数据挖掘:数据清洗——异常值处理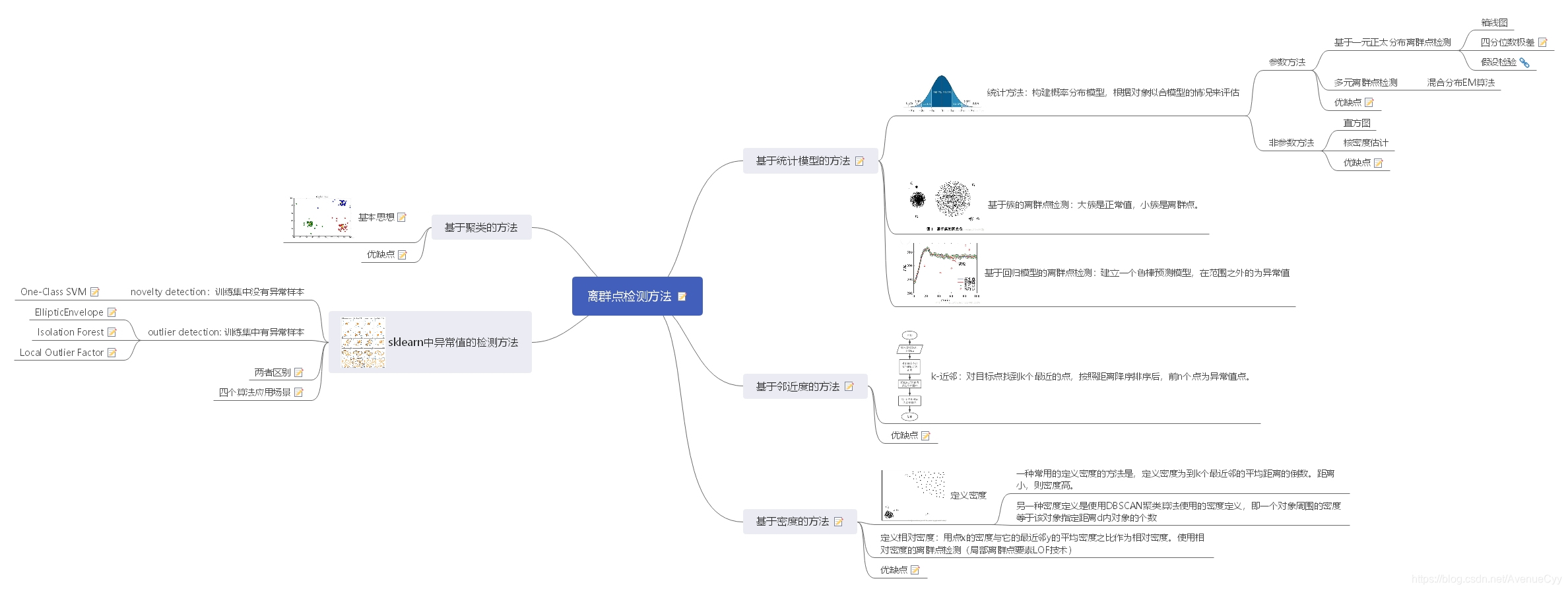
一、离群点是什么?
离群点,是一个数据对象,它显著不同于其他数据对象,与其他数据分布有较为显著的不同。有时也称非离群点为“正常数据”,离群点为“异常数据”。
离群点跟噪声数据不一样,噪声是被观测变量的随机误差或方差。一般而言,噪声在数据分析(包括离群点分析)中不是令人感兴趣的,需要在数据预处理中剔除的,减少对后续模型预估的影响,增加精度。
离群点检测是有意义的,因为怀疑产生它们的分布不同于产生其他数据的分布。因此,在离群点检测时,重要的是搞清楚是哪种外力产生的离群点。
常见的异常成因:
- 数据来源于不同的类(异常对象来自于一个与大多数数据对象源(类)不同的源(类)的思想)
- 自然变异
- 数据测量或收集误差。
通常,在其余数据上做各种假设,并且证明检测到的离群点显著违反了这些假设。如统计学中的假设检验,基于小概率原理,对原假设进行判断。一般检测离群点,是人工进行筛选,剔除不可信的数据,例如对于房屋数据,面积上万,卧室数量过百等情况。而在面对大量的数据时,人工方法耗时耗力,因此,才有如下的方法进行离群点检测。
二、常用的离群点的检测方法
【1】基于统计模型的方法:
- 首先建立一个数据模型,异常是那些同模型不能完美拟合的对象;
- 如果模型是簇的集合,则异常是不显著属于任何簇的对象;
- 在使用回归模型时,异常是相对远离预测值的对象。
【2】基于邻近度的方法:通常可以在对象之间定义邻近性度量,异常对象是那些远离其他对象的对象。
【3】基于密度的方法:仅当一个点的局部密度显著低于它的大部分近邻时才将其分类为离群点。
【4】基于聚类的方法:聚类分析用于发现局部强相关的对象组,而异常检测用来发现不与其他对象强相关的对象。因此,聚类分析非常自然的可以用于离群点检测。
三、 基于分布(概率模型)的假设检验的方法:
基于统计模型的方法:
统计方法
统计方法。统计学方法是基于模型的方法,即为数据创建一个模型,并且根据对象拟合模型的情况来评估它们。大部分用于离群点检测的统计学方法都是构建一个概率分布模型,并考虑对象有多大可能符合该模型。
离群点的概率定义:离群点是一个对象,关于数据的概率分布模型,它具有低概率。这种情况的前提是必须知道数据集服从什么分布,如果估计错误就造成了重尾分布。
参数方法:
1.基于正态分布的一元离群点检测
- 当数据服从正太分布的假设时在正态分布的假定下,u±3σ区域包含99.7%的数据,u±2σ包含95.4%的数据,u±1σ包含68.3%的数据。其区域外的数据视为离群点。
计算得到:通过绘制箱线图可以直观地找到离群点,或者通过计算四分位数极差(IQR)定义为Q3-Q1。比Q1小1.5倍的IQR或者比Q3大1.5倍的IQR的任何对象都视为离群点,因为Q1-1.5IQR和Q3+1.5IQR之间的区域包含了99.3%的对象。
假设检验:根据问题的需要对所研究的总体作某种假设,记作H0;选取合适的统计量,这个统计量的选取要使得在假设H0成立时,其分布为已知;由实测的样本,计算出统计量的值,并根据预先给定的显著性水平进行检验,作出拒绝或接受假设H0的判断。常用的假设检验方法有u—检验法、t检验法、χ2检验法(卡方检验)、F—检验法,秩和检验(非参数)等。假设检验检测离群点原理
2.多元离群点检测
使用混合参数分布在许多情况下,数据是由正态分布产生的假定很有效。然而,当实际数据很复杂时,这种假定过于简单。在这种情况下,假定数据是被混合参数分布产生的。混合参数分布中用期望最大化(EM)算法来估计参数。
异常检测的混合模型方法:对于异常检测,数据用两个分布的混合模型建模,一个分布为普通数据,而另一个为离群点。
聚类和异常检测目标都是估计分布的参数,以最大化数据的总似然(概率)。聚类时,使用EM算法估计每个概率分布的参数。然而,这里提供的异常检测技术使用一种更简单的方法。初始时将所有对象放入普通对象集,而异常对象集为空。然后,用一个迭代过程将对象从普通集转移到异常集,只要该转移能提高数据的总似然(其实等价于把在正常对象的分布下具有低概率的对象分类为离群点)。(假设异常对象属于均匀分布)。异常对象由这样一些对象组成,这些对象在均匀分布下比在正常分布下具有显著较高的概率。
优缺点:
(1)优点:有坚实的统计学理论基础,当存在充分的数据和所用的检验类型的知识时,这些检验可能非常有效;
(2)缺点:大多数方法是针对一元数据的,而对于多元数据,可用的选择少一些,并且对于高维数据,这些检测可能性很差。
非参数方法:
- 不假定先验统计模型,而是试图从输入数据确定模型
通过绘制直方图进行查找,看图说话。但这个方法很难选择一个较好的直方图参数。
优缺点:
(1)优点:可以通过观察数据的分布情况,直观地找到异常点的大致范围。
(2)缺点:一方面,如箱尺寸太小,则由很多正常对象都会落入空的或稀疏箱,因而被误识别为离群点。这将导致很高的假正例率或低精度。相反,如果箱尺寸太大,则离群点对象可能渗入某些频繁的箱中,这将导致很高的假负例率或召回率。为了解决这些问题,使用核密度估计来估计数据的概率密度分布。
基于簇的离群点检测
模型是簇,则异常是不显著属于任何簇的对象。
注意:
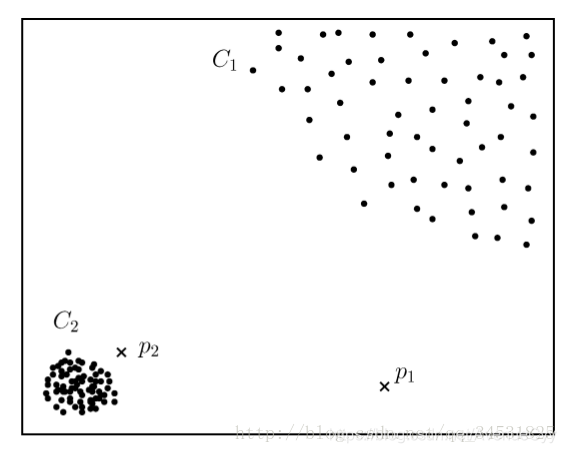
传统的观点都认为孤立点是一个单独的点,然而很多的现实情况是异常事件具有一定的时间和空
间的局部性,这种局部性会产生一个小的簇.这时候离群点(孤立点)实际上是一个小簇(图下图的C1和C3)。

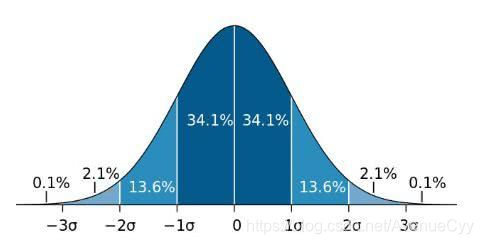
基于回归模型的离群点检测
反应釜中温度的相关过程数据用于算法测试 . 对于反应釜中的温度 ,利用温度传感器 , 每隔 1 min对其进行采样 . 同时 , 上述过程数据中还包含了测量噪声 .
注意:
(1)由于有离群点的存在,在建立模型时,需要建立一个鲁棒预测模型。防止出现过拟合现象,非鲁棒性预测模型尽管该能够检测出全部离群点 , 但同时也会出现了误检的情况 , 随着测量噪声的进一步加大 , 误检或漏检的问题也将更加突出 。
(2)模型鲁棒性需要选择合适的阈值。
三、基于邻近性的方法
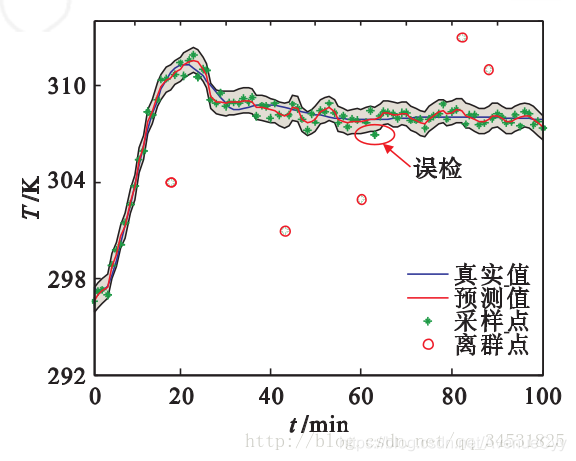
一个对象是异常的,如果它远离大部分点。这种方法比统计学方法更一般、更容易使用,因为确定数据集的有意义的邻近性度量比确定它的统计分布更容易。不依赖统计检验,将基于邻近度的离群点看作是那些没有“足够多“邻居的对象。这里的邻居是用**邻近度(距离)**来定义的。最常用的距离是绝对距离(曼哈顿)和欧氏距离等等。
一个对象的离群点得分由到它的k-最近邻的距离给定。离群点得分对k的取值高度敏感。如果k太小,则少量的邻近离群点可能导致离群点较少;如果K太大,则点数少于k的簇中所有的对象可能都成了离群点,导致离群点过多。为了使该方案对于k的选取更具有鲁棒性,可以使用k个最近邻的平均距离。
优缺点:
(1)优点:简单;
(2)缺点:基于邻近度的方法需要O(m2)时间,大数据集不适用;
(3)该方法对参数的选择也是敏感的;
(4)不能处理具有不同密度区域的数据集,因为它使用全局阈值,不能考虑这种密度的变化。
四、基于密度的方法
从基于密度的观点来说,离群点是在低密度区域中的对象。一个对象的离群点得分是该对象周围密度的逆。基于密度的离群点检测与基于邻近度的离群点检测密切相关,因为密度通常用邻近度定义。
定义密度
一种常用的定义密度的方法是,定义密度为到k个最近邻的平均距离的倒数。如果该距离小,则密度高,反之亦然。
另一种密度定义是使用DBSCAN聚类算法使用的密度定义,即一个对象周围的密度等于该对象指定距离d内对象的个数。需要小心的选择d,如果d太小,则许多正常点可能具有低密度,从而离群点较多。如果d太大,则许多离群点可能具有与正常点类似的密度(和离群点得分)无法区分。使用任何密度定义检测离群点具有与基于邻近度的离群点方案类似的特点和局限性。特殊地,当数据包含不同密度的区域时,它们不能正确的识别离群点。
定义相对密度
为了正确的识别这种数据集中的离群点,我们需要与对象邻域相关的密度概念,也就是定义相对密度。常见的有两种方法:
(1)使用基于SNN密度的聚类算法使用的方法;
(2)用点x的密度与它的最近邻y的平均密度之比作为相对密度。使用相对密度的离群点检测(局部离群点要素LOF技术):
- 首先,对于指定的近邻个数(k),基于对象的最近邻计算对象的密度density(x,k),由此计算每个对象的离群点得分;
- 然后,计算点的邻近平均密度,并使用它们计算点的平均相对密度。这个量指示x是否在比它的近邻更稠密或更稀疏的邻域内,并取作x的离群点得分(这个是建立在上面的离群点得分基础上的)。
优缺点:
(1)优点:给出了对象是离群点的定量度量,并且即使数据具有不同的区域也能够很好的处理;(2)与基于距离的方法一样,这些方法必然具有O(m2)的时间复杂度。对于低维数据使用特定的数据结构可以达到O(mlogm);
(3)缺点:参数选择是困难的。虽然LOF算法通过观察不同的k值,然后取得最大离群点得分来处理该问题,但是,仍然需要选择这些值的上下界。
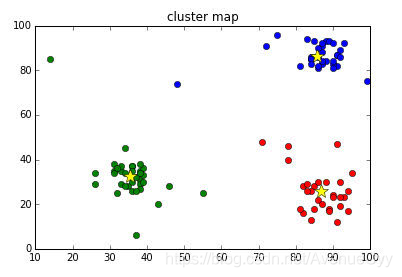
五、基于聚类的方法
一种利用聚类检测离群点的方法是丢弃远离其他簇的小簇。这个方法可以和其他任何聚类技术一起使用,但是需要最小簇大小和小簇与其他簇之间距离的阈值。这种方案对簇个数的选择高度敏感。使用这个方案很难将离群点得分附加到对象上。、
一种更系统的方法,首先聚类所有的点,对某个待测点评估它属于某一簇的程度。(基于原型的聚类可用离中心点的距离来评估,对具有目标函数(例如kmeans法时的簇的误差平方和)的聚类技术,该得分反映删除对象后目标函数的改进),如果删去此点能显著地改善此项目标函数,则可以将该点定位为孤立点。
基于聚类的离群点:一个对象是基于聚类的离群点,如果该对象不强属于任何簇。离群点对初始聚类的影响:如果通过聚类检测离群点,则由于离群点影响聚类,存在一个问题:结构是否有效。为了处理该问题,可以使用如下方法:
- 对象聚类,删除离群点,对象再次聚类(这个不能保证产生最优结果)。
- 还有一种更复杂的方法:取一组不能很好的拟合任何簇的特殊对象,这组对象代表潜在的离群点。随着聚类过程的进展,簇在变化。不再强属于任何簇的对象被添加到潜在的离群点集合;而当前在该集合中的对象被测试,如果它现在强属于一个簇,就可以将它从潜在的离群点集合中移除。聚类过程结束时还留在该集合中的点被分类为离群点(这种方法也不能保证产生最优解,甚至不比前面的简单算法好,在使用相对距离计算离群点得分时,这个问题特别严重)。
对象是否被认为是离群点可能依赖于簇的个数(如k很大时的噪声簇)。该问题也没有简单的答案。一种策略是对于不同的簇个数重复该分析。另一种方法是找出大量小簇,其想法是(1)较小的簇倾向于更加凝聚,(2)如果存在大量小簇时一个对象是离群点,则它多半是一个真正的离群点。不利的一面是一组离群点可能形成小簇而逃避检测。
优缺点:
(1)优点:基于线性和接近线性复杂度(k均值)的聚类技术来发现离群点可能是高度有效的;
(2)簇的定义通常是离群点的补,因此可能同时发现簇和离群点;
(3)缺点:产生的离群点集和它们的得分可能非常依赖所用的簇的个数和数据中离群点的存在性;
(4)聚类算法产生的簇的质量对该算法产生的离群点的质量影响非常大。
六、sklearn中异常值的检测方法
异常检测的分类
novelty detection: 训练集中没有异常样本
outlier detection: 训练集中有异常样本
异常样本:
数量少,比较分散
novelty detection和outlier detection的区别
- 它们的关注对象不同。novelty detection认为,所有跟训练集样本类别不同的点都是异常,不论它跟正常样本有多像,也不论它的分布有多聚集;而outlier detection要求更宽松,只有那些分布稀疏且离正常样本较远的点才是异常的。
- 它们属于不同的机器学习范畴。noverlty detection是半监督学习,因为训练集都是正常样本,所以我们就已经知道了正常样本的数据分布;outlier detection是无监督学习,因为训练集和测试集(真实环境)的分布是一样的,我们无法得知正常样本的分布,只能对数据分布的假设来区分正常和异常。差异自己掌握。
Sklearn异常检测模型一览
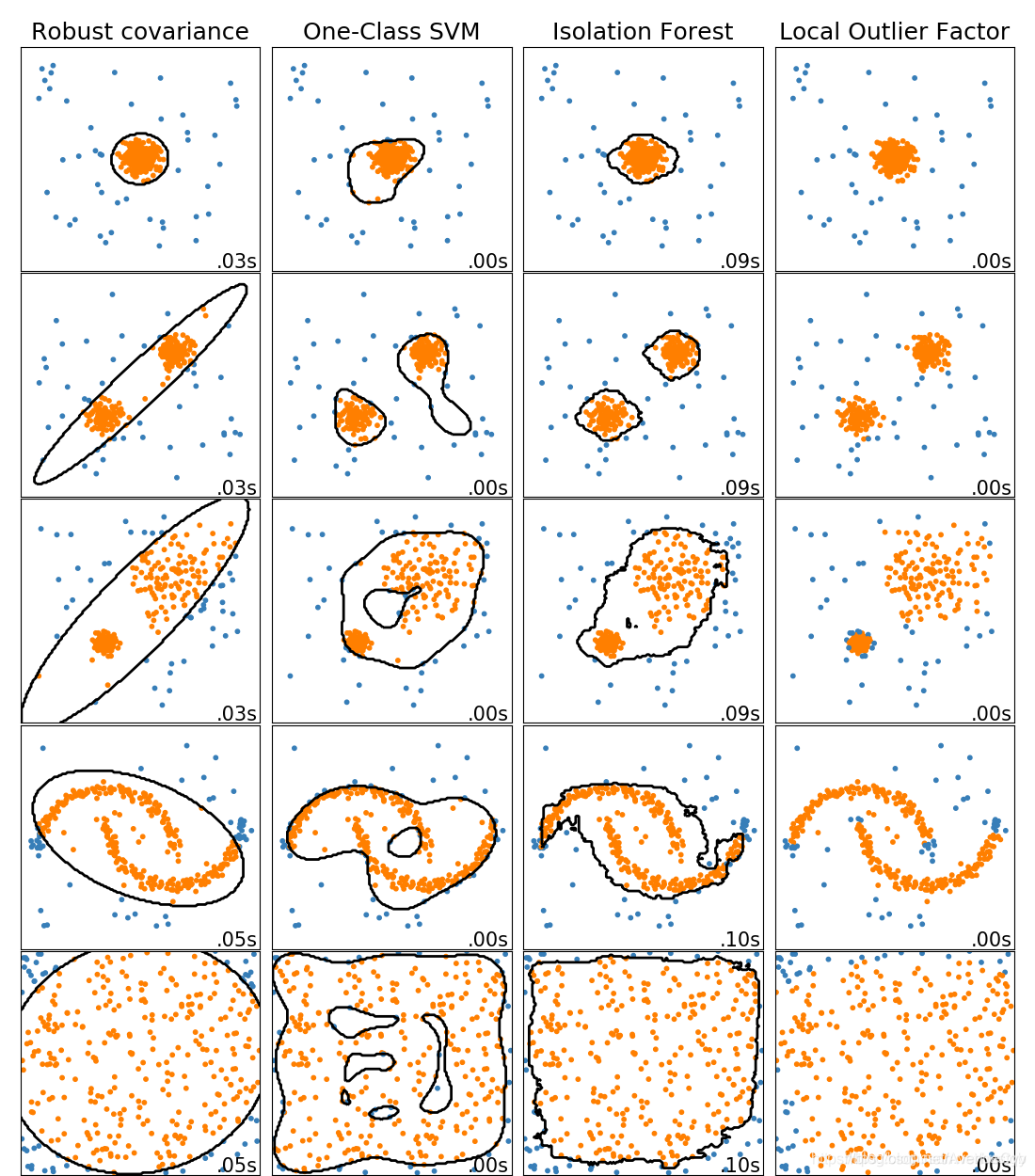
- Robust covariance,即基于方差的鲁棒的异常检测模型,在sklearn中是sklearn.covariance.EllipticEnvelope。该模型假设正常样本都服从高斯分布。显然,对如上图所示的二维数据集,covariance.ELLipticEnvelope采用二维的椭圆拟合正常样本。
- One-Class SVM,即单类别的SVM,在sklearn中是sklearn.svm.OneClassSVM,从上图可以看到该模型的边界都是弯弯曲曲的,说明one-class svm具有很强的拟合能力,但这也导致了它对训练集中对噪声点很敏感。
one-class svm只适用于novelty detection,而outlier detection的训练集中会包含异常样本,因此不适合使用one-class svm来做。 - Isolation Forest,即孤立森林,在sklearn中是sklearn.ensemble.IsolationForest,它在上图5中数据集中的异常检测效果都不错。
- Local Outlier Factor,即局部异常因子检测算法,又称LOF,即相对密度,在sklearn中是sklearn.neighbors.LocalOutlierFactor,效果也不错。
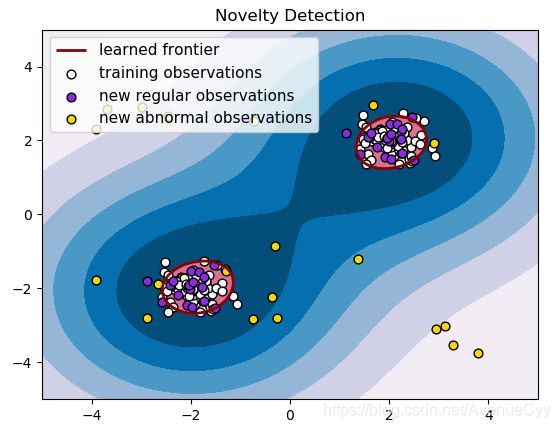
奇异点检测(Novelty Detection)
奇异点检测,就是判断待测样本到底是不是在原来数据的概率分布内。概率学上认为,所有的数据都有它的隐藏的分布模式,这种分布模式可以由概率模型来具象化。
One-Class SVM
SVM通过把原始空间通过核方法(kernel method)映射到一个特征空间中,进而使不同类别的样本在特征空间中很容易分开。One-class SVM也是一样的,先用一个核方法,比如高斯核(RBF kernel)将原始空间映射到特征空间,然后在特征空间中画一个“圈”,圈内是自己人,圈外是敌人。这个“圈”就是支撑向量(support vectors)形成的边界。
当训练数据只有一类时,可以选择One-class SVM算法。该算法进行异常点检测原理是将样本数据训练出一个最小的超球面(大于3维特征),其中在二维中是一个曲线,将数据全部包起来,即将异常点排除。其核心在于选择从低维的空间向高维特征空间映射的核函数及相应的误差惩罚因子。跟SVM调参一样。
离群点检测(Outlier Detection)
不同与奇异点检测是,现在我们没有一个干净的训练集(训练集中也有噪声样本)。下面介绍的三种离群点检测算法其实也都可以用于奇异点检测。
Fitting an elliptic envelope(拟合一个椭圆矩形)
做离群点检测的最简单的思路是,正常数据服从一个已知的分布。服从一个已知的分布,说白了就是正常数据的分布可以通过一个不是很复杂的数据公式刻画出来,如均匀分布、高斯分布、泊松分布等等。这个模型假设所有的数据都服从高斯分布,然后拿着开始试不同的均值和方差(高维情况下就是均值矩阵和协方差矩阵),那组均值和方差形成的高斯分布适合描述当前的数据集。这就像套圈,拿着不同形状的椭圆套,套套套~
SKlearn提供了一个covariance.EllipticEnvelope类,它可以根据数据做一个鲁棒的协方差估计,然后学习到一个包围中心样本点并忽视离群点的椭圆。
鲁棒的意思是足够稳定,绝不过拟合。
下图是Sklearn官方给出的例子,可以看到robust做的很棒,平时用的时候默认开启robust设置就好了。

Isolation Forest
孤立森林是一个高效的离群点监测算法。该算法与随机森林同源,具体检测算法如下:
- 随机选择一个数据集的子集作为单棵树的根结点
- 随机选择一个特征
- 在该特征上随机选择一个值做split
- 重复2、3直到树的深度到达
- 重复1、2、3、4到树个数上限
- 经常距离根结点较近的点是异常点
那些距离根结点比较近的,都是因为离群,导致很容易被划分成叶子节点。
LOF
LOF算法比较复杂,它通过观察数据分布的密度来检测异常。
LOF中的基本概念:
- k-neighbors,即K近邻,就是距离目标样本点最近的k个样本。
- rechability distance,即可达距离,就是目标样本点的势力范围,是一个能把K近邻都包含进去的圆。
- rechability density,即可达密度,就是目标样本点势力范围内的“人口密度”。
如果我们认为,可达密度小的目标样本点就是异常点,这样未尝不可。但是,LOF算法更进一步。
LOF算法从两个维度判断异常点:
- 目标样本点的可达密度小
- 目标样本的K近邻的可达密度都较大
LOF可以用来判断经纬度的异常。
总结
如果训练集很干净:使用one-class svm
训练集不干净,如果能保证训练集能基本覆盖正常样本:LOF
训练集不干净,如果能保证训练集服从正太分布:EllipticEnvelope
训练集不干净,不能保证训练集基本覆盖正常样本:isolation forest
七、 参考文献
http://blog.sina.com.cn/s/blog_6002b97001014njh.html
https://blog.csdn.net/qq_34531825/article/details/72828182
https://wenku.baidu.com/view/208864738e9951e79a892705.html
https://blog.csdn.net/hustqb/article/details/75216241
https://blog.csdn.net/hustqb/article/details/75216241
