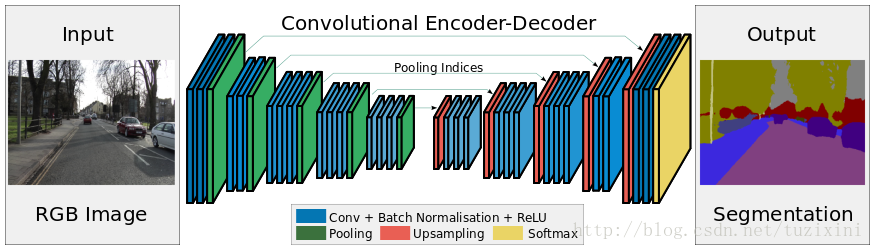
max-pooling indics:在SegNet中,深度编码器 - 解码器网络被联合训练用于监督学习任务。Segnet移除了全连接层,这样可以使其比其他许多近来的结构(FCN,DeconvNet,ParseNet和Decoupled)显著的小并且训练起来更容易。SegNet的关键部件是解码器网络,每个解码器对应于一个编码器。其中,解码器使用从相应的编码器得到的max-pooling indices,来进行输入特征图的非线性upsampling。这个想法来自用于无监督功能学习的架构设计。在解码网络中重用max-pooling indices有多个实践好处:
1)它改进了边界划分;
2)减少了实现端到端训练的参数数量;
3)这种upsampling的形式可以仅需要少量的修改而合并到任何编码-解码形式的架构。
Deconvolution:网络中的Upsampling,2x2的输入,变成4x4的图,但是除了被记住位置的Pooling indices,其他位置的权值为0,因为数据已经被pooling走了。因此,SegNet使用的反卷积在这里用于填充缺失的内容,因此这里的反卷积与卷积是一模一样的,在图1中跟随Upsampling层后面的是也是卷积层。
网络结构:编码器部分使用的是VGG16的前13层卷积网络,可以尝试使用Imagenet上的预训练。我们还可以丢弃完全连接的层,有利于在最深的编码器输出处保留较高分辨率的特征图。与其他最近的架构FCN和DeconvNet相比,这也减少了SegNet编码器网络中的参数数量。
每个编码器层具有对应的解码器层,因此解码器网络具有13层。
最终解码器输出被馈送到多级soft-max分类器以独立地为每个像素产生类概率。
注意,最后一个解码器产生一个多通道的特征图,而不是3通道的(RGB)。然后输入到一个softmax分类器。这个soft-max独立地分类每个像素,soft-max分类器的输出是K通道图像的概率,其中K是类的数量.预测的分割对应于在每个像素处具有最大概率的类.