会议:2019 icassp
单位:中科大
作者:zhangyajie, lingzhenhua
文章目录
abstract
使用Tacotron+VAE的方法进行E2E-TTS的style control。
选择VAE的原因是在解耦,缩放以及拼接能力上都表现优秀,有助于无监督风格控制和风格转换。
1. introduction
【2018 interspeech】Expressive speech synthesis via modeling expressions with variational autoencoder (Akuzawa)也使用TTS+VAE的方法,与之不同的是:(1)Akuzawa的目的是生成有表现力的语音,直接采用inference过程中生成的latent emb,我们的目的是进行风格控制 ,会修正生成的prior of latent distribution;(2)我们是基于E2E-TTS,而Akuzawa不是。
2. MODEL
2.1 VAE
KL散度与交叉熵区别与联系,讲的很好
VAE loss = reconstruct loss - KLD
reconstruct loss: 作用在decoder上,预测样本和真实样本
KLD: encoder预测结果z和高斯分布的交叉熵
KLD = -0.5 * torch.sum(1 + logvar - mu.pow(2) - logvar.exp())
encoder先输出两个值,分别指代为均值,方差,然后通过如下计算得到z;(logvar是encoder直接的数据,等同于 l o g σ log \sigma logσ
eps = Variable(std.data.new(std.size()).normal_()) # 符合0-1高斯分布的一个随机采样点
z = eps.mul(std).add_(mu) # 计算的均值方差下的高斯分布,z是符合这种分布的一个采样点
- KLD和reconstruct loss的形式都会是多样的
2.2 Proposed Model Architecture
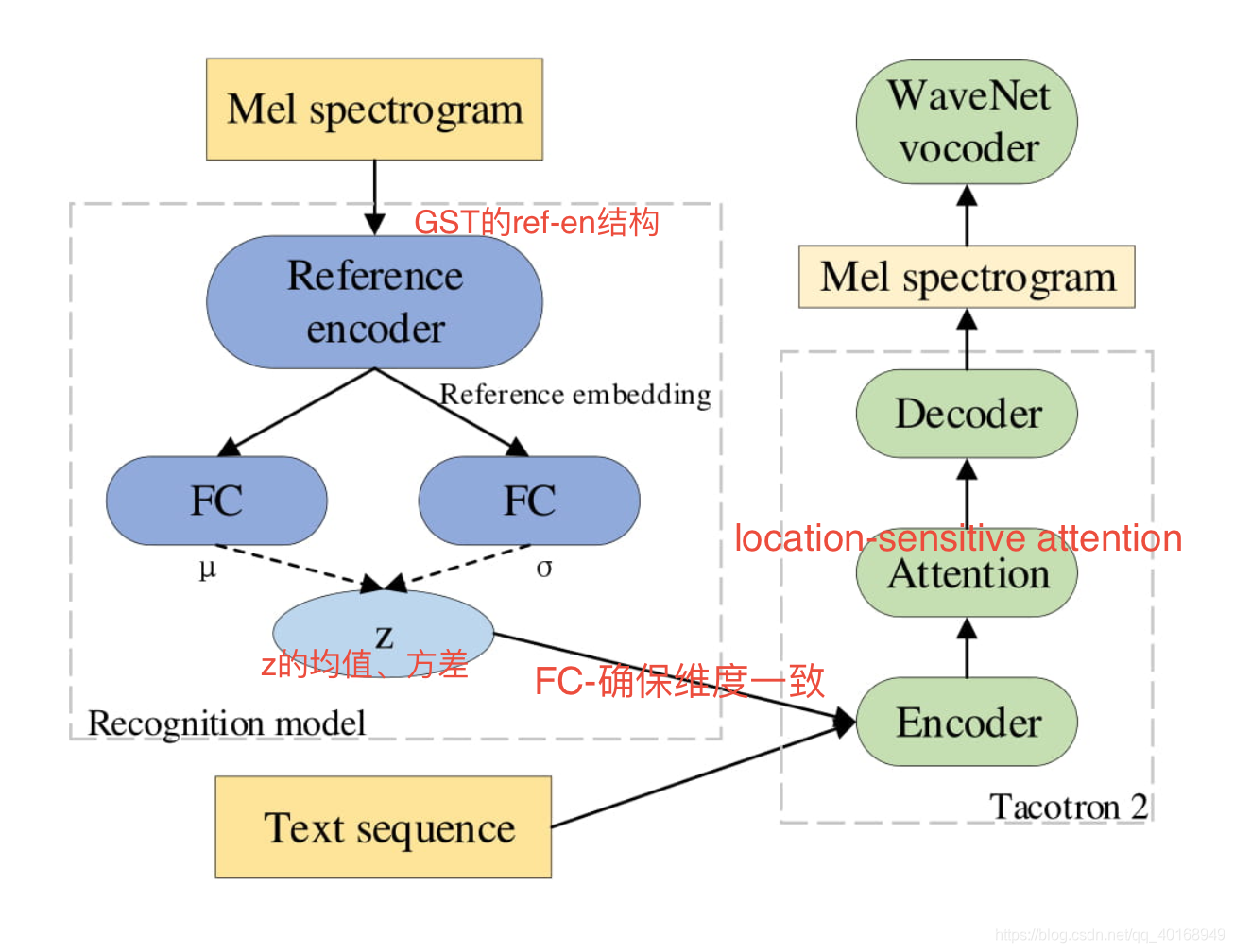
loss函数的设计有问题:会遇到KL collapse的问题,原因是:KL Loss的收敛速度很快,收敛为0附近的时候重建损失还没有收敛,因此encoder会无效,为了避免这个问题,使用两个trick:
- (1)KL annealing :KL Loss加一个权重,初始是0,然后慢慢增加;
- (2)每k步考虑一次KL Loss

3. EXPERIMENTS AND ANALYSIS
3.2.1. Interpolation of latent variables
3.2.2 Disentangled factors
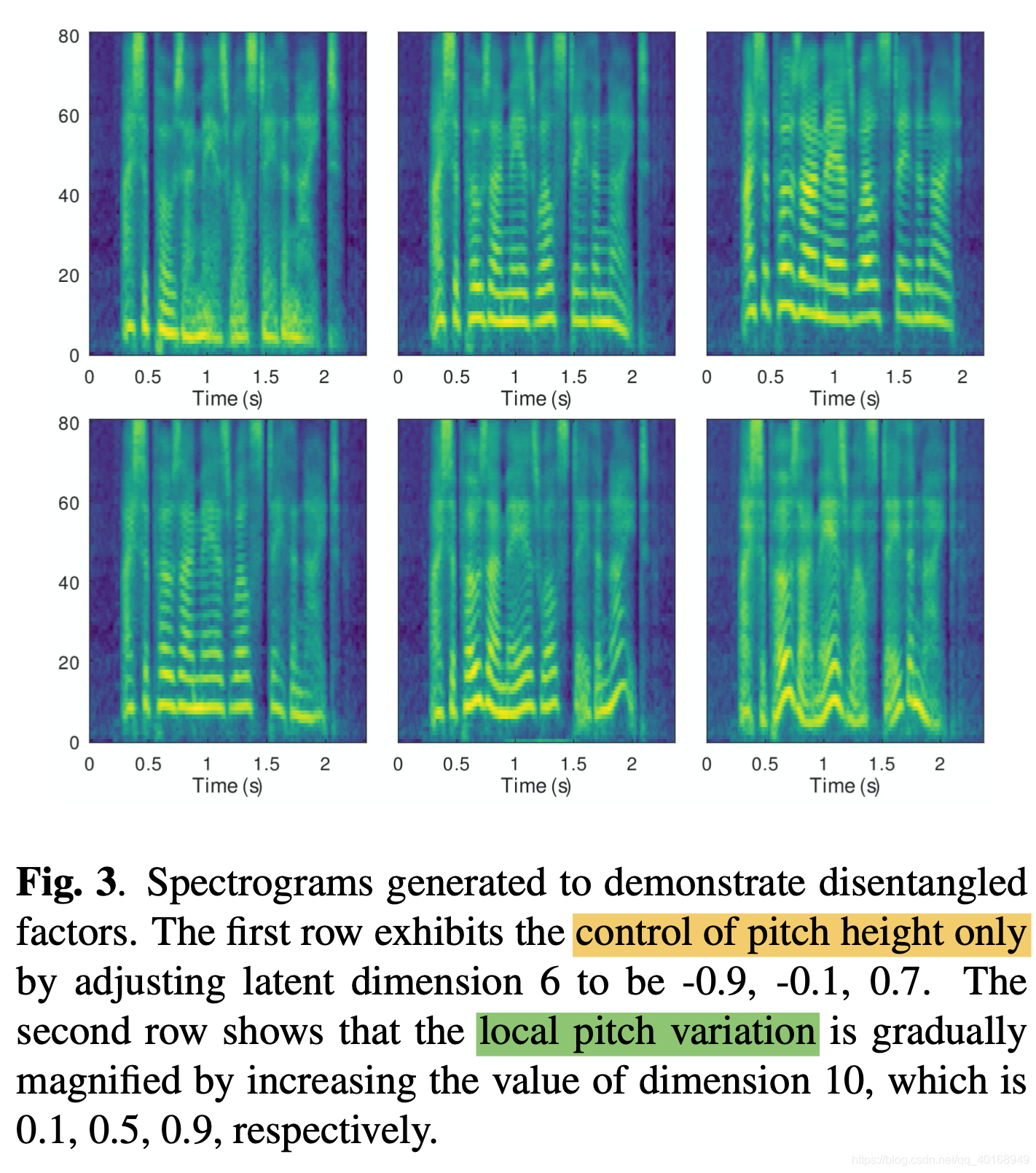
结果分析表明latent representation的不同维度可以单独控制不同的风格,比如pitch-height, local pitch variation, speaking rate等。
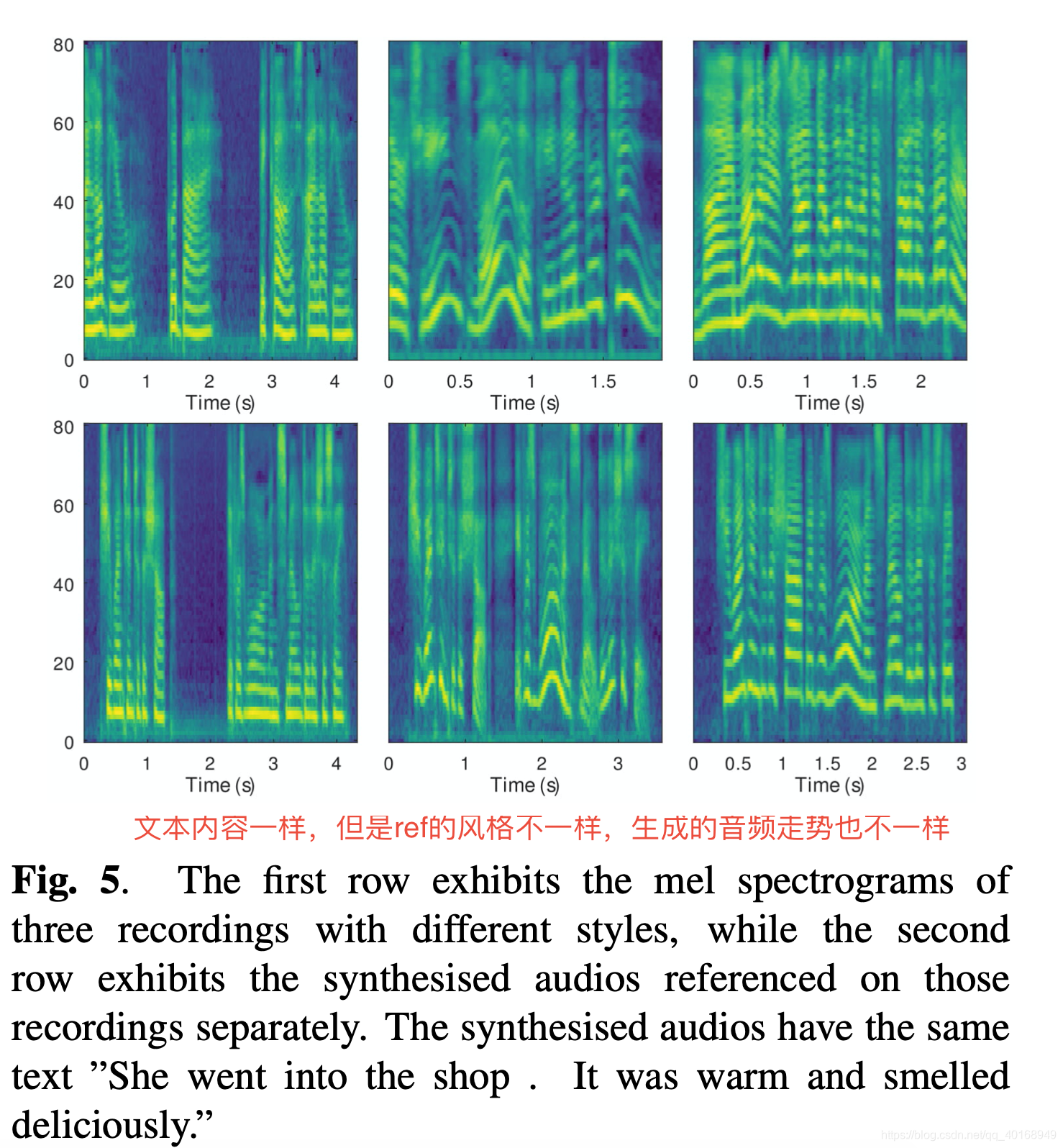
3.2.4 style transfer
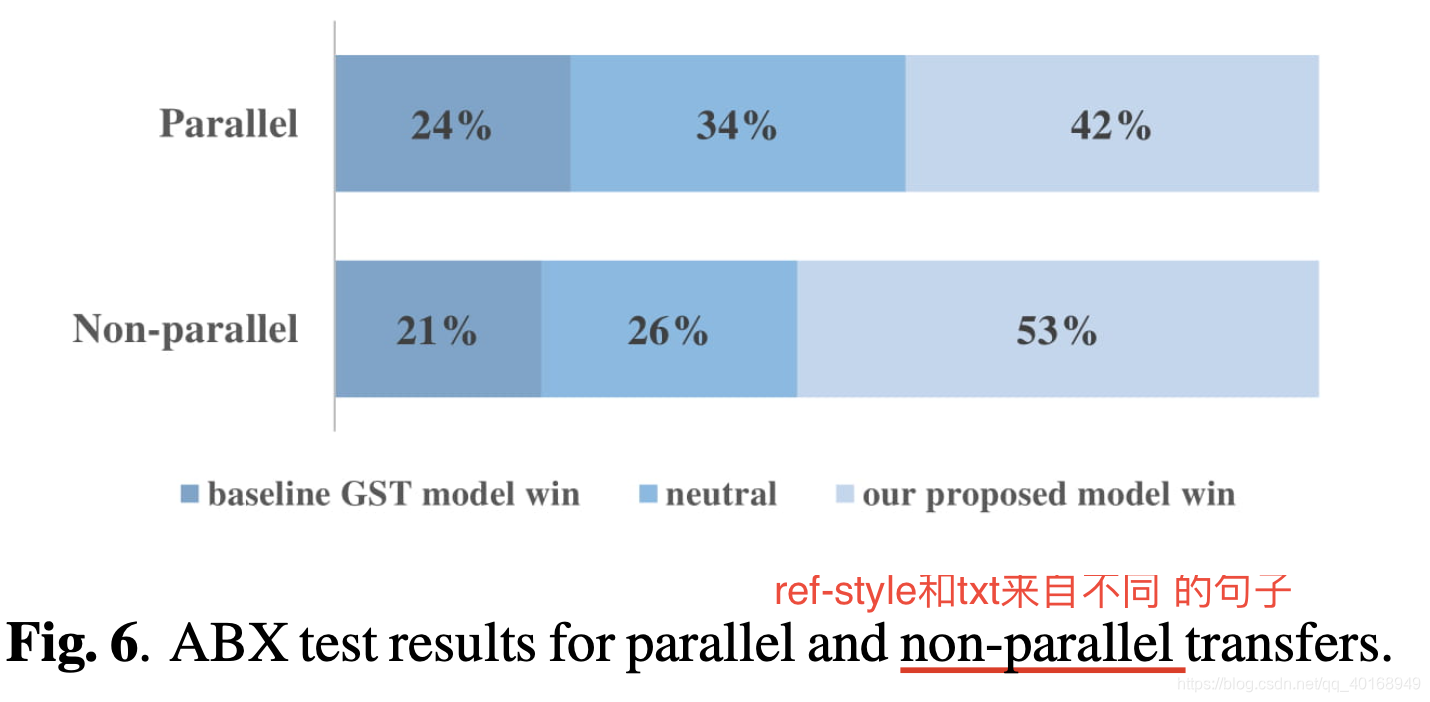
3.2.5 主观测试