3个变量:是否男、是否女、是否缺失。
优点:保留了原始数据的全部信息;
只有在样本量非常大的时候效果才好,否则会因为过于稀疏,效果很差。
缺点:计算量大大提升。
3.矩阵分解
最后引用一段来自知乎的回答:我认为缺失值填补的精髓就在于不能影响整体的估计,它就只能是占个位置,让程序运行下去,让已有的别的属性的值能发挥作用。填补数与已有的数的分布、特征应符合,不能因为这些数字的变更导致估计值变化。