文中所有灰色引用部分都是在阅读文章时的思考,阅读时可直接跳过灰色部分,不会影响内容
本文创新点
1.从2D框中约束出t,从CNN中回归出方向和尺寸
2.提出用于回归方向的MultiBin
3.提出三个新度量
4.解释了在3D pose估计框架中,选择回归参数的重要性。
作者Ideal来源
见MultiBin部分
作者方法
核心思想
用两个深度卷积神经网络回归相对稳定的3D物体属性(方向,长宽高),然后将这些属性和2D目标bounding box的几何约束结合起来,生成完整的3D bounding box。
- 第一个网络用提出的MultiBin loss,来生成3D物体的方向,性能比L2 loss强很多
- 第二个网络输出回归3D目标的维度,跟回归其他的参数相比,维度的差异相对较小,并且可以利用先验知识
目标
3D框的属性:
- 中心:
- 维度:
- 方向:
MultiBin loss
回归参数的选择:
1.维度
作者选择回归维度D,而不是移位T,是因为维度估计的多样性更小,大部分的车都差不多大,而且维度不会随着车的方向改变而改变。
维度估计和特别的物体的亚类有很强的联系,如果能识别出这个亚类的话,或许可以恢复的更精准,作者也做了实验,回归T的话,很少得到准确的3D框。
是不是说知道是什么东西,就可以按照针对这个东西的模型来估计他的大小,可以将结果的下限提高
答:就是先验知识
目标进展:

- 中心:
- 维度:
- 方向:
2.方向
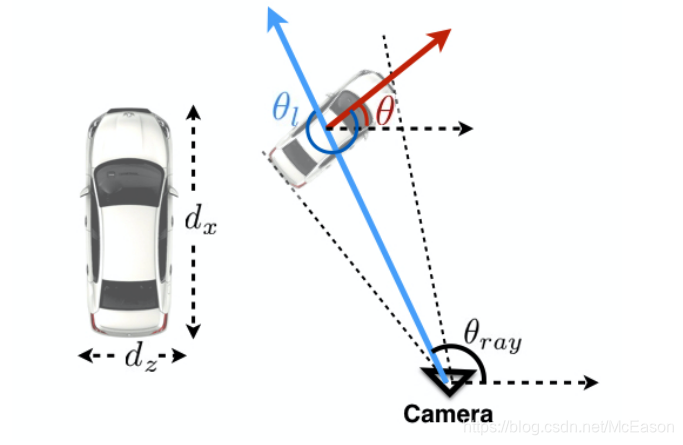
由于透视,一辆车可能并没有改变全局方向,但是他的局部方向可能随着跟摄像机的距离变化而变化。
比如,一辆车在马路上笔直行驶,但摄像机拍摄的车的方向却在一直变化:

所以,回归的参数应该是局部角度
,局部角度
和
(该角度给定摄像机内参就能知道)结合,就是全局角度
:
之前都用L2 loss来计算角度,L2 loss处理复杂的多模式的回归问题并不好用。L2 loss 鼓励网络最小化平均loss,但这样会导致对每个模型的估计都很差
如果有些占的loss很小,是不是就没什么影响了?,是不是应该再加入一些权重因子?
因此,作者借鉴了Faster RCNN 和SSD的思想 :不直接回归框,而是通过对anchor box进行调整。
那是不是也可以用Anchor free的方法来做,效果会不会更好?
首先将方向角离散到 个重叠的bin中。对于每个bin做以下两个处理:
- 用CNN预测在 bin中存在角度线的置信度 (第一种理解:虽然重叠在一起了,但是没有关系,感觉就跟分类差不多,每个bin都代表一个类,类就是方向,看属于哪个类,也就是那个方向,置信度因此也不一样。第二种理解:每个bin都都包含了该像素点的位置,只有这部分是重叠的)
- 为了获得输出角度,应该在bin的中心射线的方向上施加残差旋转矫正,残差旋转用两个数表示: 。(这个残差就是微调)
所以,一个bin对应三个输出:
的值是通过对2维输入做L2正则化得到的。
也是CNN算出来的?之后加上L2正则化就能得到这个吗,是cos和sin的loss影响了 吗?
至此,可知网络结构如下:

目标进展:
- 中心:
- 维度:
- 方向:
约束
主要思想:3D包围盒在2D检测窗口中的透视射影
前置知识:
给定摄像机内参矩阵K,将物体坐标系中的3D点
投影到图像中的点
的公式是:
作者做出了一种假设:CNN出来的2D框就是3D盒的射影,并且3D框的中心就是世界坐标的中心(对后面的求解T很关键)。
如此,那么2D框和3D包围盒将会满足一条约束:2D边框的每一侧都将被至少一个3D边框角的投影所触及,如下图所示:

点之间的约束对应满足如下的公式:

但是这样也只有四个约束(3D中四个点分别对应出 , , , 就能得到一个2D框了),是不够推出9个自由度(3个旋转,3个平移,3个尺寸)的,所以就要将外观也考虑进来。
考虑到外观之后:
- 一般情况:
2D检测盒的每一侧都可以对应于3D盒的八个角中的任意一个,从而得到 的配置。 - 当物体是竖直时:
这种情况下,2D的框的上下边也就只能对应3D盒子的上边和下边的顶点的射影。这样就会减少到1024的计算量: - 当物体滚动(roll)接近于0时:
垂直二维盒侧坐标 和 只能对应垂直三维盒边的点投影。 和 只能对应水平的3D边的点射影,这样垂直的2D边只能对应垂直的3D边,所以变成 种可能。 - 当物体俯仰(pitch)和滚转角都为0:
减少了到了64的可能性。
对于这个计算我自己算了之后是觉得有问题的,到了一开始的竖直不就是roll=0的意思吗?
然后根据作者的在补充材料里的方法,知道了3D框的方向、尺寸和2D框的约束,最小重投影误差就能得到平移矩阵T
重投影误差的计算已经忘了,补充材料还没看
补充材料
目标进展:
- 中心:
- 维度:
- 方向:
求解T大体流程:
之前假设3D框的中心就是原点,现在知道了长宽高,那就可得八点坐标,3D坐标get;
因为假设3D框的方向和世界坐标相同,所以回归出来的方向就可以当成相机的旋转矩阵,R矩阵get;
然后根据约束,最小化重投影误差得到T
这里是根据64种4点约束来做的吧。
训练
数据增强
每个预测的2D框和真实的2D框裁剪的大小resize成224x224。
VGG16的输入大小
为了更好的鲁棒性,做了数据增强,让真实框抖动,并且真实 随着裁剪的中心射线的移动而移动。
抖动后的角度就要重新计算了
还增加了颜色扭曲和镜像。
网络结构及loss
使用预训练的VGG,将后面的FC曾去掉,换成如下的网络。
在每个方向分支的第一个FC层中有256维度,而用于维度回归的第一个FC层的维度为512。
维度有什么说道吗?
角度loss

等于每个bin的置信度的softmax损失。
是计算包含着ground turth angle的bin中,估计的angle和真实的angle的差别的最小值的loss,相邻的bin会有重叠的部分。
重叠会影响计算效率吗?看看代码就知道会不会了,会的话如何改进来减小能耗呢?
在 中,所有的覆盖真实angle的都必须估计正确的angle,最小化不同等同于最大化cos距离,原理在附录1中有解释。
的计算公式:

是包含了真实angle的bin的数量
是真实angle
是
bin的angle
是需要对
bin的中心做出的矫正
维度loss
车辆的维度变化不大,可能不同的车辆之间就差了几厘米,所以也不用那么麻烦,直接用L2 loss来计算,先计算每个种类的车的维度平均值,然后用残差来微调:

是box的真实维度
是一个种类的物体的平均维度
是对网络预测出来的维度做微调
实验
参数设置:
SGD的学习率是0.0001
做了batch是8的迭代20K次,从交叉验证中选最好的模型。
度量标准:
Orientation Score(OS),代表
,所有样本的平均值,还能转换成angle的误差
,3°属于小误差,6°是中等,8°是大误差。
MultiBin loss分析:

视点分布越多样,越需要选择多的Bin

FC的跨度超过256会有少许提升。
作者的方法的一个缺点:
它需要学习全连接层的参数,与使用附加信息的方法相比,它需要更多的训练数据。
Implicit Emergent Attention:
在图像周围滑动一个小的灰色块,对于每个位置,记录估计方向和真实方向之间的差异。
如果模糊了一个地方对输出的结果产生了很明显的影响,那么证明网络很关注这个部分,下面展示关注点图:

这也是一种关键点思路,但是作者的方法不需要ground truth标注,而且作者的方法是学习特定任务的局部特征,人为标注的关键点不一定是最好的。
可能人自以为重要的,其实不重要。
这个方法在inference的时候就能用,对图像模糊处理,输出预测,根据预测结果在当前模糊的地方相同的图片上标注出影响力。
所以就算知道了注意力在哪又有什么用?如何使用?是对权重进行限制吗
Alternative Representation:
作者还尝试了别的思路:
回归3D框的中心投影在图像上的位置:这样能恢复指向3D框的中心的摄像机射线。
有了3D框中心在2D上的射影和box方向,估计一个参数 就能知道点的位置。
有了中心投影在图像上的位置和 就能得到3D框的方向了?不是还需要一个 吗?
只有一个点也没法做PnP啊
然后还需要估计维度:此时有四个约束(max和min),有四个未知量要求解。
虽然在这种表示方法中需要回归的参数数量比所提出的方法少,但是这种表示方法对回归误差更敏感
当盒子的物理尺寸没有约束时,即使loss很低,2D框对应的3D框也可能不合理。

推理
挑选出置信度最高的bin,最后的输出还要在bin的中心用上
。
Multi-bin模块有两个分支,一个计算
,一个计算
的
,所以
个bin有
个参数。
性能
虽然概念简单,但是作者的方法比那些利用语义分割、实例级分割和平地先验以及子类别检测的更复杂和计算开销更大的方法有更好的性能。
为了测试,用真实3D盒子,加入了一些噪声来模拟误差,但是方向误差和盒中心估计误差较小,盒的尺寸误差较大,如下图所示:

