名字叫孪生神经网络,但是实际上只有一个网络
训练孪生网络的方法(两个)
方法一:每次取两个样本,比较他们的相似度
训练这个大的神经网络需要一个大型数据集,每一类要有标注

-
正负样本的设置,同一类放两张图片,标签为1(相似度满分);不同类抽取两张图片,标签为0

-
神经网络的搭建
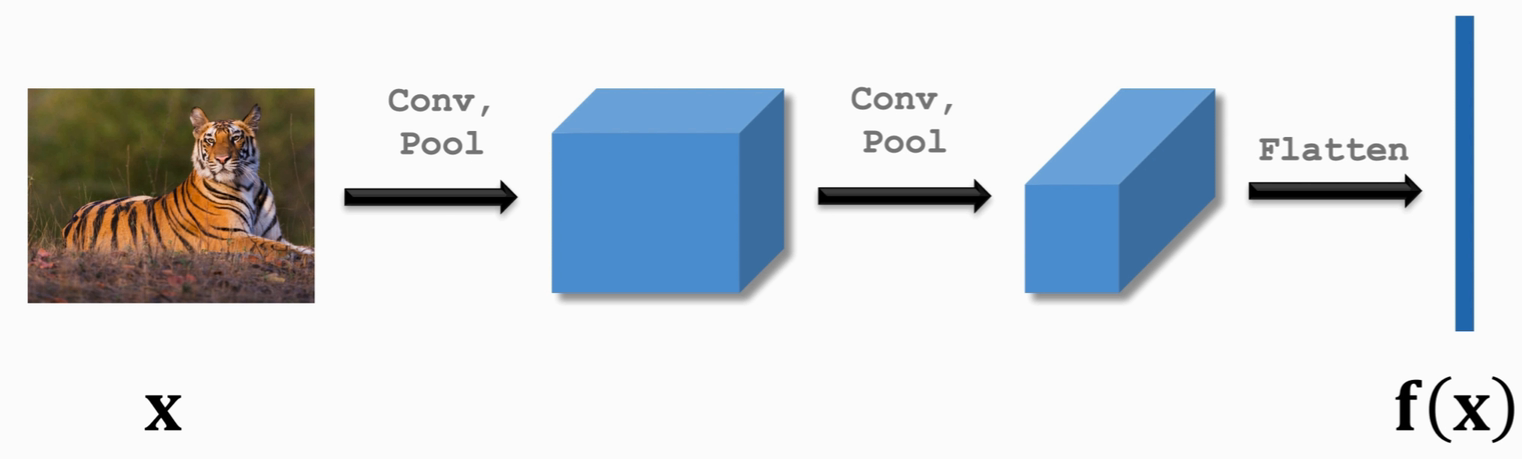
图片经过卷积后展开为长向量
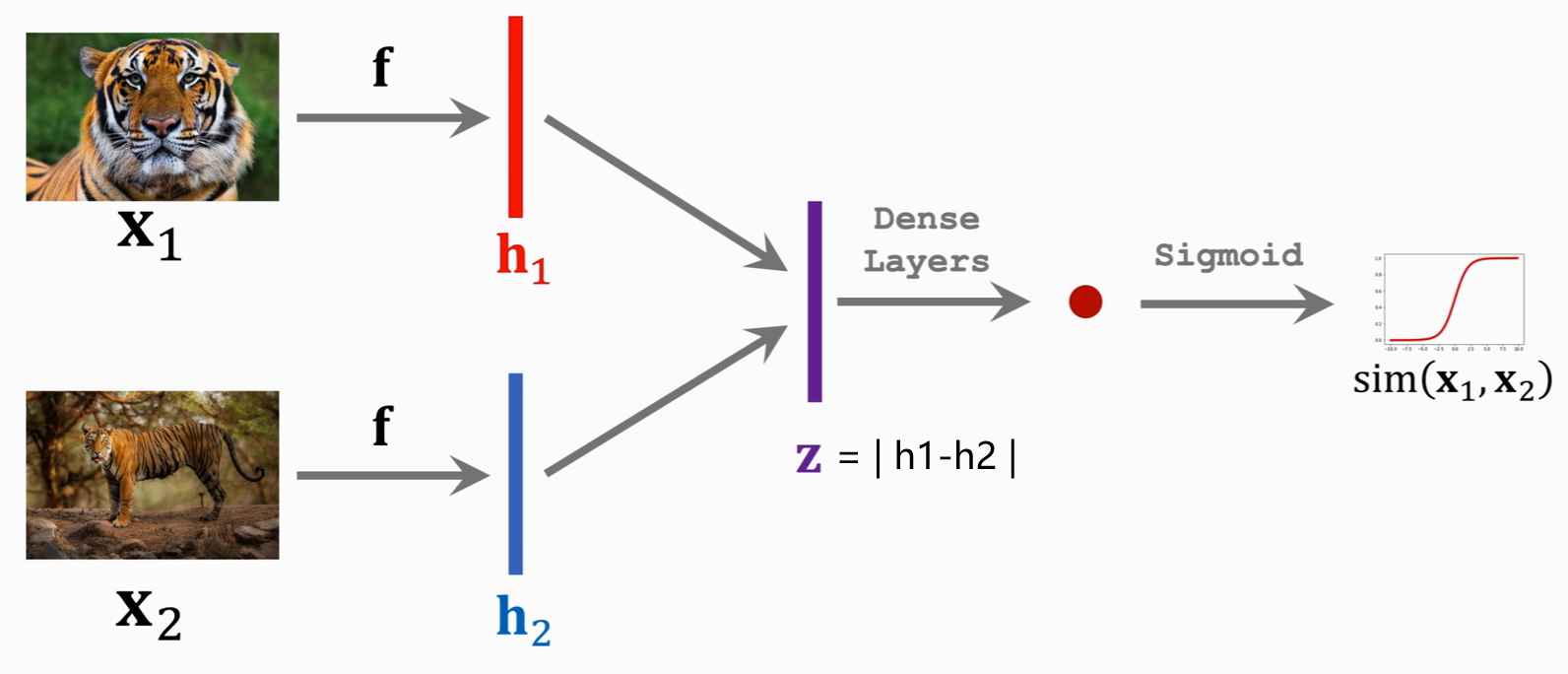
这边h1和h2是同一个神经网络得到的结果,相减后求绝对值得到Z,再进全连接层到1个输出,最后sigmoid函数激活得到概率
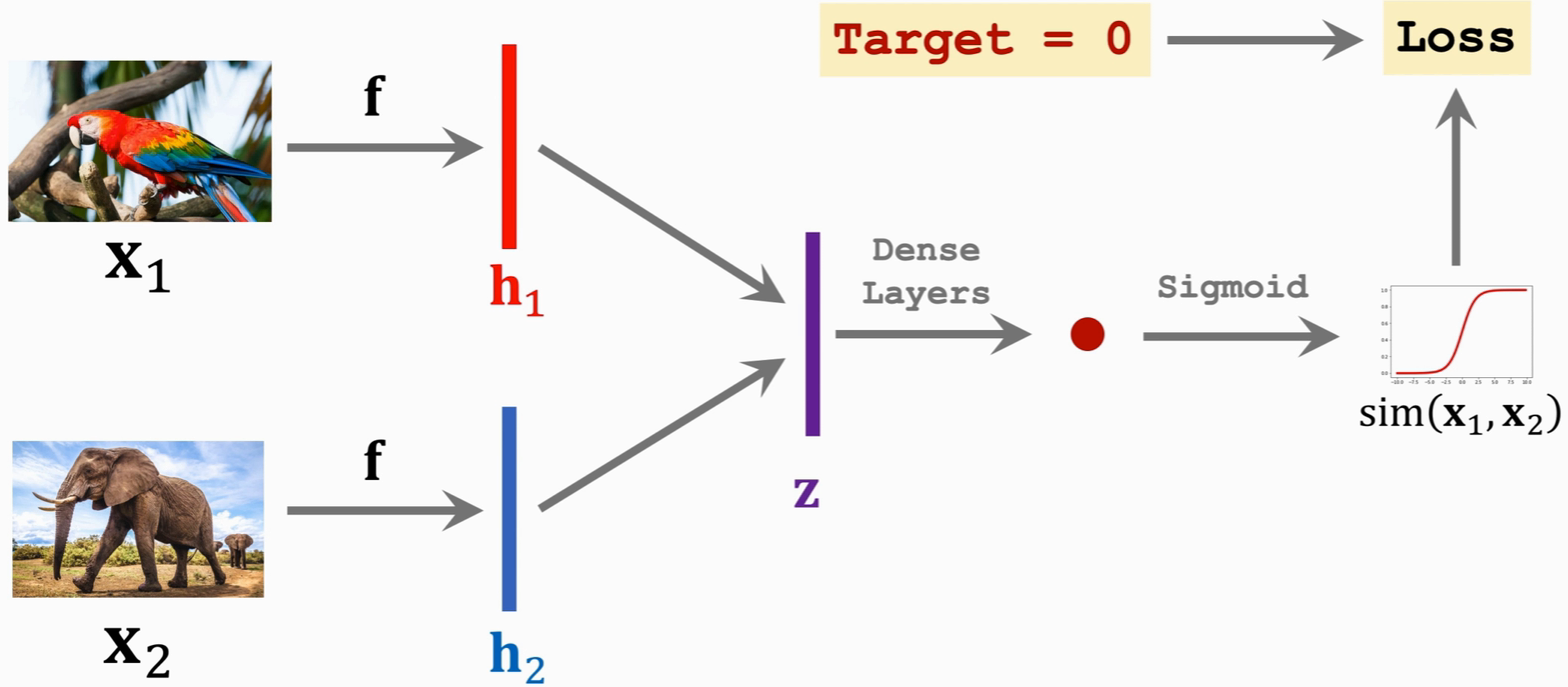
损失函数:损失函数可以是 cross-entropy负样本同理:(正样本标签为1,负样本标签为0)
-
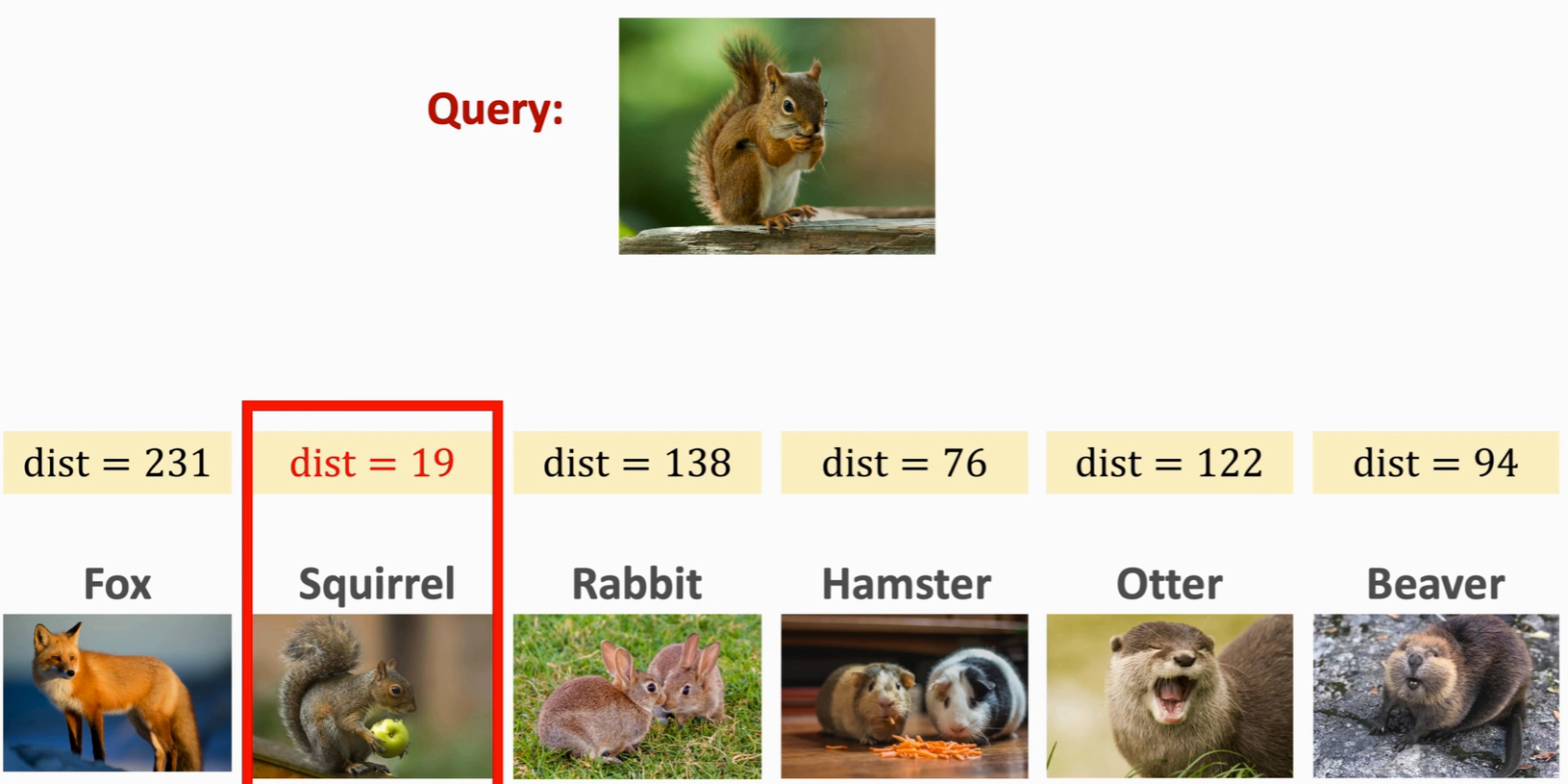
One-shot 预测
首先需要提供
Support Set,注意Support Set里出现的图片不在训练集里,然后提供Query,Query应该是Support Set中的某一类,然后Query 与 Support Set 逐一进行对比计算相似度,选取相似度最大的作为预测结果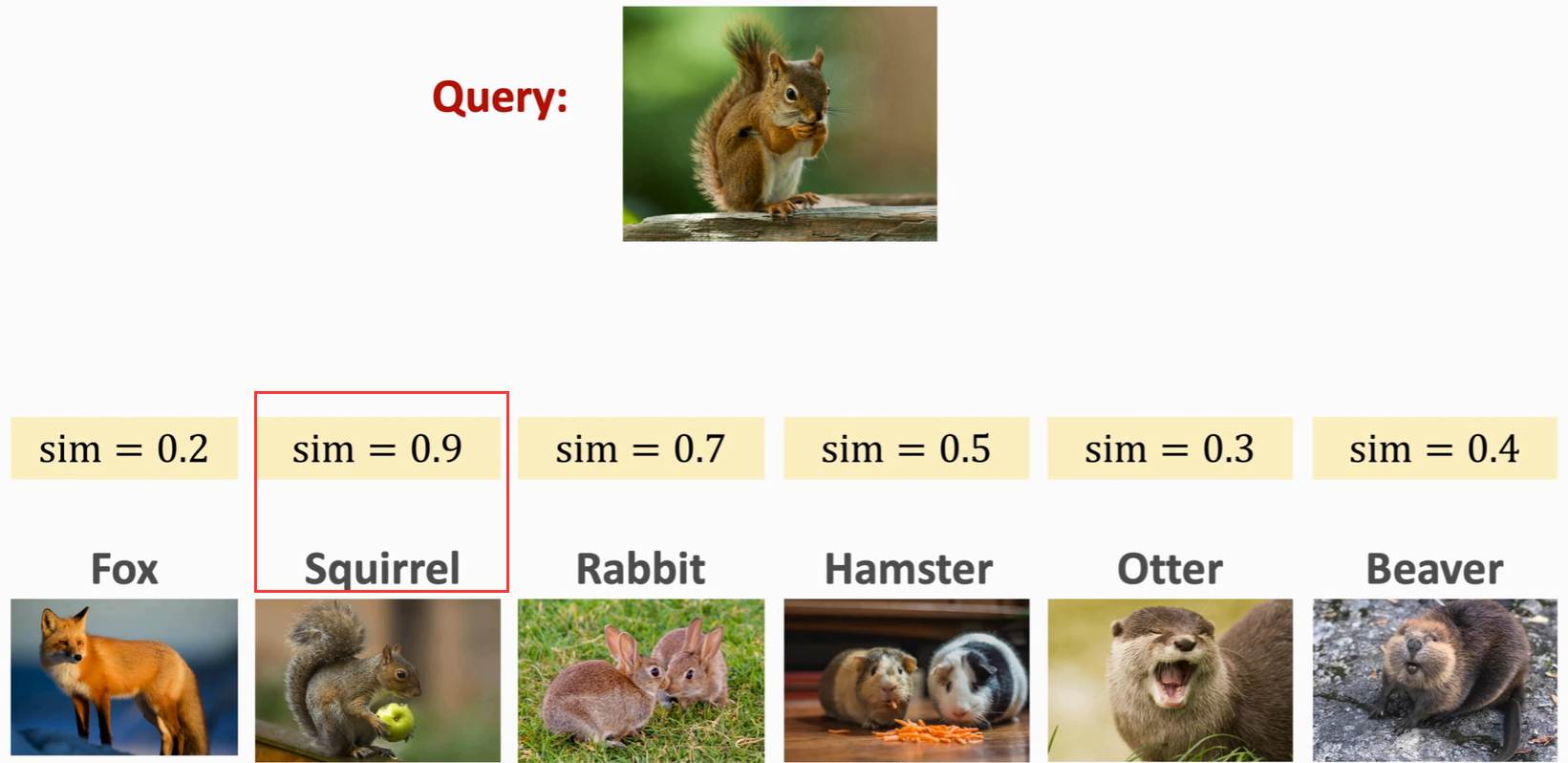
方法二:Triplet Loss
-
数据准备
每次从训练集中选出三张图片进行训练;其中两张属于同一类,另外一张不同类,同一类的两张图片中,一张称之为 anchor ,另外一张为 positive ,不同类的图片称为 negative。计算
向量差的二范数的平方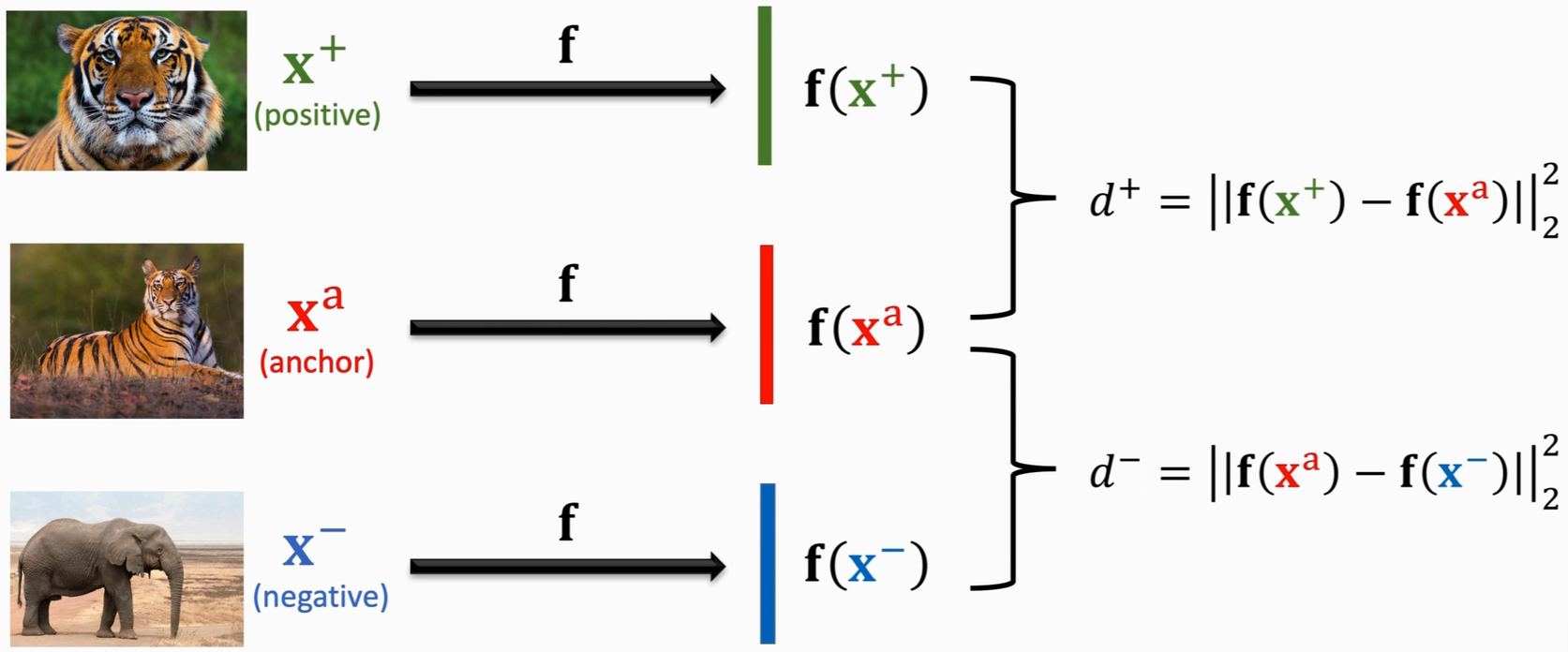
这里d+ 越小越好,表示同一类别,d- 越大越好,表示不同类别
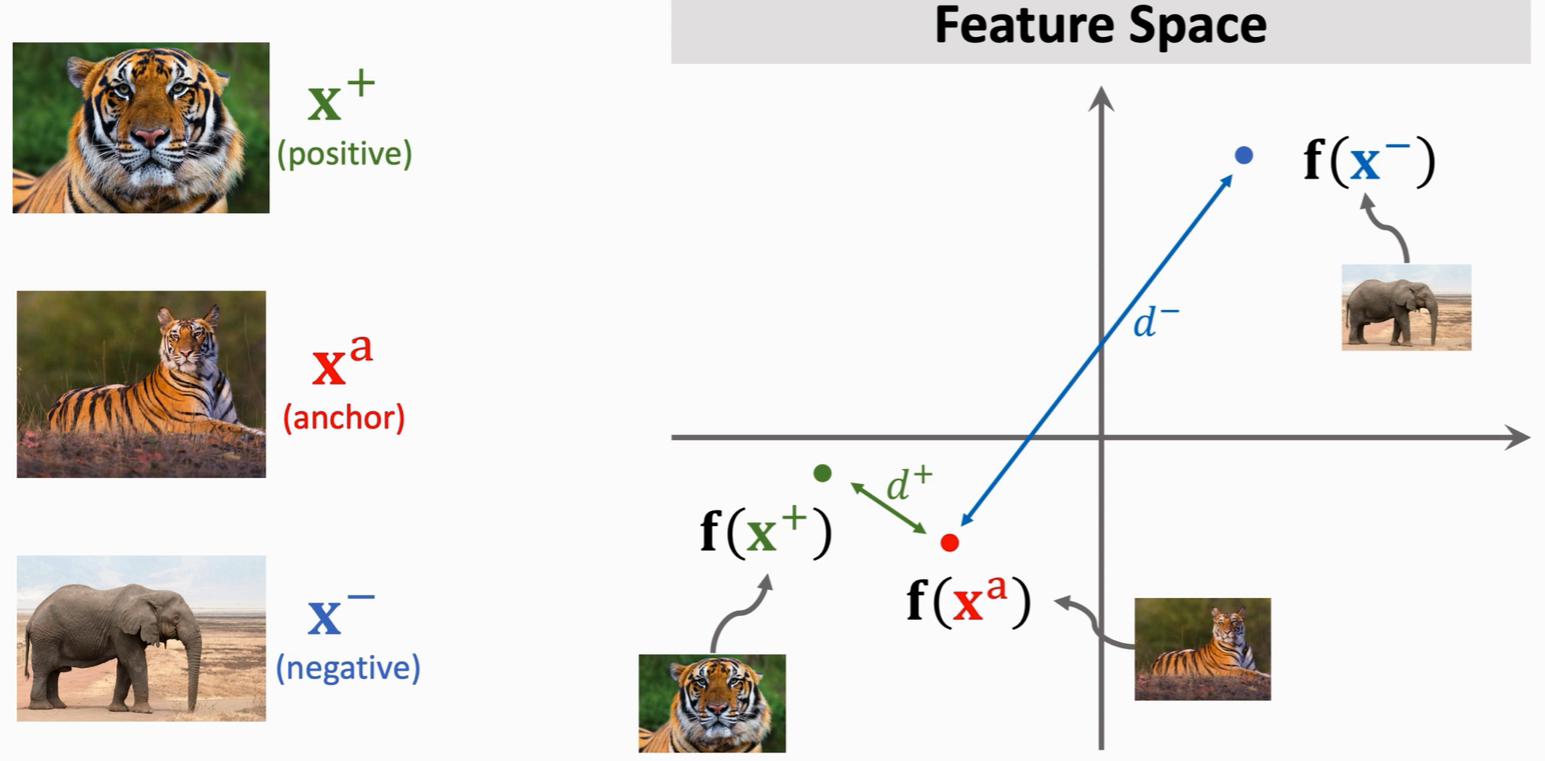
-
损失函数
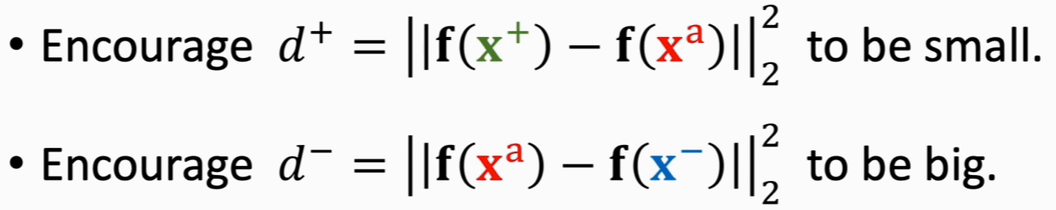
loss为零的情况:(d-) - (d+) >= α (α是我们设置的超参数) ,说明此时网络能区分正负样本
loss不为零的情况:若不满足上述 (d-) - (d+) >= α 条件,则令 loss = (d+) + α - (d-) , 在优化过程中,我们希望loss越小越好,此时就会朝着 d+ 变小且 d- 变大的方向优化,那么就会使得同一样本距离越来越小,不同样本越来越大


-
测试
由上述方法得到的神经网络,最终输出为 d+和d- ,我们此时将 Query输入网络,得到dist,找出最小的那个dist即可