数据清洗df.duplicated(subset= ,keep=)
df指的是DataFrame类型的数据变量,而这个函数的作用是判断每行数据是否重复,
参数:
subset
设置比较的范围,默认是全部的列按照行比较
keep
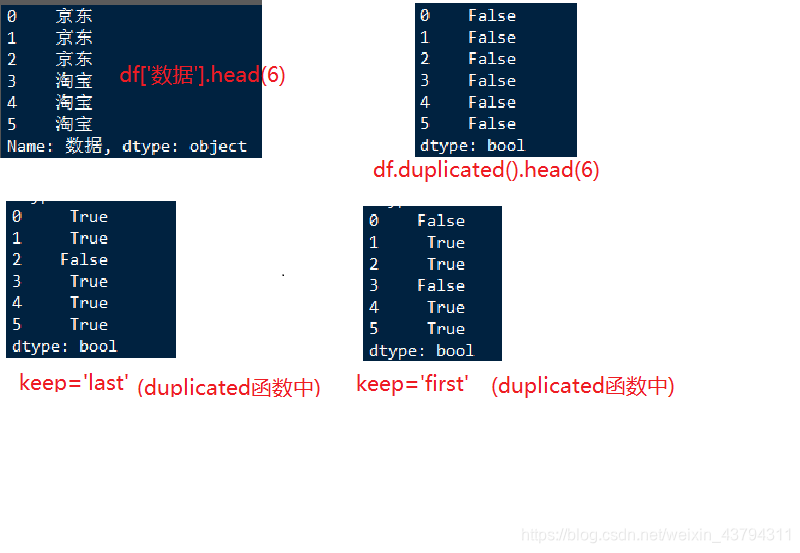
当keep=‘first’:从上到下,第一次出现的数据为false;以后重复的数据都返回true;当keep=‘last’:从上到下,最后一次出现的数据为false;以后前面的数据都返回true;
import pandas as pd
import numpy as np
df=pd.read_csv('my_csv_date.csv',encoding='gb2312',\
na_values=['null','None'],\
dtype={'电话':str,})
print(df)
print(df['数据'].head(6))
print(df.duplicated().head(6))
print(df.duplicated(subset='数据',keep='last') .head(6))
print(df.duplicated(subset='数据',keep='first') .head(6))
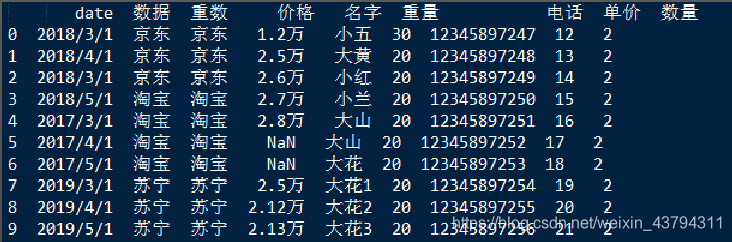
整体数据
函数的duplicated( )显示数据
删除重复df.drop_duplicates(subset = ,keep=,inplace= )
下面例子,通过删除数据列的重复值,将对应的行删除,
参数:
inplace:判断是否需要取代原来的数据值
ssubset判断那些列的行之间是否重复
keep:保留第一个还是最后一个(默认保留第一个)
print(df['数据'].drop_duplicates() .head(6))

