文章目录
八、pandas 数据清洗&预处理
包括处理缺失数据、重复数据、字符串操作和其它分析数据转换的工具。
1、处理缺失值
对于数值数据,pandas 使用浮点值 NaN(Not a Number)表示缺失数据。
Python内置的None值在对象数组中也可以作为NA。
缺失数据处理函数:

过滤缺失数据
对于一个Series,dropna 返回一个仅含非空数据和索引值的 Series:
from numpy import nan as NA
data = pd.Series([1, NA, 3.5, NA, 7])
data.dropna()
对于 DataFrame,dropna 默认丢弃任何含有缺失值的行:
data = pd.DataFrame([[1., 6.5, 3.], [1., NA, NA], [NA, NA, NA], [NA, 6.5, 3.]])
cleaned = data.dropna()
# 只丢弃全为NA的那些行
data.dropna(how='all')
# 丢弃列
data.dropna(axis=1)
# 只想留下一部分观测数据
data.dropna(thresh = 2)
填充缺失值
df.fillna(0)
# 调用字典,对不同列填充不同的值
df.fillna({1: 0.5, 2: 0})
# 对现有对象修改
df.fillna(0, inplace=True)
fillna 参数:

2、数据转换
移除重复数据
duplicated: 返回一个布尔型Series,表示各行是否是重复行
drop_duplicates:返回一个DataFrame,重复的数组会标为False
data.duplicated()
data.drop_duplicates()
两个方法默认会判断全部列,指定部分列进行重复项判断:
data.drop_duplicates(['k1'])
利用函数或映射进行数据转换
Series的 map 方法可以接受一个函数或含有映射关系的字典型对象,Series的 str.lower 方法,将各个值转换为小写。
替换值
利用 replace 来产生一个新的Series
data.replace(-999, np.nan) # -999 替换成 nan
data.replace([-999, -1000], np.nan) # -999 和 -1000 都替换成 nan
data.replace([-999, -1000], [np.nan, 0]) # -999 替换成 nan -1000 替换成 0
data.replace({-999: np.nan, -1000: 0})
重命名轴索引
跟Series中的值一样,轴标签也可以通过函数或映射进行转换,从而得到一个新的不同标签的对象。
修改行索引或列索引,用 map 函数。
创建数据集的转换版,用 rename 函数。
离散化
把连续数据拆分成 bin,用 cut 函数:
ages = [20, 22, 25, 27, 21, 23, 37, 31, 61, 45, 41, 32]
bins = [18, 25, 35, 60, 100]
cats = pd.cut(ages, bins)
# 划分的 bin,4个区间
cats.categories
# bin 计数,每个区间落入元素的数目
pd.value_counts(cats)
通过传递一个列表或数组到 labels,设置自己的 bin 名称:
group_names = ['Youth', 'YoungAdult', 'MiddleAged', 'Senior']
pd.cut(ages, bins, labels=group_names)
如果向 cut 传入的是 bin 的数量而不是确切的面元边界,则它会根据数据的最小值和最大值计算等长面元:
data = np.random.rand(20)
pd.cut(data, 4, precision=2) # 均匀分成4份,2 位小数
qcut是一个非常类似于cut的函数,它可以根据样本分位数对数据进行面元划分。qcut 由于使用的是样本分位数,因此可以得到大小基本相等的 bin。
data = np.random.randn(1000)
cats = pd.qcut(data, 4)
也可以传递自定义的分位数。
pd.qcut(data, [0, 0.1, 0.5, 0.9, 1.])
检测和过滤异常值
过滤或变换异常值(outlier)在很大程度上就是运用数组运算。
data = pd.DataFrame(np.random.randn(1000, 4))
选出全部含有“超过3或-3的值”的行,将值限制在区间-3到3以内:
data[np.abs(data) > 3] = np.sign(data) * 3
排列和随机采样
利用numpy.random.permutation函数对Series或DataFrame的列随机重排。
df = pd.DataFrame(np.arange(5 * 4).reshape((5, 4)))
sampler = np.random.permutation(5)
sampler # array([3, 1, 4, 2, 0])
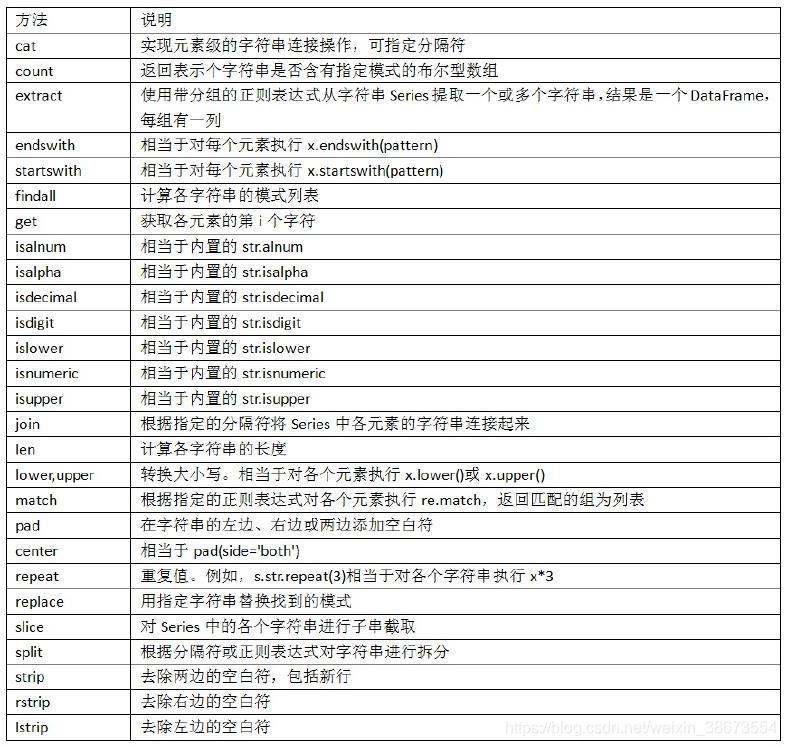
3、字符串操作
字符串对象方法
python 内置的字符串方法:
正则表达式
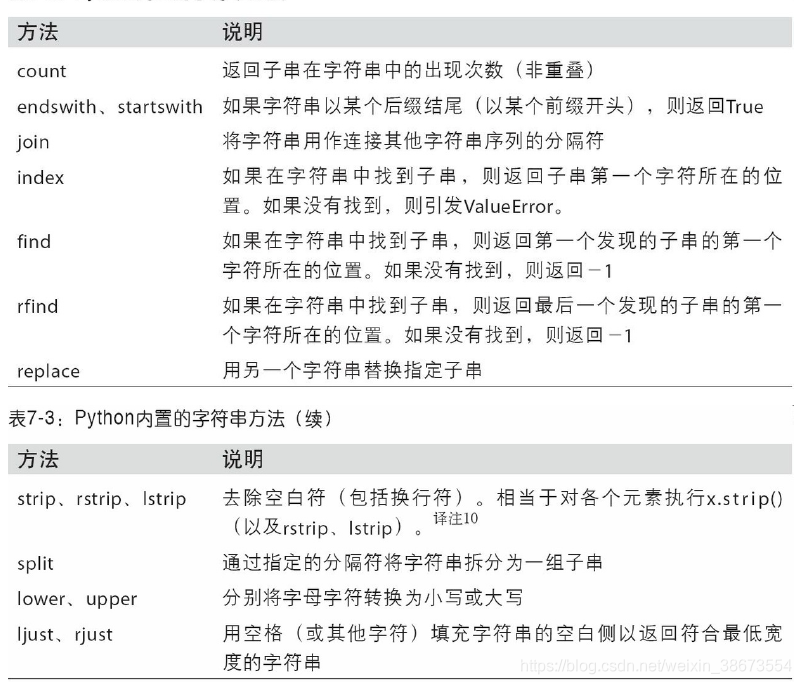
正则表达式,常称作regex,是根据正则表达式语言编写的字符串。
Python内置的 re 模块负责对字符串应用正则表达式。
re 模块的函数可以分为三个大类:模式匹配、替换以及拆分。当然,它们之间是相辅相成的。
正则表达式方法:

pandas的矢量化字符串函数
通过data.map,所有字符串和正则表达式方法都能被应用于(传入lambda表达式或其他函数)各个值,但是如果存在NA(null)就会报错。为了解决这个问题,Series有一些能够跳过NA值的面向数组方法,进行字符串操作。通过Series的str属性即可访问这些方法。
data.str.contains('gmail')