摘要
实例级视频对象分割是视频编辑和压缩的一项重要技术。为了捕获时间的一致性,本文中,我们开发了MaskRNN,一个递归的神经网络方法,它在每个框架中融合了两个深网的输出,每个对象实例——一个提供一个掩码的二进制分割网络和一个提供一个边界框的定位网络。由于反复出现的构件和局部化构件,我们的方法能够利用视频数据的长期时态结构以及拒绝离群值。我们在三个具有挑战性的基准数据集、DAVIS-2016数据集、DAVIS-2017数据集和Segtrack v2数据集上验证了所提议的算法,并在所有这些数据集上实现了最先进的性能。
Introduction
在对象识别、视频编辑和视频压缩等领域,复杂场景的实例级视频对象分割是一个具有挑战性的问题。在最近发布的DAVIS dataset[39]中,从视频中分割多个对象实例的任务得到了相当多的关注。然而,就像经典的前背景分割,变形的形状,快速的运动,以及多个对象相互遮挡,对实例级视频对象分割提出了重大的挑战。
对于视频对象的分割,经典的技术(5、10、11、17、21、41、20、44、49)往往依赖于几何图形,并呈现出刚性场景。由于这些假设在实践中经常被违反,所以通常会观察到视觉上的明显的工件。根据时间和空间平滑的目标掩模估计,过去已经提出了基于图形模型的技术[22,2,14,45,47,46]。虽然图形模型能够在整个视频序列中实现有效的标签传播,但它们往往对参数敏感。
最近,基于深度学习的方法[7,26,23,6,25]已经应用于视频对象分割。该方向的早期工作是通过帧[7]来预测分割掩码帧。随后,对当前帧的预测,利用光流[23,26,25],语义细分[6],或掩模传播[26,25],从上一帧中得到额外的线索。重要的是,所有这些方法只处理单个对象的前背景分割,而不能直接应用于视频中多个对象的实例级分割。
与前面提到的方法相比,本文中我们开发了MaskRNN,一个处理视频中多个对象的实例级分割的框架。我们使用自底向上的方法,在合并结果之前,先跟踪和分割单个对象。为了捕获时间结构,我们的方法采用了一个循环的神经网络,而单个对象的分割则是基于对一个预测的边界框的二元分割掩码的预测。
我们在DAVIS-2016dataset[37]、DAVIS-2017 dataset[39]和Segtrack v2 dataset[30]中评估我们的方法。在这三个方面,我们观察到最先进的性能。
Related Work
近年来,视频对象分割被广泛研究[45、30、34、40、29、28、36、48、16、46、37、23、6、25]。接下来,我们将文献分为两类:(1)基于图形的方法和(2)深度学习方法。
基于时空图的视频对象分割:这类方法构建了一个三维时空图[45,30,16,28]来模拟视频中像素或超像素之间的帧间关系。然后沿着这个时空图传播一个像素分配到前景或背景的证据,以确定哪些像素被标记为前景,哪个像素对应于观察到的场景的背景。基于图形的方法能够接受不同程度的人类监督。例如,交互式视频对象分割方法允许用户在几个关键帧中对前景片段进行注释,通过将用户指定的掩码传播到整个视频(40、13、34、31、22),从而生成准确的结果。半监督的视频对象分割技术[4,16,45,22,46,33]只需要一个掩码作为视频的第一帧。此外,还存在不需要手动注释的无监督方法[9,28、50、36、35、12、48]。由于构建和探索三维时空图的计算代价很高,因此基于图的方法通常很慢,而基于图形的视频对象分割的运行时间往往远远不是实时的。
通过深度学习的视频对象分割:随着深网在语义细分上的成功[32,42],基于深度学习的视频对象分割方法[7,26,23,6,25]最近进行了深入的研究,并经常获得最先进的性能,超越了以图形为基础的方法。一般来说,使用的深网是预先训练的对象分割数据集。在半监督设置中,给出视频第一帧的地真掩码,然后对某一特定视频的第一个帧的给定ground truth进行网络参数的finetuned,以提高该网络的结果和特异性。此外,轮廓线索[7]和语义分割信息[7]可以合并到框架中。除了这些线索之外,相邻帧之间的光流是视频数据的另一个重要的关键信息。几种方法[26,23,25]利用相邻帧间的光流的大小。但是,这些方法并没有显式地对位置进行建模,这对于对象跟踪非常重要。此外,这些方法侧重于将前景与背景分离,不考虑视频序列中多个对象的实例级分割。
在Tab. 1中,我们提供了一个功能特征比较的视频对象分割技术和具有代表性的最先进的方法。我们注意到,通过使用递归神经网络,开发的方法是唯一将长期的时间信息考虑在内的方法。此外,所讨论的方法是除了分割掩码之外唯一估计边界框的方法,允许我们在被跟踪对象之前合并一个位置。
InstanceLevel Video Object Segmentation
接下来,我们提出了一种联合多目标视频分割技术,该技术通过将二进制分割与有效的目标跟踪相结合,实现了实例级对象分割。为了从时间的依赖中获益,我们使用了一个循环的神经网络组件,以在一个统一的框架中连接预测。接下来,我们首先给出了图1所示的已开发方法的概要,并详细描述了各个组件。
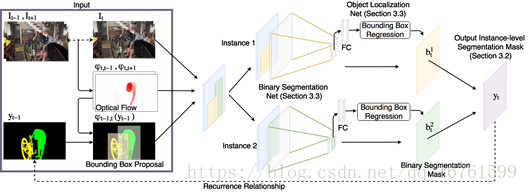
图1:提出的算法的说明。我们展示了一个带有两个对象的示例视频(左)。我们的方法预测每个对象使用2个深网(第3.3节)对每个对象进行二进制分割,每个对象分别执行二进制分割和对象定位。通过结合二进制分割掩码(第3.2节),获得输出实例级的分割掩码。
3.1 Overview
我们考虑一个由T帧It,t∈{1,...,T}组成的视频序列I = {I1,I2,...,IT}。在整个过程中,我们假设为第一帧I1给出感兴趣的N个对象实例的地面实况分割掩模。我们通过y W来指代第一帧的地面真实分段掩模,其中N是对象实例的数量,并且H和W是视频帧的高度和宽度。在多实例视频对象分割中,目标是预测作为与帧I2到IT对应的分割掩码的y2,...,yT∈{0,...,N} H×W。
所提出的方法如图1所示。受视频序列中帧的时间依赖性的驱动,我们将实例级语义视频分割的任务制定为递归神经网络,其中前一帧的预测影响预测当前帧。除了前一帧t -1的预测yt-1之外,我们的方法还考虑了前一帧和当前帧,即It-1和It。我们计算两幅图像的光流。然后,我们使用预测的光流(i)作为神经网络的输入特征,并(ii)扭曲先前的预测以与当前帧大致对齐。
然后将扭曲的预测,光流本身以及当前帧的外观用作N个深网的输入,N个对象中的每一个对应一个。每个深度网络由两部分组成,一个预测分段掩码的二进制分段网络和一个执行边界框回归的对象定位网络。后者用于缓解异常值。边界框回归和分割映射都被合并为二进制分割掩码bti∈[0,1] H×W,表示N个对象实例i∈{1,...,N}中的每一个的前景背景概率图。。随后使用argmax操作合并所有N个对象的二元语义分割。通过阈值计算当前帧的预测,即yt。请注意,我们仅在测试时结合二进制预测。
在下文中,我们首先详细描述我们的融合操作,然后讨论深度执行二进制分割和对象本地化。
3.2 Multiple instance level segmentation
预测第t帧的分段掩码yt可以被看作是多类预测问题,即,向视频中的每个像素分配标签,指示像素p是否表示对象实例(ytp = {1,...,N})或者像素是否被认为是背景(ytp = 0)。根据最近的实例级图像分割技术[18],我们将这种多类预测问题转换为多个二进制分割,每个对象实例一个。
假设二进制分割掩码bti∈[0,1] H×W的可用性为每个对象实例i∈{1,...,N}提供了一个像素应该被视为前景或背景的概率。 为了将二进制分段bti组合成一个最终预测yt,使得每个像素仅被分配给一个对象标签,通过为每个像素分配具有最大概率的类来实现。
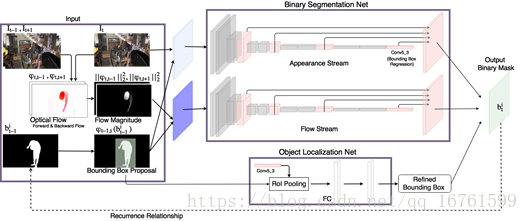
图2:第3.3节中描述的二进制对象分割网络和对象定位网络的图解。 二元分割网络是包括外观流和流动流的双流网络。外观流的输入是当前帧It和φt(bti-1)。 流体流的输入是流量大小和弯曲掩模φt(bti-1)。 对象本地化网络改进边界框建议以估计先前的位置。
为了计算二进制分段掩码bti,将外观流的输出和流动流线性组合,并且抛弃精炼边界框外的响应。
更具体地说,如果像素中的类别i的概率(由bti表示)在N个对象实例的N个概率图中最大,我们将类别标签i∈{1,...,N}分配给像素。 请注意,此操作与池操作类似,并允许反向传播。
3.3 Binary Segmentation
为了获得在融合步骤中采用的二进制分段bti∈[0,1] H×W,使用N个深网,对于N个所考虑的对象实例中的每一个。图2中示出了N个深网之一。它由两个部分组成,即二元分割网和对象定位网,这些将在下文中更详细地讨论。
二进制分割网络:每个二进制分割网络的目标是为其相应的对象实例i∈{1,...,N}预测前景背景掩模bti∈[0,1] H×W。为了实现这个任务,二进制分割网络被分成两个流,即外观流和流动流。表现流的输入是当前帧It与前一帧yt-1的变形预测的连接,表示为φt-1,t(yt-1)。变形函数φt-1,t(。)将基于来自帧It-1的光流场的输入变换为帧It。流体流的输入是从It到It-1和It到It + 1的流场的大小以及再一次对先前帧φt-1,t(yt-1)的扭曲预测的串联。两个流的体系结构是相同的,并遵循后续的描述。
网络体系结构受到[7]的启发,其中网络的底部遵循VGG-16网络的结构[43]。提取VGG-16网络的中间表示,紧接在最大共用层之前和ReLU层之后,通过双线性内插进行上采样并线性组合以形成与输入图像具有相同大小的单通道特征表示。通过线性组合两个表示,一个来自表观流,另一个来自流动流,并且通过对组合单信道特征响应采用S形函数,我们获得概率图,其指示概率bti∈[0,1 ] H×W是第t帧中的一个像素是前景的,即对应于第i个对象。外观流的网络架构如图2所示(右图)。在训练期间,我们使用[7]中建议的加权二进制交叉熵损失。
请注意,我们网络中的所有操作都是可区分的。因此,我们可以通过时间反向传播来对开发的网络进行端到端的培训。
对象本地化网络:对象本地化网络的使用受到跟踪方法的启发,该方法通过假设对象不太可能在时间上相邻的帧之间急剧移动来调整预测。对象定位网络通过边界框回归计算当前帧中第i个对象的位置。首先,我们在扭曲的面具φt(bti-1)上找到边界框建议。类似于Fast-RCNN [15]中的边界框回归,在边界框提议作为感兴趣区域的情况下,我们在分割网络的外观流中使用conv5_3特征来执行漫游池,然后是两个完全连接的层。它们的输出用于回归边界框的位置。我们将读者引用到[15]以获取关于边界框回归的更多细节。
给定边界框,如果像素被分割网预测为前景,并且如果其位于与定位网的预测相比放大1.25倍的边界框内,则将像素分类为前景。然后使用估计的边界框来限制分割以避免远离对象的异常值。
3.4 Training and Finetuning
在前面的章节中概述并在图1中示出的我们的框架可以通过给定训练序列的时间反向传播来端对端地进行训练。请注意,由于连接视频序列的多个帧的递归关系,所以使用了通过时间的反向传播。 为了进一步提高预测性能,我们遵循协议[39]进行视频对象分割的半监督设置,并使用为第一帧提供的地面实况分割掩模来微调我们的网络。具体而言,我们根据给定的基本事实进一步优化二元分割网络和本地化网络。 请注意,由于在监督设置中仅提供了单个地面实况框架,因此无法调整整个架构。
ImplementationDetails
在下文中,我们将描述我们方法的实施细节以及培训数据。我们还提供了有关我们实验设置中的离线培训和在线培训的详细信息。
训练数据:我们使用DAVIS数据集的训练集对通用对象分割的外观网络进行预训练。DAVIS-2016数据集[37]包含30个培训视频和20个测试视频,DAVIS-2017数据集[39]包含60个培训视频和30个测试视频。请注意,DAVIS-2016数据集的注释每个视频只包含一个对象。对于DAVIS-2016和DAVIS-2017数据集的公平评估,对象分割网和本地化网分别在每个数据集的训练集上进行训练。在测试过程中,由于我们假设第一帧的地面实况分段掩模(即y * 1)可用,因此网络在第一帧的给定地面实况上在线进一步微调。
离线训练:在离线训练期间,我们首先对静态图像上的网络进行优化。我们发现本地随机扰动地面实况分割蒙版yt * -1是非常有用的,可以模拟最后一帧的不完美预测。随机扰动包括扩张,变形,调整大小,旋转和平移。在对单帧二元分割网和目标定位网进行训练后,我们进一步通过长期优化分割网表3:DAVIS数据集验证集的定量评估[37]。评价指标是IoU测量J,边界精度F和时间稳定性T.在[37]之后,我们还报告了J和F测量结果随时间推移的回忆和性能衰退。
考虑信息,即使用递归关系进行训练。由于GPU强加的内存限制,我们一次考虑7帧。
在离线训练期间,所有网络都使用Adam求解器对10个时期进行了优化[27],训练期间的训练速率从10-5开始逐渐衰减。请注意,我们使用预先训练的flowNet2.0 [19]进行光流计算。在训练过程中,我们通过随机调整大小,旋转,裁剪和左右翻转图像和蒙版来应用数据增强。
在线微调:在视频对象分割的半监督设置中,第一帧的地面实况分段掩模可用。对象分割网和定位网在测试视频序列的第一帧进一步细化。我们将学习率设置为10-5。我们训练网络200次迭代,随着时间的推移,学习速率逐渐衰减。为了丰富训练数据的变化,对于在线微调,应用与离线训练相同的数据增强技术,即随机调整大小,旋转,裁剪和翻转图像。请注意,在线微调期间不使用RNN,因为只有一帧训练数据可用。