原文
https://arxiv.org/pdf/1906.09756
初识
回顾只是:在RCNN这类两阶段检测器中,第二阶段的训练需要指定候选框是正类还是负类【背景类】,一般的方法是衡量候选框与
gt之间的iou是否大于某个值,如果大于则认为是正类→执行分类+回归任务,如果不是则认为是负类,只考虑分类loss
本文主要解决的一个问题就是消除检测结果中的close false positives,在rcnn的训练过程中,postive和negative是通过iou阈值u来定义的【bounding box与groundtruth之间的iou>u则认为是正类】。而这个值通常设置为0.5,这其实是一个非常宽松的阈值,这会导致检测结果产生很多的false positives(但人眼可以很轻松地进行剔除),如下图(a)所示。而采用较高的u值进行训练,则可以得到一个较好的预测效果,如图(b)所示。

文中的
quality of a detection hypothesis表示预测框与groundtruth之间的iou,quality of a detector表示训练过程中使用的iou阈值u,上图( c )展示了不同的quality
由上图来看,那不是直接提升训练时的u就能解决问题了吗?别急着下结论,作者又马上丢出下面一组实验结果:

作者选取不同的u值训练模型(0.5 - 0.7),上图依次展示了在不同阈值下的定位、分类和整体的性能。其中图(a)说明了,每个检测器都在input iou接近训练阈值u时提升最大【离baseline的增幅最大】;图(b)展示的是分类器的损失,峰值也出现在阈值u附近,并且可以看出来loss值也越高;图( c )中,u=0.6在iou阈值较高时,性能好于u=0.5的检测器,但u=0.7的却出现模型退化的情况(比u=0.6差),这说明了要提升模型的性能,不能简单的增加u值。
显然,高质量的检测结果需要高质量的候选框,但这不能通过简单地提升训练时的阈值u来实现。作者分析其原因在于两点:① 样本不均衡的问题,提升阈值u必然会大大减少训练过程中的正类候选框数量,这很容易导致过拟合;② 训练和测试时提供的候选框质量不一致,在训练时提供的都是高质量的候选框,训练得到的是高质量检测器,而测试集对于新的数据不一定能生成这么高质量的候选框,导致检测器与候选框不匹配。归根结底,其实过高的u导致模型 “过拟合”。
而本文为了解决这个问题,提出了一种新的框架Cascade RCNN。主要利用图2(a)的观察:回归器的输出 IoU 几乎总是优于其输入IoU,因此以某个阈值训练的检测器可以为下一个阶段提供更好的候选框,因此下一个阶段可以使用更高的阈值。采用这种结构后,候选框的质量从一个阶段逐渐增加到下一个阶段,从而解决了那两个问题:① 样本不均衡,因为经过前一个阶段的回归后,候选框的质量得到提升,正样本的数量得到保证;② 在推理时使用相同的级联结构,也会产生一组质量逐渐提高的候选框,与高质量探测器得到很好的匹配,从而提高检测精度。
Cascade RCNN可以很方便地应用在各类基于RCNN的模型中,并且得到较为显著的提升,除了检测之外,也可以很方便地应用到实例分割中,比如Cascade Mask RCNN。不管是在各大数据集中,Cascade RCNN都能取得较好的结果,并且在各大比赛上也成为了主流模型。
相知
Challenge to High Quality Detection
作者这里再次提及到了高质量检测器【减少false positive】所面临的挑战:首先是分析了历史原因,之前的数据集对算法的检测性能要求比较宽松,在测试时只要预测框和GT之间的IoU阈值大于0.5即认为检测成功。而由于数据集和算法的发展,目前的数据集开始考虑更高质量的检测结果了,比如COCO和KITTI,其中COCO会综合考虑iou阈值u=[0.5 : 0.05 : 0.95]的mean AP。其次是这个任务本身比较难,虽然已经有一些方法在提升高质量假设框方面做出了努力(比如FPN),但上面也分析过了,高质量的假设框需要与高质量检测器互相匹配【文中称为paradox of high quality detection】。
Cascade RCNN
再次明确,cascade rcnn的目标是同时增加假设框与检测器的质量,从而达到高质量目标检测。
虽然Cascade RCNN可以应用各种网络结构中,但这里还是以最经典的
Faster RCNN作为基础模型进行叙述
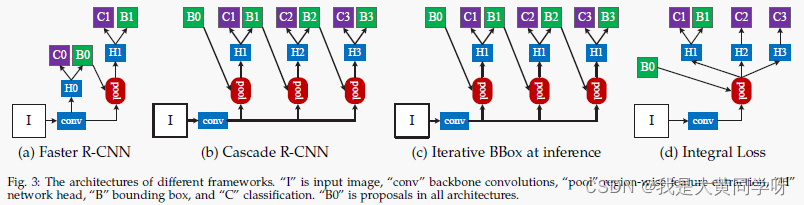
Cascade RCNN的网络如图(b)所示,相比于(a)的Faster RCNN,其主要区别在于引入了级联回归器,每个回归器 f t f_t ft都针对前一个回归器输出的检测框 b t b^t bt进行优化,逐渐提升候选框的质量。如下所示(一共包含T个回归器):

训练时,后一个回归器区分正/负样本的阈值
u会大于前一个回归器的uu={0.5, 0.6, 0.7}
下图展示了不同阶段的候选框质量分布(横轴表示候选框与GT之间的iou),可以看到如果不使用Cascade架构,RPN输出的u>0.7的候选框只有2.9%。而使用级联策略后,经过前一个阶段的回归器调整后,候选框的质量得到提升。即使后面回归器增加阈值u,这能够为其提供足够的正样本。

下图展示了不同阶段的候选框与GT之间的回归距离分布。可以看到每经过一次回归,候选框就更靠近GT一些,距离分布也在逐渐更接近中心【红色框表示经过阈值u剔除后的候选框】。

总结一下,这种级联结构对于检测器的训练有三个主要优点:① 减少了由于高阈值u导致的过拟合;② 不同的高阈值u都有一个对应的检测器;③ 随着u的增加,剔除了不少异常值,增加后阶段检测器的学习有效性。
Cascade R-CNN对于候选框和检测器质量的同步改进,使其能够解决paradox of high quality detection。在测试时应用相同的级联,依次提高候选框的质量,更高质量的检测器只需要对更高质量的候选框进行回归,并且对于这些候选框,它们是最优的。
与相似工作的异同
再回过头来看这张图,可以发现Cascade RCNN与( b )( c )两个工作存在一些相似之处,特别是( c ),只有检测头的区别,这里谈谈它们之间的异同。
图( c )展示了iterative BBox的网络结构,其主要在测试时对检测结果进行多次迭代。与Cascade RCNN主要区别在于:iterative BBox本质是一种后处理程序,其在训练时并没有级联设置,在测试用同一个检测器多次迭代。而Cascade是一种重采样机制,不同阶段处理不同分布的候选框,Cascade训练和测试都采用级联形式。

并且这种模型存在两个问题:① 根据某个阈值u训练得到检测器是次优的,比如图2中input iou>0.85时以u=0.5训练的检测器反而会出现退化;② 每次迭代后的分布会发生变化,而检测器却仍是同一个【检测器在训练时只针对一个分布训练】,这也是次优的。
图( c )展示了Intergral Loss的网络结构,其使用多分类器集成的方式:训练时构造不同的head进行分类任务,不同分类器采用不同的阈值u作为正负样本的评判标准,联合计算loss,如下所示。测试时使用多个分类器进行集成。

其与Cascade RCNN的区别和其主要缺点在于:① 无法处理高阈值下正负样本不均衡的问题【如图4所示】,不像cascade rcnn为不同阈值下的检测器调整了分布;② 在训练和测试时,高质量分类器都需要处理大量的低质量检测框,而不像Cascade RCNN中后阶段的高质量检测器只需要处理高质量的检测框分布。
实验也表明,Cascade RCNN比这两种方法提升了不少:

扩展到实例分割
Cascade RCNN架构很容易地就能扩展了实例分割任务中,用于Mask RCNN框架。
关于Mask RCNN,可以参考此博客Mask R-CNN-论文解读
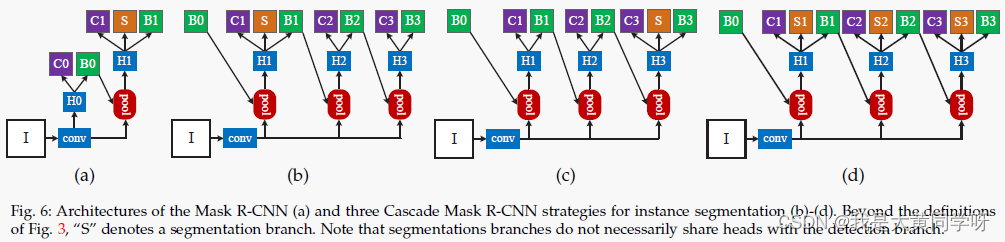
相比于目标检测,MaskRCNN多了一个分割分支,要将Cascade RCNN架构应用进去,面临两个问题:在哪里加入分割分支?以及加入多少分割分支?
因此作者设计了( b )( c )( d )三种结构,值得注意的是,在测试时无论是哪种结构,都只采用最后一个阶段输出的检测框包含的ROI进行分割【在(d)结构中,会送入三个分支进行预测然后ensemble】。实验表明,三种设计的性能都优于Mask RCNN。

其他实验只放出这张与其他SOTA方法的比较,其他消融实验见原论文:

回顾
Cascade RCNN这种策略其实在传统的机器学习与模式识别中就已经得到应用了,比如著名的VJ人脸检测器。但Cascade RCNN从实验现象开始挖掘,工作定位于“高质量的目标检测器”,通过实验分析,发现一些规律性的现象,因此采用级联的策略来解决的这个问题,不是单纯地套用结构。
这种级联的思想能够很容易地应用在各种two-stage工作中(RCNN系列),并且在各种数据集上也展现了提升。但这种策略并不一定适用于所有情况,比如在博主参加过的一个细胞实例分割的比赛中,发现应用cascade mask rcnn反而没有原始的mask rcnn好,个人猜测这是由于cascade rcnn本身是用于提升准确率的【降低false positive】,解决的是误检的问题,而细胞分割本身比较严重的问题是漏检,提升准确率的同时,必然会降低一部分召回率。大家在应用的时候,还是根据自己任务的实际情况为准,并进行调参,比如阈值u。
代码就不贴了,推荐大家使用MMdetection。
参考
[1] https://neg5bl8b86.feishu.cn/docs/doccnny3gq2MZZJISDUYRivmcjb
[2] https://www.bilibili.com/video/BV1a3411B71E?spm_id_from=333.999.0.0【视频资源】