该论文录用于AAAI 2020,相关工作已开源,论文链接 & 代码链接。作者团队:中科院自动化所&地平线,第一作者王绍儒是地平线实习生,来自中科院自动化所的硕士生。
论文对当前目标检测及实例分割算法的现状进行了简要的概述,并对各种方法的优劣进行了简要的分析,据此提出了一套完整的框架,同时完成目标检测与实例分割任务,并且两个任务相互辅助,同时取得了性能的提升。
一、问题提出
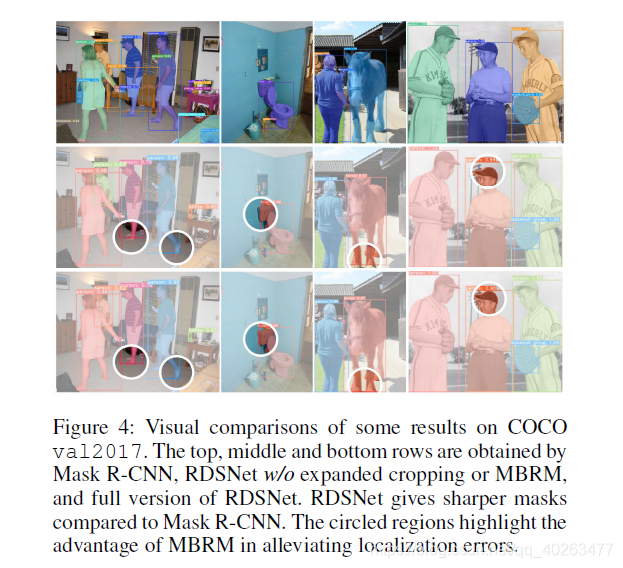
目标检测与实例分割是计算机视觉领域重要的两个任务,近年来出现了非常多优秀的算法解决这两个问题,且都取得了优异的效果,但是,却鲜有文章深入分析两者之间的关联,也就导致了诸如下图所示的错误的出现:

图中所示结果由 Mask R-CNN 得到,可以看到由于边界框定位不准导致的实例掩码缺失((a), (b))及边界框与实例掩码不统一的问题(( c), (d))。这些问题都可以在这篇论文提出的算法中得到很好的解决。
二、方法介绍
算法框架如下图所示:
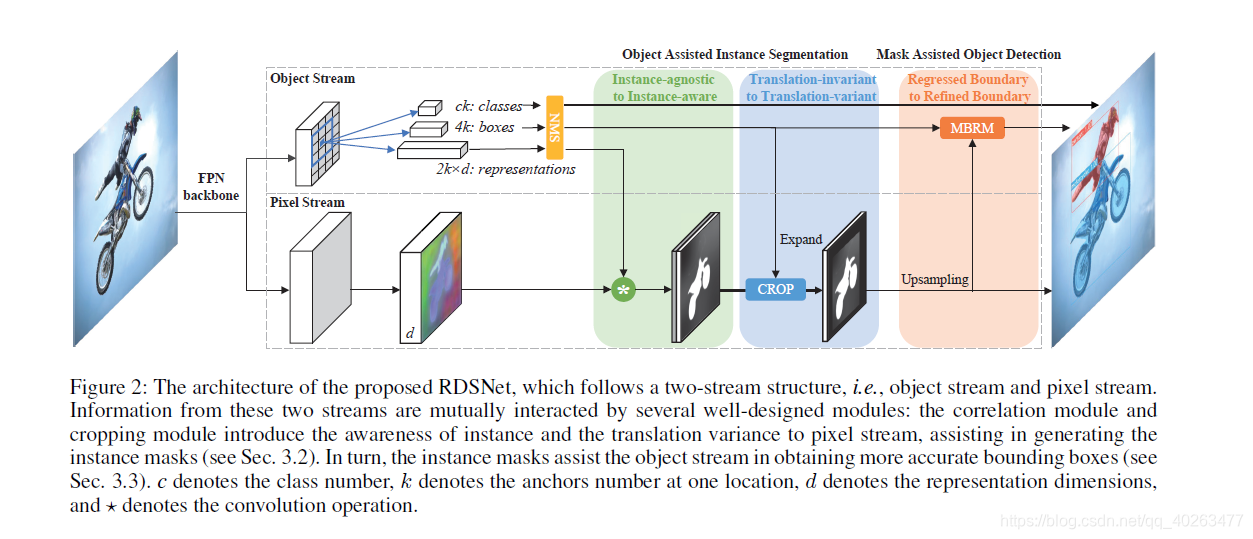
文章中认为:目标检测属于 object level 的任务,这类任务更关注物体级别的特征,对分辨率的需求不高,但需要更多的高级语义信息;而实例分割任务属于 pixel level 的任务,这类任务需要给出逐像素的输出,对分辨率的需求较高,需要更多的细节信息。
因此便设计了如图所示的双流网络,上面的 object stream 重点完成目标检测任务,可以是 SSD, YOLO, RetinaNet 等任一 anchor-based 的目标检测算法(文中采用了 RetinaNet);下面 pixel stream 重点完成分割的任务,分辨率很高(文中采用了类似 PanopticFPN 的方式融合了多尺度的特征,得到了高分辨率的输出);后续的若干操作则是文章的重点,介绍了如何使得两个任务相互辅助:
“物体”辅助实例分割:
目前常见的实例分割算法分为两类,一类是类似于 Mask R-CNN 的 proposal-based 的方法,是目标检测算法的直接扩展,但这类方法会面临上文提到的诸多问题:得到的实例掩码分辨率相对较低且严重依赖于 proposal 的边界框;另一类基于分割算法,首先预测每个点的 embedding,然后再通过聚类得到每个实例的掩码(属于相同物体的点具有相似的 embedding,通过聚类,即可使得属于同一物体的点形成一个簇,也就得到了每个物体的掩码),这类方法天然克服了 proposal-based 的缺陷,但一般无法 end-to-end 训练(一般需要 metric learning 的方式训练 embedding),且受限于聚类算法,性能一般有限。
仔细分析发现,聚类的难题主要源于聚类中心的缺失,换句话说,如果我们拥有每个簇的中心,我们就可以抛弃聚类算法,进行 end-to-end 的训练;而这个「中心」,应该是每个物体的 embedding,也就是说,它应该源于 object level,而非 pixel level!因此,也就形成了论文里提出的基于相关滤波的实例掩码生成算法:
Object stream 和 pixel stream 分别提取 object 和 pixel 的 embedding(object embedding 的获取方式也很简单,直接在目标检测算法的 detection head 中在 classification 和 regression 分支的基础上额外增加一个分支进行预测就可以),属于同一物体的 pixel 和与其对应的物体具有相近的 embedding,相似性的衡量采用了内积相似度,也就是说:对于每个检测到的物体,以其 embedding 作为 kernel,在 pixel embedding 上执行相关滤波,即可得到这一物体的掩码。
除此之外,文中还充分利用了 object stream 得到的目标边界框,对距离物体中心较远的噪声进行了抑制,本质上是在一定程度上克服 CNN 的 translation-variant 对实例分割任务的影响。
“掩码”辅助目标检测:
边界框定位是目标检测的一项重要任务,而现有的方法大多采用回归的方式得到边界框的位置。然而我们回顾边界框的定义,发现它本身就是通过物体的掩码定义的(minimum enclosing rectangle of an object mask)!那么,既然我们可以得到物体的掩码,为什么还要依赖于回归算法,多此一举呢(前提是物体掩码的获取应该不依赖于边界框)?然而文中通过实验发现,直接利用通过上述基于相关滤波方法得到的实例掩码生成边界框,精度并不太高,甚至低于回归方法得到的边界框!文章作者通过可视化发现:大多数物体的掩码都可以提供十分准确的边界框,然而也存在部分物体的掩码预测结果不太理想,使得边界框出现了较大的偏移。
据此观察,文章提出了一种基于贝叶斯公式的边界框定位算法,首先将边界框定位定义为分类任务(在 width/height 维度上某个坐标是不是物体的边界),将问题转化为给定物体掩码,坐标属于边界框的后验概率的预测:
然后利用贝叶斯公式,将回归得到的边界框作为先验概率 P(X=i),而 P(M |X=i) 则由物体实例掩码通过逐列(行)取最大、一维卷积和激活函数得到。
整体过程如下图所示:

此方法综合考虑了回归得到的边界框和实例掩码的优势,得到了更准确的边界框。具体结果可以看下图,可以明显发现,由此方法得到的边界框可以以更高的 IOU 和 ground truth bbox 匹配。
三、实验结果
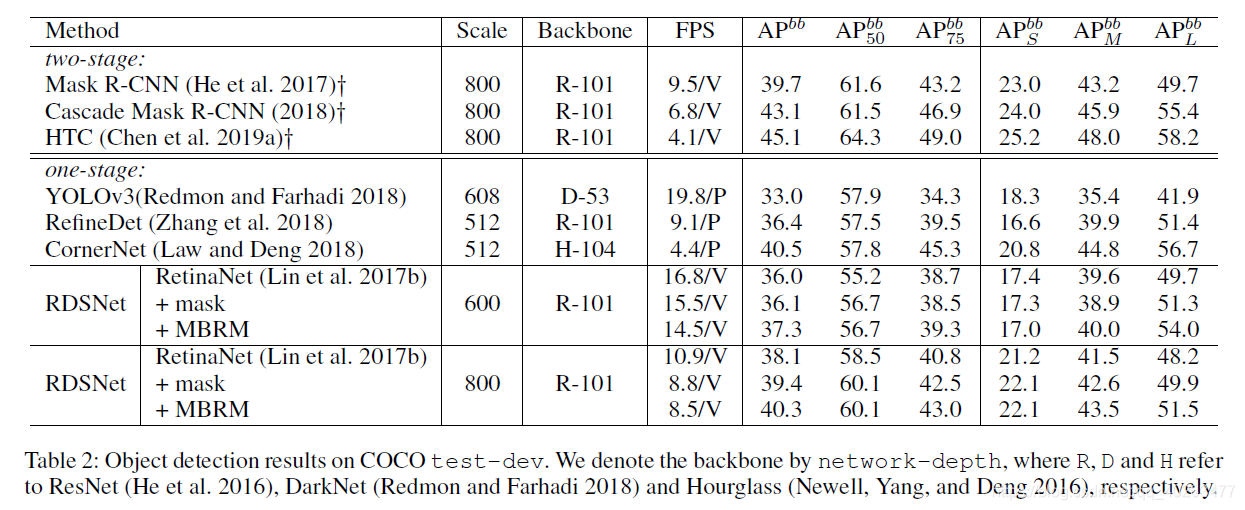
文章在 COCO 数据集上进行了实验验证:
在实例分割任务中,此方法在单阶段算法中可以达到更优的速度与精度的平衡,以近 3 倍的速度取得了和 TensorMask 相近的精度,以相近的速度在 YOLACT 的基础上取得了 2.3mAP 的提升。
在目标检测任务中,此方法以极低的计算代价在不同的 backbone 上取得了一致的性能提升。
值得注意的是:文章中采用的是 RetinaNet 作为 detector,且在其基础上扩展到实例分割任务中并不会带来显著的计算量的增加,如果采用其他更先进的目标检测算法,其精度与速度还能取得更进一步的提升。
四、一些题外话
文章的解读到此已经结束,但是作者还提供了一些其他的角度来理解这篇文章:
Anchor-based or Anchor-free?
Anchor-free 可以算得上是 2019 年目标检测领域爆火的词汇,本文也蹭一下热点,分析一下和这篇论文的关联。
仔细观察这篇文章提出的算法框架可以发现,object stream 实际上是 anchor-based,而 pixel stream 则是 anchor-free:object stream 中的 detector 可以由很多目标检测算法充当,包括但不限于 SSD, YOLO, RetinaNet, 甚至可以是两阶段的 Faster R-CNN;而 pixel stream 不只可以预测 pixel embedding,还可以额外预测边界框角点(类似 CornerNet),或人体关键点(类似于 Assoc. Embed.),或是其他物体实例像素级的表征;而这两个分支通过相关滤波联系到一起,一定程度上解决了如 CornerNet 中的 grouping 的问题。从这个角度说,这篇文章提出的框架算得上是真正的 anchor-based 和 anchor-free 的结合,未来可能催生出更多有意思的工作。
Bbox or Mask?
正如 Ross 大神在 ICCV 的 Tutorial 上提到的内容,object detection 是一个很广义的概念,不同的物体表征也对应着不同 level 的任务:例如:bbox 对应着传统意义上的 object detection,mask 对应着 instance segmentation,human keypoints 对应着 pose estimation,human surfaces 对应着 dense human pose estimation……这些任务相互关联,对应着不同角度、不同 level 的对物体的理解。现有的方法或是将这些问题独立看待,或是 high-level task 直接建立在 low-level task 上(例如 Mask R-CNN,两阶段的人体姿态估计等),但这些任务的关联绝不仅限于此。这篇文章的关注点是 bbox 和 mask 的关联,但也并未做到极致。从这个角度说,object detection 仍然还有巨大的发展空间。
参考文献
[1] Kaiming He, et al. “Mask R-CNN.” In Proceedings of IEEE International Conference on Computer Vision. 2017.
[2] Wei Liu, et al. “SSD: Single shot multibox detector.” In Proceedings of European Conference on Computer Vision. 2016.
[3] Joseph Redmon and Ali Farhadi. “YOLOv3: An incremental improvement.” arXiv preprint arXiv:1804.02767 (2018).
[4] Tsung-Yi Lin, et al. “Focal loss for dense object detection.” In Proceedings of IEEE International Conference on Computer Vision. 2017.
[5] Alexander Kirillov, et al. “Panoptic feature pyramid networks.” In Proceedings of IEEE Conference on Computer Vision and Pattern Recognition. 2019.
[6] Xinlei Chen, et al. “Tensormask: A foundation for dense object segmentation.” arXiv preprint arXiv:1903.12174 (2019).
[7] Daniel Bolya, et al. YOLACT: Realtime instance segmentation. In Proceedings of IEEE International Conference on Computer Vision. 2019.
[8] Shaoqing Ren, et al. “Faster R-CNN: Towards real-time object detection with region proposal networks.” In Proceedings of Advances in Neural Information Processing Systems. 2015.
[9] Hei Law and Jia Deng. “CornerNet: Detecting objects as paired keypoints.” In Proceedings of European Conference on Computer. 2018.
[10] Alejandro Newell, et al. “Associative embedding: End-to-end learning for joint detection and grouping.” In Proceedings of Advances in Neural Information Processing Systems. 2017.
