lxml库 介绍
lxml是一个使用python编写的库,处理XML非常方便,另外还支持XPath,(上篇博客的XPath派上用处了XPath 基础入门)
lxml库 使用
没有lxml库的直接pip安装即可,导入lxml包出错则说明没安装
from lxml import etree
基本方法
lxml.HTML(text):将text中的文本转换为html网页代码
- text:需要转换的文本
lxml.tostring(html):将html代码转换为文本text
- html:需要转换的html代码
html.xpath(xp):用XPath表达式对html代码进行匹配
- html:源网页代码
- xp:用于匹配的XPath表达式
In:
from lxml import etree
text = '''
<div>
<ul>
<a href="aaa.html">i'am aaa</a>
<a href="bbb.html">i'am bbb</a>
<a href="ccc.html">i'am ccc</a>
</ul>
<ul>
<a href="111.html">i'am 111</a>
<a href="222.html">i'am 222</a>
<a href="333.html">i'am 333</a>
</ul>
</div>
'''
html = etree.HTML(text)
result = etree.tostring(html)
print(result)
Out:

XPath表达式
获取所有标签<a>
result = html.xpath('//a') # xpath返回的结果为列表
print(result)
print(len(result))
print(type(result))
print(type(result[0]))

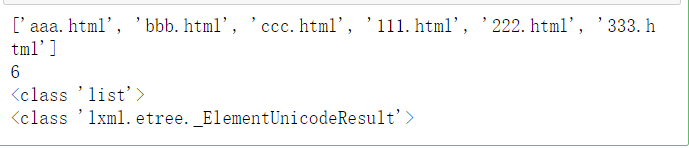
获取标签<a>的所有href
result = html.xpath('//a/@href')
print(result)
print(len(result))
print(type(result))
print(type(result[0]))
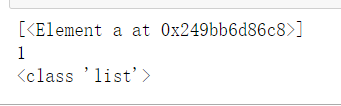
获取标签<a>下属性href值为111.html
result = html.xpath('//a[@href="111.html"]')
print(result)
print(len(result))
print(type(result))
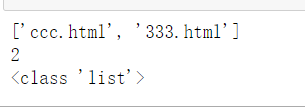
获取最后一个标签<a>的属性href值
result = html.xpath('//a[last()]/@href')
print(result)
print(len(result))
print(type(result))
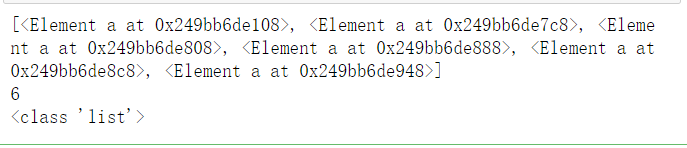
获取标签<ul>下标签<a>
result = html.xpath('//ul/a')
result=html.xpath('//ul//a')
#两者均可
print(result)
print(len(result))
print(type(result))
Element对象
可以发现XPath表达式匹配出来的每个标签都是一个Element类型,Element类型是一种灵活的容器对象,用于在内存中存储结构化数据。每个element对象都具有四个属性:
- tag:str类型,用于识别该元素表示拿种数据
- attrib:dic类型,表示附有的属性
- text:str类型,表示element对象的内容
- tail:str类型,表示element闭合之后的尾迹

print(result[0].tag)
print(result[0].text)
print(result[0].tail)
print(result[0].attrib)

