
发表于CVPR2021!!!
论文链接:https://arxiv.org/pdf/2106.08523.pdf
代码链接:无
1. 问题
近年来,基于直推图的方法在少样本分类中取得了很大的成功。然而,现有的大多数方法都忽略了探索class-level的知识,这些知识很容易被人类从少数几个样本中学习到
2. 贡献
1)首次提出了一种基于图的端到端小样本学习体系结构,该体系结构可以明确地学习丰富的类知识,以指导查询样本的图推理
2)建立了多头样本关系来探究两两样本之间的细粒度比较,这有助于基于两两关系学习更丰富的类知识
3)利用类名的语义嵌入构造不同类的多模态知识表示,为查询样本的推理提供更有区别的知识。
4)在四个基准上进行了广泛的实验(即miniImageNet, tieredImageNet, CIFAR-FS和CUB-200-2011),结果表明,该方法具有较好的分类性能。
3. 方法
考虑如何显式地学习更丰富的类知识,以指导基于图的查询样本推理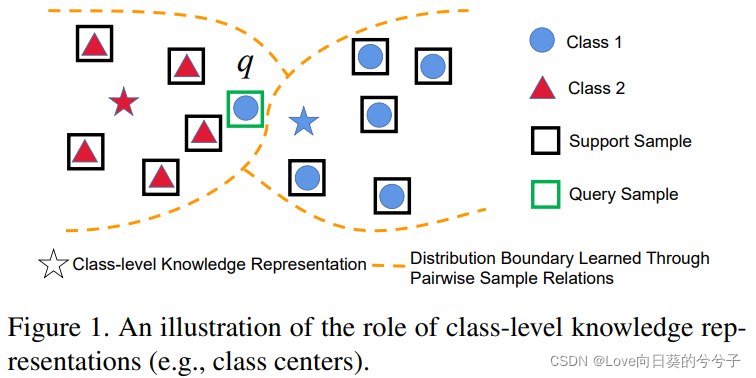
如图1所示,如果我们仅仅利用样本表示和关系来执行少镜头分类任务,我们可能会将查询样本q错分类为类2。然而,如果我们明确地学习类级知识表示来指导推理过程,我们可以正确地对q进行分类,因为q更接近类1的表示。
3.1 问题描述

3.2 显式类知识传播网络
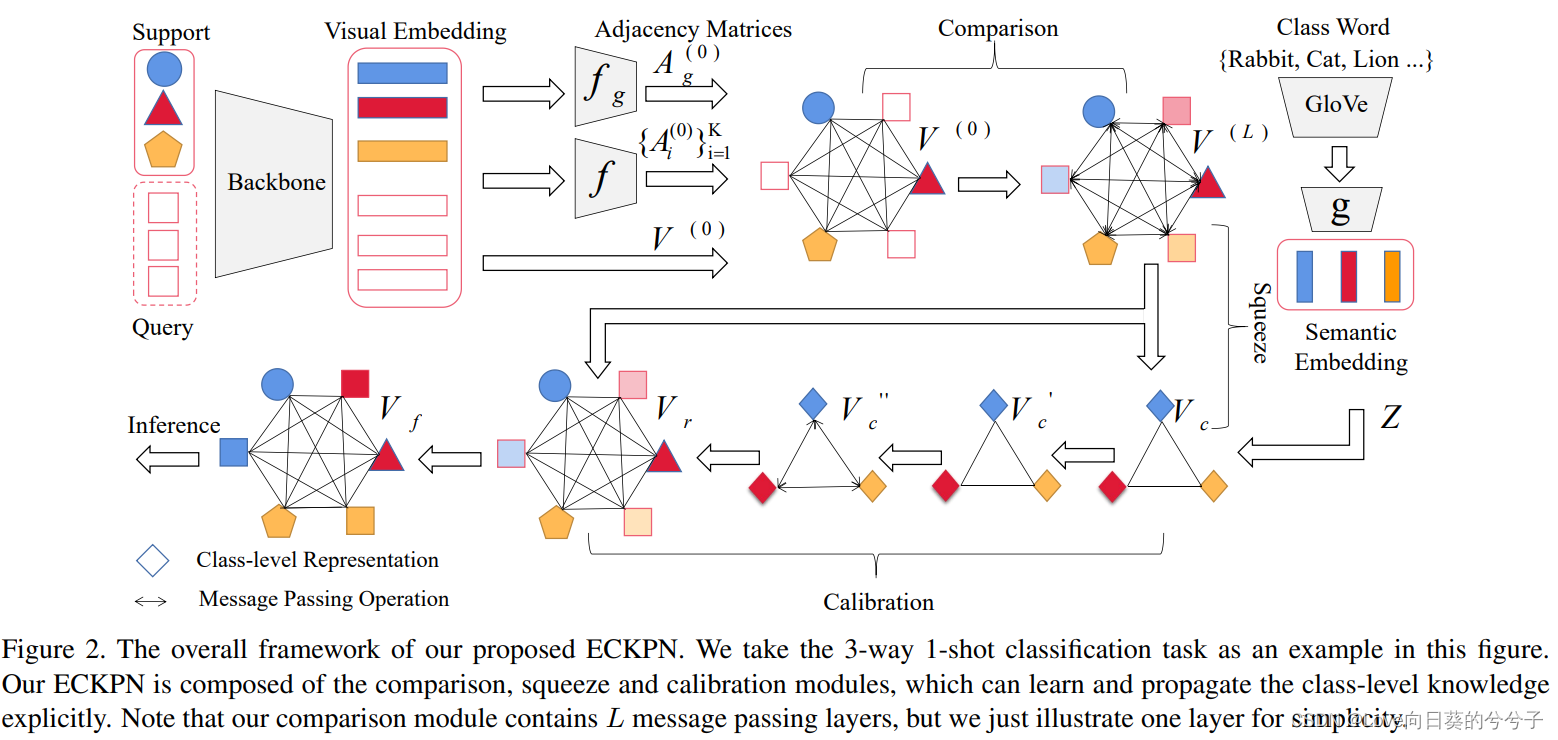
框架概述:
1)首先,利用支持和查询样本来构建实例级图。
2)然后,利用比较模块来基于实例级图中的成对节点关系更新样本表示。在这个模块中,作者构造了多头关系来帮助建模细粒度的样本关系,以学习丰富的样本表示。
3)接下来,将实例级图压缩到类级图,以显式地探索类级视觉知识。
4)在校准模块中,根据类之间的关系进行类级消息传递操作,更新类级知识表示。由于类的语义词嵌入能够提供丰富的先验知识,我们将其与类级视觉知识相结合,在校准模块消息传递之前构造多模态类知识表示。
5)最后,将类级知识表示与实例级样本表示相结合,指导查询样本的推理。
-
比较模块:多头关系进行实例级消息传递
对于图像 i i i,采用一个深度CNN模型作为骨架来提取其视觉特征。(我们遵循现有文献,将图像的视觉特征与其对应的one-hot编码相结合,作为初始节点特征 v i ( 0 ) ∈ R d v^{(0)}_i \in R^d vi(0)∈Rd。由于查询样本的标签在推理生成中不可用,我们将其one-hot编码的元素设置为1/N,其中N是类的数量。)
在每个episode中,我们将支持集和查询集样本作为节点来构建图 G = ( V ( 0 ) , A ( 0 ) ) G = (V^{(0)},A^{(0)}) G=(V(0),A(0)),其中 V ( 0 ) V^{(0)} V(0)为初始节点特征矩阵, A ( 0 ) A^{(0)} A(0)为表示样本关系的初始邻接矩阵集合。已有工作表示,视觉特征总是包含一些可以进行分组的概念,即同一组的特征维度代表相似的知识。然而,现有的基于图的小样本学习方法通常直接利用全局视觉特征计算样本的相似度来构造邻接矩阵,不能很好地表征细粒度关系。在本文中,我们将视觉特征分成 K K K个块(即 V ( l ) = [ V 1 ( l ) , V 2 ( l ) , … , V K ( l ) ] ∈ R r × d ) V^{(l)} = [V^{(l)}_1, V^{(l)}_2,…, V^{(l)}_K] \in R^{r \times d}) V(l)=[V1(l),V2(l),…,VK(l)]∈Rr×d),计算每个块的相似度,以探索样本的多头关系(即 K K K个邻接矩阵 V 1 ( l ) , V 2 ( l ) , … , V K ( l ) ∈ R r × r V^{(l)}_1, V^{(l)}_2,…, V^{(l)}_K \in R^{r \times r} V1(l),V2(l),…,VK(l)∈Rr×r),其中 r r r为每个episode的样本个数, [ ∗ , ∗ ] [*,*] [∗,∗]为拼接操作, l l l为在图的第 l l l层生成矩阵。注意,每个块 V i ( l ) V^{(l)}_i Vi(l)的维数是 d / K d/K d/K。也计算基于非分块视觉特征的全局关系矩阵 A g ( l ) ∈ R r × r A^{(l)}_g \in R^{r \times r} Ag(l)∈Rr×r。
我们联合利用全局( A g ( l ) A^{(l)}_g Ag(l))和多头( { A i ( l ) } i = 1 K \{A^{(l)}_i \}^K_{i=1} { Ai(l)}i=1K)关系(即 A ( l ) = { A g ( l ) , A 1 ( l ) , … , A K ( l ) } A^{(l)} = \{A^{(l)}_g, A^{(l)}_1,…, A^{(l)}_K\} A(l)={ Ag(l),A1(l),…,AK(l)})在实例级图中传播信息,以更新样本表示。这样,我们可以更充分地探索样本之间的关系,学习更丰富的样本表示。在第 l l l层,我们利用更新的样本表示 V ( l ) V^{(l)} V(l)构造新的邻接矩阵 A g ( l ) A^{(l)}_g Ag(l)和 A i ( l ) A^{(l)}_i Ai(l),如下所示:

受TRPN在few-shot分类任务中成功的启发,我们利用以下矩阵来mask邻接矩阵:
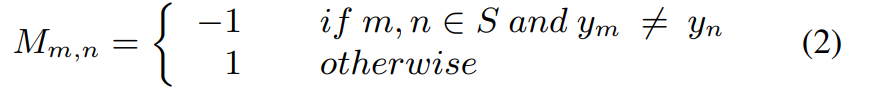
其中 m m m和 n n n为 S ∪ Q S \cup Q S∪Q中的样本, y m y_m ym为样本 m m m的标签。这就保证了对于不同类别的两个样本,特征相似度越高,在消息传递过程中的共同性就越低。对于同一类别的两个样本,结果正好相反。

-
压缩模块: 类级别的视觉知识学习
为了获得类级知识表示,我们压缩实例级图生成类级图,其中节点表示类的可视化知识。例如,我们将实例级图中的节点压缩成5个簇/节点,从而获得5-way分类任务中类的可视化知识。具体来说,我们首先利用ground truth监督分配矩阵的生成,然后根据分配矩阵对样本进行压缩,得到类级知识表示 V c ∈ R r 1 × d V_c \in R^{r_1 \times d} Vc∈Rr1×d,其中 r 1 r_1 r1表示每一episode的类数。为简便起见,本文将 V ( L ) V^{(L)} V(L)和 A g ( L ) A^{(L)}_g Ag(L)代入标准图神经网络中计算分配矩阵 P ∈ R r × r 1 P \in R^{r \times r_1} P∈Rr×r1:
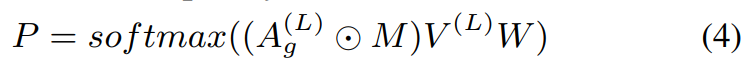
其中, W ∈ R d × r 1 W \in R^{d \times r_1} W∈Rd×r1表示可训练的权重矩阵,softmax操作以行方式应用。分配矩阵 P P P中的每个元素 P u v P_{uv} Puv表示原始图中的节点 u u u被分配到类级图中的节点 v v v的概率。在生成分配矩阵 P P P后,我们利用下面的方程生成初始类级知识表示:

其中 T T T表示转置运算。在类级图中,每个节点特征可以看作是实例级图中具有相同标签的节点特征的加权和。通过这种方法,我们得到了类级的视觉知识表示,这将有助于对校准模块中不同类之间的关系进行建模。 -
校准模块:具有多模态知识的类级消息传递
由于类词嵌入可以提供视觉内容中可能不包含的信息,我们将其与生成的类级视觉知识相结合,构建多模态知识表示。具体来说,我们首先利用GloVe(在带有自我监督约束的大型文本语料库上进行预训练)来获得类标签的 d 1 d_1 d1维语义嵌入。本文使用的是GloVe的Common Crawl版本,它是在840B token上训练的。在获得第 i i i类的词嵌入 e i ∈ R d 1 e_i \in R^{d_1} ei∈Rd1后,利用映射网络 g : R d 1 → R d g: R^{d_1} \rightarrow R^d g:Rd1→Rd将其映射到与视觉知识表示具有相同维数的语义空间,即 z i = g ( e i ) ∈ R d z_i = g(e_i) \in R^d zi=g(ei)∈Rd。最后,我们得到如下的多模态类表示:

其中 Z ∈ R r 1 × d Z \in R^ {r_1 \times d} Z∈Rr1×d是语义词嵌入矩阵。这样可以获得更丰富的类级知识表示。
类级图的邻接矩阵( A c A_c Ac)表示类表示的关系,其值表示类对的连通强度。在本文中,我们利用以下公式计算邻接矩阵 A c A_c Ac和新的类级知识表示 v c ′ ′ v''_c vc′′:
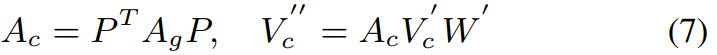
其中 w ′ ∈ R 2 d × 2 d w' \in R^{2d \times 2d} w′∈R2d×2d是一个可训练的权重矩阵。为了使每个样本都包含(7)中所学习到的类知识,我们利用分配矩阵将类知识映射回实例级图,如下所示

其中 V r ∈ R r × 2 d V_r \in R^{r \times 2d} Vr∈Rr×2d表示经过优化的特征。最后,通过串联将 V r V_r Vr与 V ( L ) V^{(L)} V(L)结合,生成用于查询推理的样本表示 V f V_f Vf。
3.3 推理
为了推断查询样本的类标号,我们利用 V f V_f Vf计算相应的邻接矩阵 A f A_f Af如下:
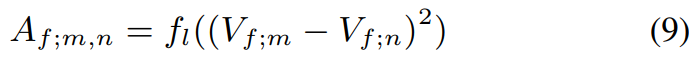
其中 V f ; m V_{f;m} Vf;m, V f ; n V_{f;n} Vf;n分别表示第 m m m个样本和第 n n n个样本。 f l : R 3 d → R 1 f_l: R^{3d} \rightarrow R^1 fl:R3d→R1是一个映射函数。对于每个查询示例,我们利用支持示例的类标签来预测其标签:
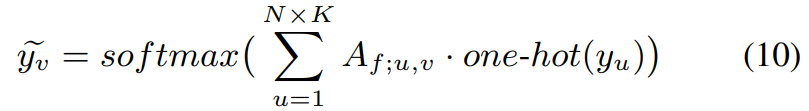
其中one-hot表示one-hot编码器
3.4 损失函数
提出的ECKPN的总体框架可以通过以下损失函数以端到端形式进行优化:
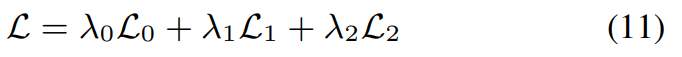
其中,λ0、λ1、λ2为超参数,实验设置为1.0、0.5、1.0。 L 0 \mathcal{L}_0 L0、 L 1 \mathcal{L}_1 L1和 L 2 \mathcal{L}_2 L2分别是邻接损失、分配损失和分类损失。具体地,
-
Adjacency Loss
对于每个图网络层 l = { 1 , … , L } l = \{1,…, L \} l={ 1,…,L}在比较模块中,我们有多个邻接矩阵 A g ( L ) A^{(L)}_g Ag(L)和 { A i ( L ) } i = 1 K \{A^{(L)}_i \}^K_{i=1} { Ai(L)}i=1K用于支持样本和查询样本之间的消息传递。此外,在上述中,我们有用于查询推理的邻接矩阵 A f A_f Af。为了确保这些邻接矩阵能够捕获正确的样本关系,我们使用以下损失函数
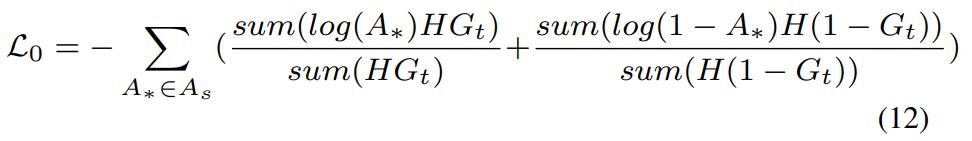

其中 m m m和 n n n表示图中的节点。 -
Assignment Loss
为了保证压缩模块中计算的分配矩阵 P P P能够正确地对具有相同标签的样本进行聚类,我们利用以下交叉熵损失函数:
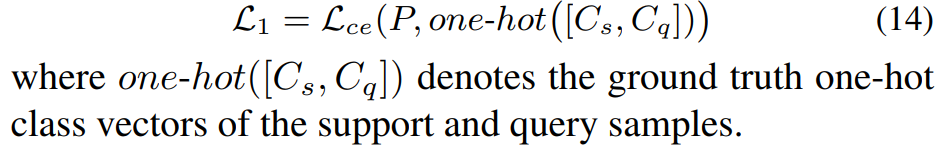
-
Classification Loss
为了约束提出的ECKPN能够预测正确的查询标签,我们使用以下损失函数
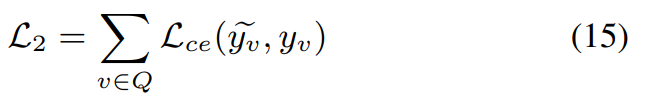
其中 L c e \mathcal{L}_{ce} Lce表示交叉熵损失函数。
4. 部分实验结果
-
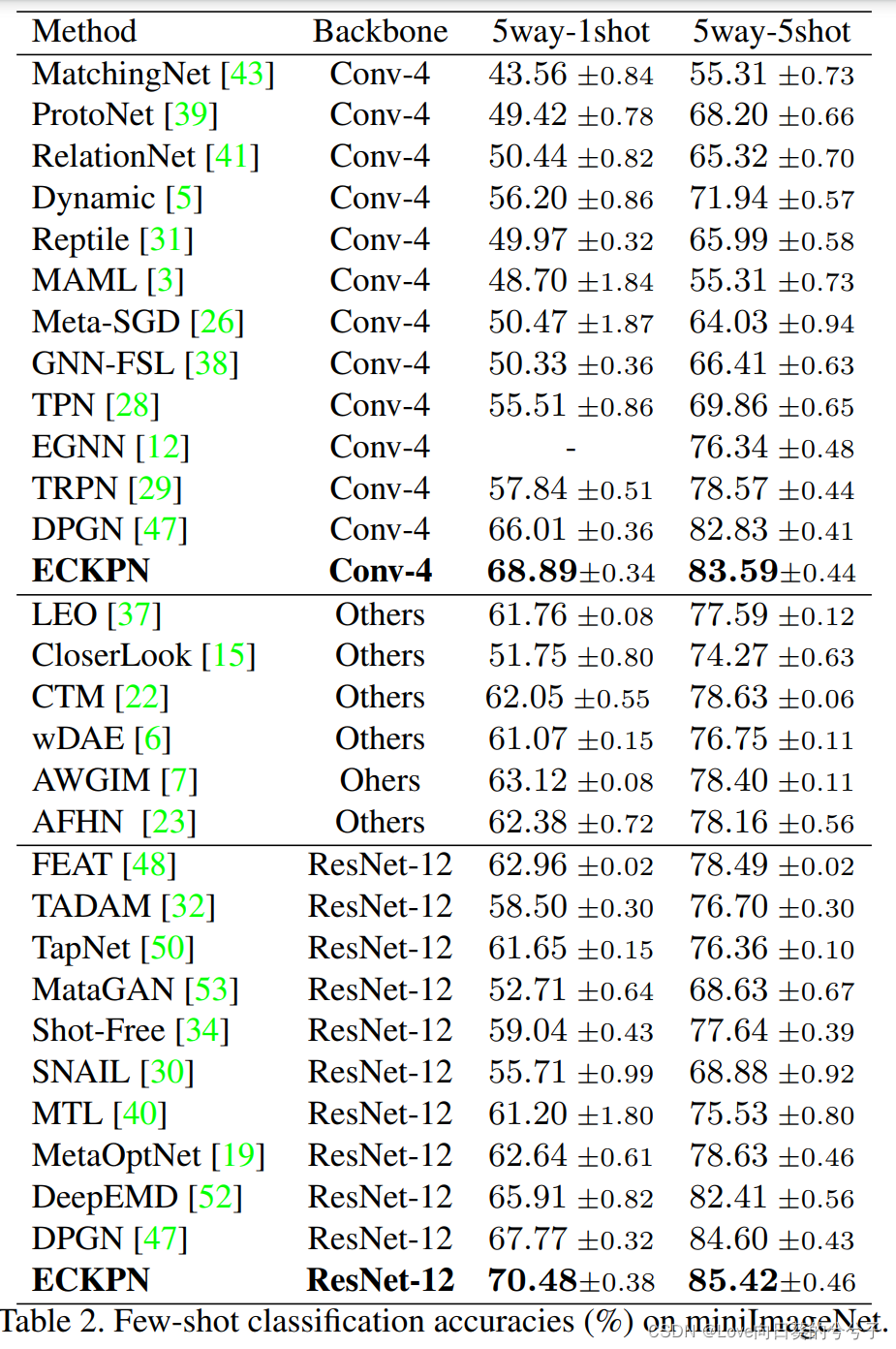
SOTA方法性能对比
1)miniimagenet库
2)tieredimagenet库
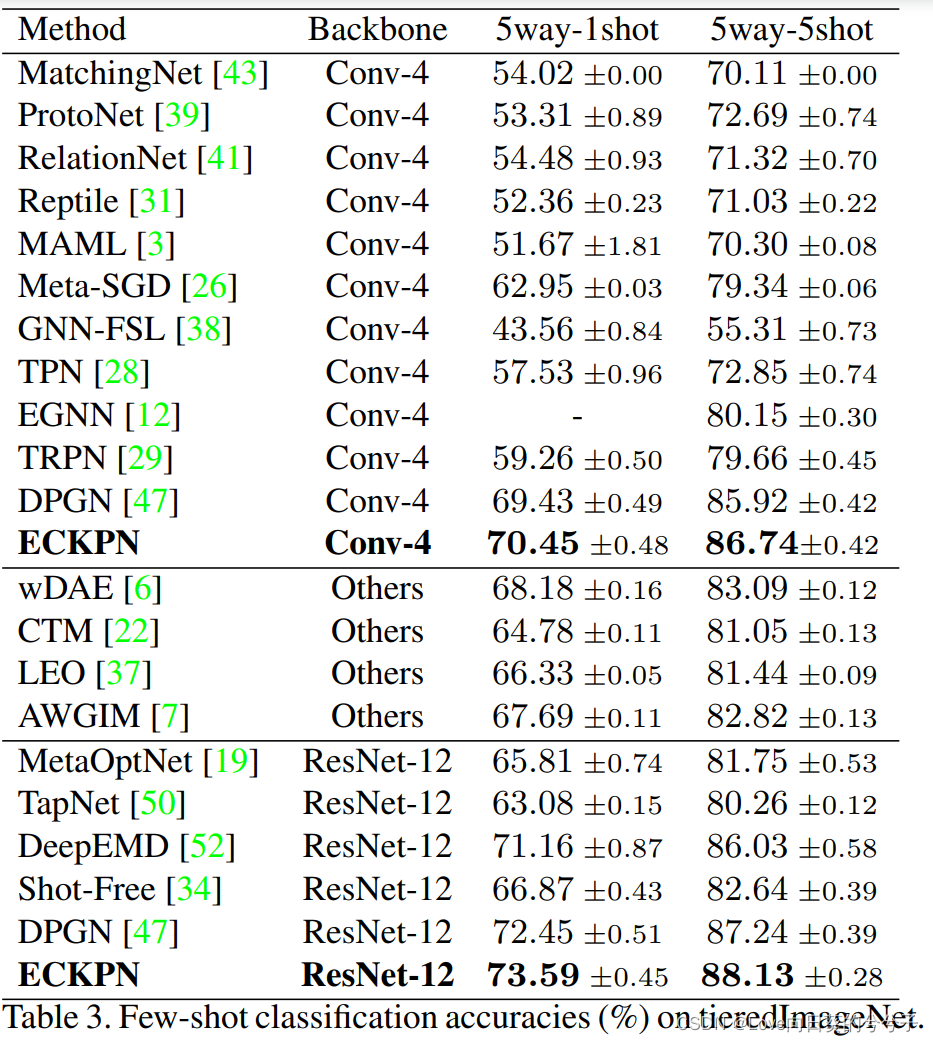
3)cub和cifar-fs库
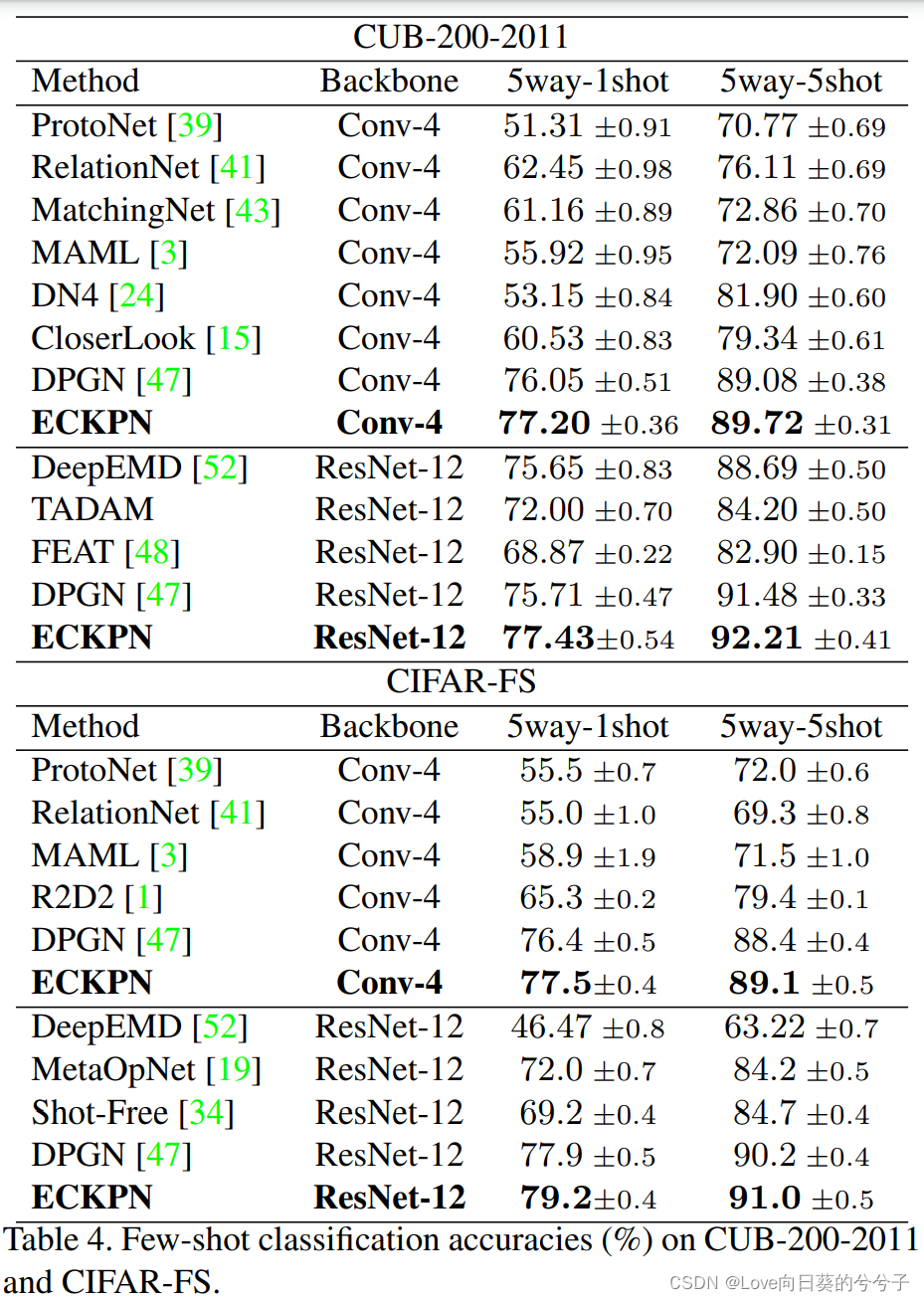
-
半监督小样本分类性能
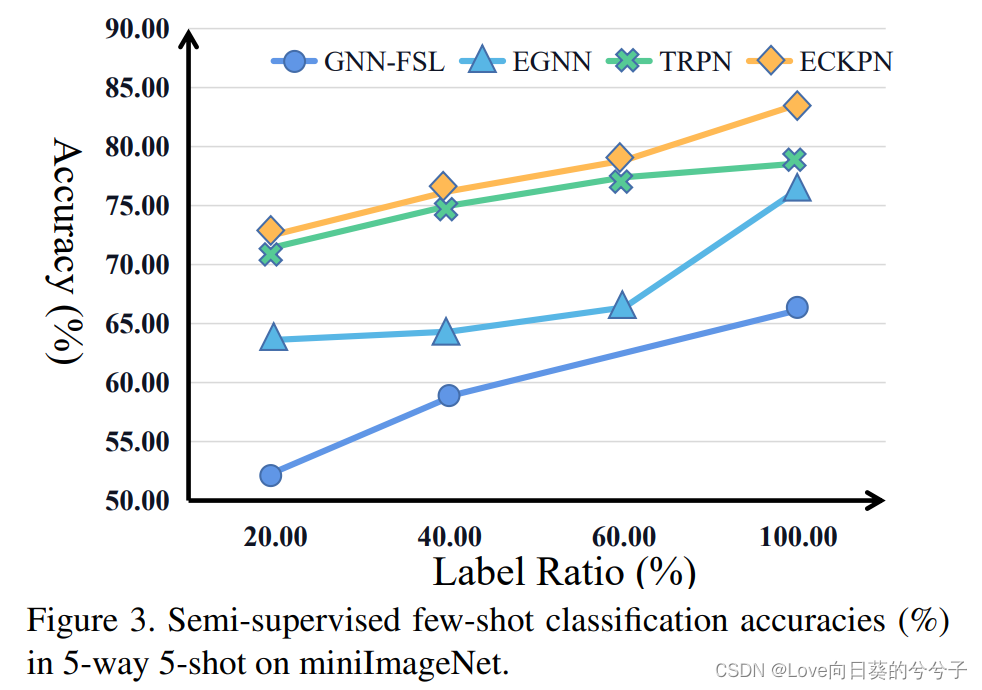
-
参数分析
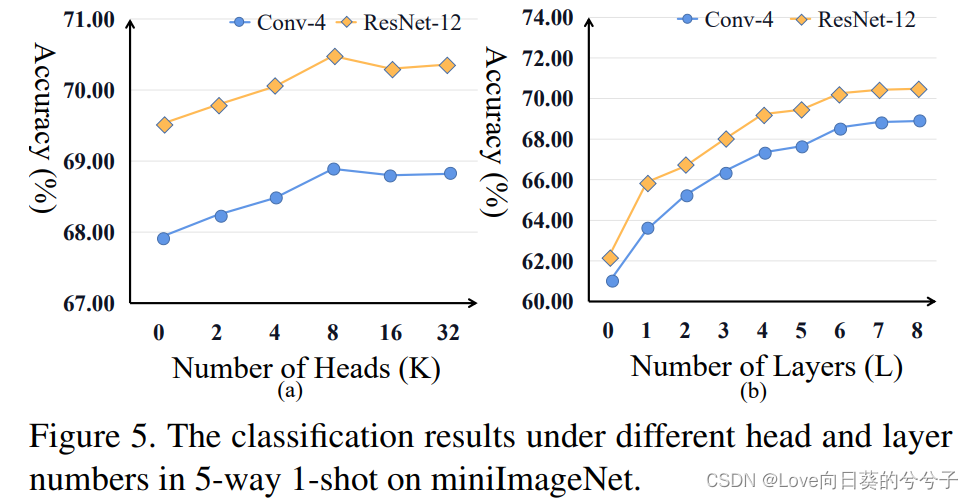
-
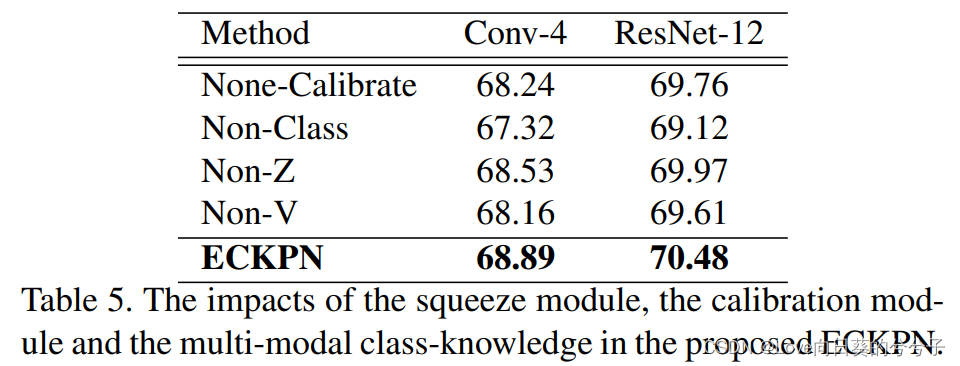
消融实验
5. 结论
1)基于图的元学习方法有两种设置:直推式和归纳式。直推式方法将支持集和查询集的样本之间的关系描述出来进行联合预测,其性能优于归纳方法,归纳方法只能根据支持集之间的关系来学习网络,并对每个查询样本进行单独分类
2)本文属于直推式方法
3)本文首次提出了一种基于图的端到端少镜头学习体系结构