解决什么问题
从一个单视野恢复3D bounding box,在没有额外的3D形状模型、或有着复杂的预处理通道的采样策略下,估计稳定且精准3D目标
方法
方法概述
先直接回归方向和目标维度,用的是CNN方法。给定估计的方向和尺寸,以及3D边界框的投影与2D检测窗口紧密匹配的约束条件,就能恢复出移位,从而得到目标的3D bounding box
问题分析
对于回归参数的选择,作者选择回归维度D,而不是移位T,因为维度估计的多样性更小,大部分的车都差不多大,而且不会随着车的方向改变而改变。维度估计和物体的亚种有很强的联系,如果能识别出这个亚类的话,恢复可能变得精准
亚种就是说知道是那种型号的小汽车
作者也做了实验,回归T的话,很少得到准确的3D框,使用CNN和2D检测框回归出来的3D盒的维度和方向能解决 的问题,而且能最小化初始的2D检测框约束的重射影误差
所以作者选择利用方向和维度,以及2D框来得到位移
3D bounding box estimation
主要思想是3D包围盒在2D检测窗口中的透视射影,作者做出了一种假设:CNN出来的2D框就是3D盒的射影
这个假设很有可能不成立
维度:
维度直接回归,先算数据集的中位数,然后预测偏差,维度就是中位数+偏差
方向:
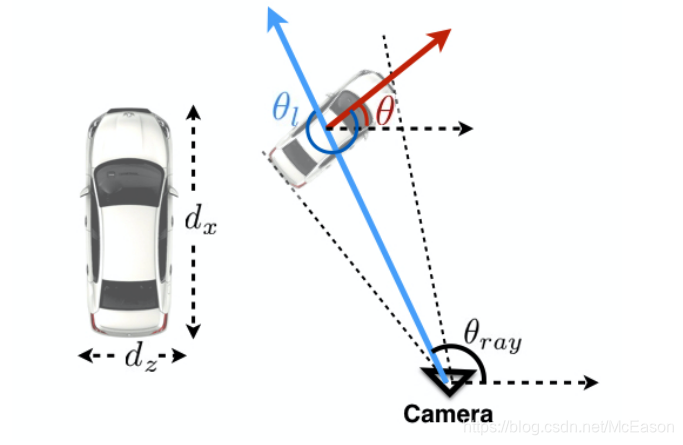
只从检测出来的框来估计全局物体方向是不可能的,还得有位置信息才行。

由于透视,一辆车的全局角度可能没变,但是局部角度变了,所以回归的是局部参数,局部角度
和
角结合,就是全局角度
给定摄像机的内参,就能知道射线角,这样再用网络回归出 ,就能算出
用内参将像素平面转换成图像平面,焦距为1,根据 就能算出角度
L2 loss处理复杂的多模式的回归问题并不好用。L2 loss 鼓励网络最小化平均loss,但这样会导致对每个模型的估计都很差
如果有些占的loss很小,是不是就没什么影响了?,是不是应该再加入一些权重因子?
因此,借鉴了Faster RCNN 和SSD的思想 :不直接回归框,而是通过对anchor box进行调整。
首先将方向角离散到 个重叠的bin中。对于每个bin做以下两个处理:
- 用CNN预测在 bin中存在角度线的置信度 (虽然重叠在一起了,但是没有关系,感觉就跟分类差不多,每个bin都代表一个类,类就是方向,看属于哪个类,也就是那个方向,置信度因此也不一样。)
- 为了获得输出角度,应该在bin的中心射线的方向上施加残差旋转矫正,残差旋转用两个数表示: 。(这个残差就是微调)
所以,一个bin对应三个输出:
的值是通过对2维输入做L2正则化得到的。
也是CNN算出来的?之后加上L2正则化就能得到这个吗,是cos和sin的loss影响了 吗?
不是,是直接用网络预测cos和sin的值,然后根据tan来得到
中心:

3D到2D射影约束的要求:每个角点都至少落在一条边上
这个点对侧面对应约束产生了这个方程

2D检测盒的每一侧都可以对应于3D盒的八个角中的任意一个,从而得到 的配置。每一种不同的配置都涉及到求解一个过度约束的线性方程组,该方程组计算速度快,可以并行求解
但是,很多场景下物体都是竖直的,这种情况下,2D的框的上下边也就只能对应3D盒子的上边和下边的顶点的射影。这样就会减少到1024的计算量
此外,当相对物体滚动接近于0时,垂直二维盒侧坐标 和 只能对应垂直三维盒边的点投影(就是2D框的左右两条线,每条都有四种可能), 和 只能对应水平的3D边的点射影(就是上下两条线),这样垂直的2D边只能对应垂直的3D边,所以变成 种可能。
物体俯仰和滚转角都为零(所以上面和下面,四个点,但是只需要两个点,平行的点效果是相同的),这进一步减少了配置的数量到64。
然后对这些做PnP,找到最小重投影误差的就是正确解,此时R,T都有了,通过射影就能知道中心点的位置。
训练

角度loss
等于每个bin的置信度的softmax损失。
是计算包含着ground turth angle的bin中,估计的angle和真实的angle的差别的最小值的loss,相邻的bin会有重叠的部分。
在
中,所有的覆盖真实angle的都必须估计正确的angle,最小化不同等同于最大化cos距离
是包含了真实angle的bin的数量
是真实angle
是
bin的angle
是需要对
bin的中心做出的矫正
视角分布越多杨,越需要多的bin:

维度loss
是box的真实维度
是一个种类的物体的平均维度
是对网络预测出来的维度做微调
总loss
实验
在图像周围滑动一个小的灰色块,对于每个位置,记录估计方向和真实方向之间的差异。
如果模糊了一个地方对输出的结果产生了很明显的影响,那么证明网络很关注这个部分,下面展示关注点图:

这也是一种关键点思路,但是作者的方法不需要ground truth标注,而且作者的方法是学习特定任务的局部特征,人为标注的关键点不一定是最好的。
可能人自以为重要的,其实不重要。
这个方法在inference的时候就能用,对图像模糊处理,输出预测,根据预测结果在当前模糊的地方相同的图片上标注出影响力。
所以就算知道了注意力在哪又有什么用?如何使用?是对权重进行限制吗
答:可以加个注意力模块
总结
作者的关于角度的回归选择被很多论文引用,大部分都是用的这种非自我中心的角度回归方法,也有很多用bin来算角度的;但是对于T,这种假设并不好,还依赖检测器的表现
