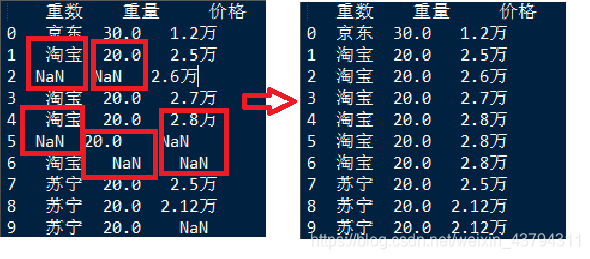
数据缺失处理函数
使用**df.isnull()**确定缺失的数据,缺失时返回true
import pandas as pd
import numpy as np
df=pd.read_csv('my_csv_date.csv',encoding='gb2312',\
na_values=['null','None'],\
dtype={'电话':str,})
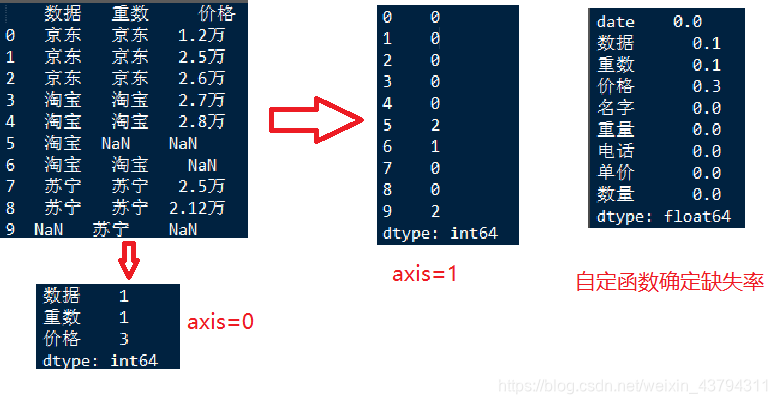
print (df[['数据','重数','价格']])
print(np.sum(df[['数据','重数','价格']].isnull(),axis=1))
print(np.sum(df[['数据','重数','价格']].isnull(),axis=0))
print(df.apply(lambda x:sum(x.isnull())/len(x),axis=0))
删除有缺失值的行df.dropna(how=’’,axis=, )
参数:
axis:0表示删除缺失值的一整行;1表示删除缺失值的一整列
how:’all‘表示(行或列)全部无数据,才删除整(行或列);’any‘:只要有一个缺失就删除整(行或列)
该函数只能返回一个删除后的数据集,但并不改变原来的数据,
inplace:是否取代原来的数据,但数据必须是一类对象,下面的**print (df[[‘数据’,‘重数’,‘价格’]].dropna())不能使用该参数,因为它是切片,而想要改变的是整体数据,但df.dropna()**可以使用该参数
import pandas as pd
import numpy as np
df=pd.read_csv('my_csv_date.csv',encoding='gb2312',\
na_values=['null','None'],\
dtype={'电话':str,})
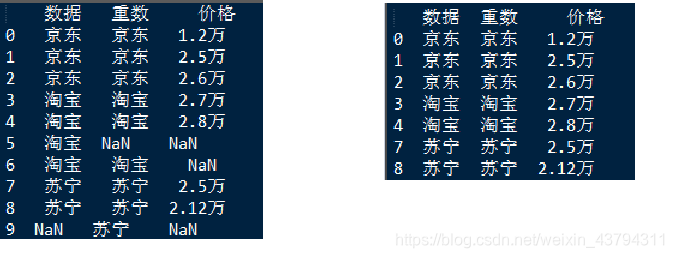
print (df[['数据','重数','价格']])
print (df[['数据','重数','价格']].dropna())
填补缺失数据df[’’].fillna(value={},inplace=’ ',mthod=" ")
参数:
== value==:使用字典赋值,可以对应多列填充,例如,value={}
填充的方式有很多,可以直接写入数值,这里使用了和值的填充,也可使用众数(df[‘重数’].fillna(df[‘重数’].head(5).mode()[0],inplace=True))进行填充修改
使用直接赋值
import pandas as pd
import numpy as np
df=pd.read_csv('my_csv_date.csv',encoding='gb2312', na_values=['null','None'], dtype={'电话':str,})
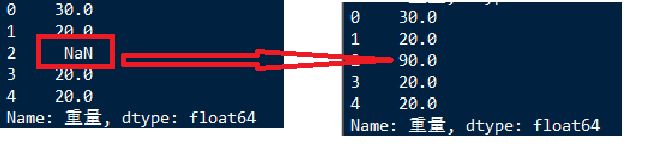
print(df['重量'].head(5))
df['重量'].fillna(df['重量'].head(5)sum(),inplace=True)
print(df['重量'].head(5))
使用字典对value赋值
import pandas as pd
import numpy as np
df=pd.read_csv('my_csv_date.csv',encoding='gb2312',na_values=['null','None'],dtype={'电话':str,})
print(df[['重数','重量','价格']])
df.fillna(value={'重数':df['重数'].mode()[0],'重量':df['重量'].sum(),'价格':df['价格'].mode()[0]},inplace=True)
print(df[['重数','重量','价格']])
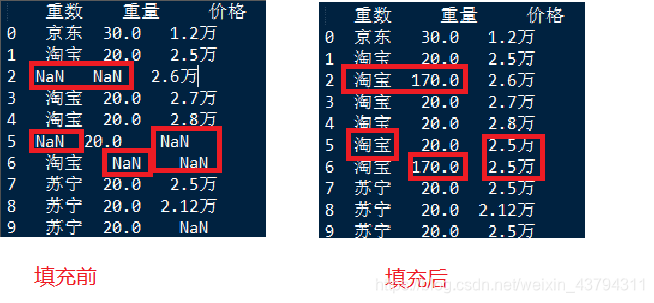
使用fillna()方法中的method参数填充
method的值是ffill时,表示的是前项填充;是bfill时表示后项填充
df=pd.read_csv('my_csv_date.csv',encoding='gb2312', na_values=['null','None'],dtype={'电话':str,})
print(df[['重数','重量','价格']])
df.fillna(method='ffill',inplace=True)
print(df[['重数','重量','价格']])