这篇论文把图像卡通化分解成所谓的“白盒”。代码开源。就是之前的方案是一股脑梭哈,原图和风格图扔到网络里然后通过约束特征也好或其他操作输出风格后的图像。这篇工作把这一过程分解,使得可控。具体分解如下:
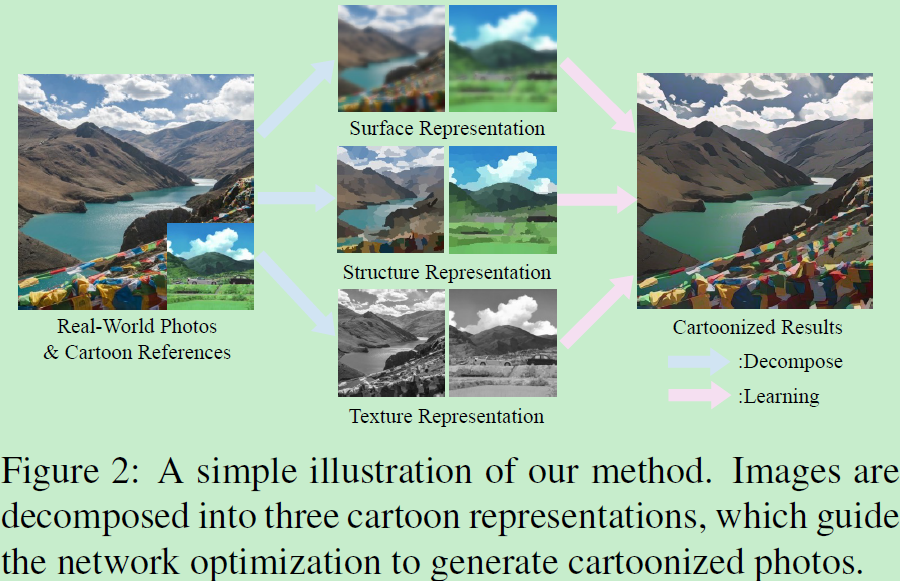
原图和风格图操作时分为三个模块:surface表征、structure表征、texture表征。
先上结构图,然后分别分析三个模块:
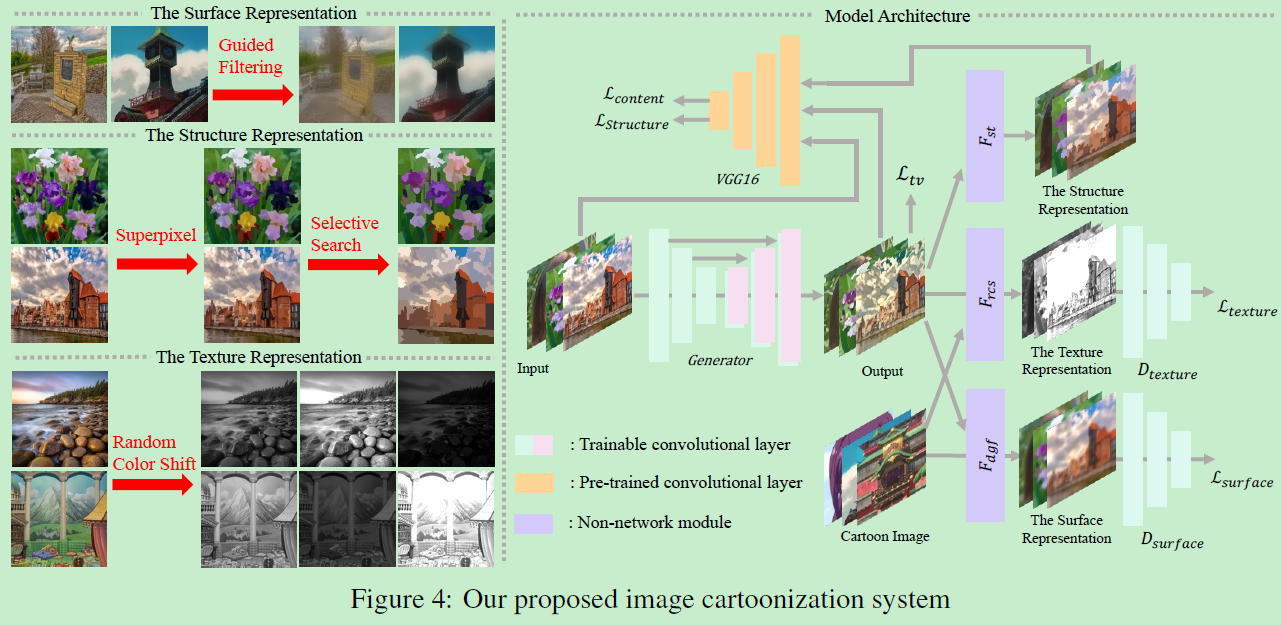
第一个模块:Learning From the Surface Representation
顾名思义,结合图1看,这个表征主要是粗表征,平滑图像也仍保持全局语义结构,但是细节不保留。这块用到一个判别器,公式如下:

很好理解,就是原图和生成的卡通图像。
第二个模块:Learning From the Structure representation
这个模块的作用估计全局内容,边界等首先利用felzenszwalb(超像素)算法分割图像为分离的区域,然后利用selective search来合并一些区域,因为超像素没有考虑语义。
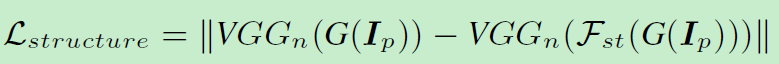
这里没判别器,利用vgg特征来约束。
第三个模块:Learning From the Textural representation
这部分是高频特征,即图像内容信息,但是要减少色彩影响,于是对rgb三通道进行加权操作:
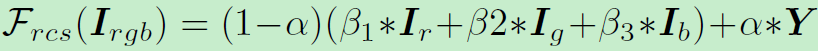
这里有用到了另一个判别器:
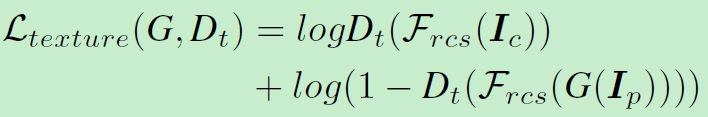
整体而言,动机明确,此时也发现一些paper的思路:耦合或者解耦。只要合理work就是一个值得研究的方法。
