爬虫原理详解
虽说不同的爬虫原理并不相同,但这些原理中还是会存在许多的共同之处;所以就以通用爬虫和聚焦爬虫讲解爬虫的实现原理
通用爬虫
- 获取初始的URL,初始URL地址可以由用户直接决定,也可以由用户指定的网页决定
- 根据初始URL爬虫页面,爬取相应网页后将网页存储到原始数据库中,并将已爬取的URL地址存放到一个URL列表中,用于去重和判断爬取的进程;在爬取过程中也会获得新的URL,
- 将获得的新URL放到URL队列中
- 从URL队列中读取新的URL中,并根据新的URL爬取网页,同时从新网页获取新的URL,并重复上诉爬取过程。
- 满足设定的停止条件后,停止爬取;若未设定停止条件,则会一直爬取到无法获取到新的URL地址为止。

聚焦爬虫
因为聚焦爬虫有目的性,所以其对于网络爬虫来说,要增加目标的定义和过滤机制。
- 定义爬取目标
- 获取初始URL
- 根据初始URL爬取页面并获得新URL
- 将新的URL过滤与爬取目标无关的链接;另外将已爬取的URL地址存放到URL列表,用于去重和判断爬取的进展
- 将过滤后的链接放到URL队列中
- 在URL队列中,根据搜索算法确定URL优先级,并确定下一步爬取的URL地址
- 从下一步要爬取的URL地址中,读取新的URL,然后从URL中爬取网页,并重复上述过程
- 满足系统中停止条件或者无法获取新URL时停止爬取

爬取策略
在爬虫爬取网页过程中,在待爬取URL队列中,先爬取那个URL,后爬取那个URL是由爬取策略决定的。
爬取策略主要有深度优先爬取策略、广度优先爬取策略、大站优先策略、反链策略、其他爬取策略等。下面用一个例子来讲诉各个爬行策略
如图,某个网站有1-6个网页,不同的爬取策略爬取顺序不同

- 深度优先爬取策略:爬取一个网页一直顺着该网页的下层依次深入,爬取完后返回上一层进行爬取。
- 图中网站按深度优先爬取策略的顺序可以是:1→4→5→2→6→3
- 广度优先爬取策略:爬取同一层次的网页,爬取完后再深入下一层次。
- 图中网站按广度优先爬取策略的顺序可以是:1→2→3→4→5→6
- 大站爬取策略:网站的网页数多的就称为大站,按照大站爬取策略会优先爬取大站中的网页URL地址
- 反链策略:反向链接数是该网页被其他网页指向的次数。按照反链策略,网站的反链数量越多,则该网站就会被邮箱爬取。
网页更新策略
- 许多网站的网页会经常更新,在我们爬取的时候也需要根据相应的策略对网站进行优先级排序,在优先记高的网页更新后将优先爬取。
- 常见的爬取策略有用户体验策略,历史数据策略,聚类分析策略
- 用户体验策略:在用户通过搜索引擎查询某个问题时,会出现许多网页,但大部分用户都只会用到排名前面的网页。所以,在通常情况下,爬虫服务器会优先更新排名靠前的网页,这种策略就是用户体验策略
- 历史数据策略:根据网站的历史数据来确定对网页更新的周期
- 聚类分析策略:将网页分成不同的类,每类大多属性相似,其更新频率也相似,聚类完成后,我们对每类中网页进行随机抽取一个样本,然后求出该样本的平均值,用其作为该类的更新频率
网页分析算法
在搜索引擎中,爬取到网页后会将网页存储到服务器的原始数据库中之后会对每个网页通过网页分析算法进行分析并排名,该排名即为用户检索时的排名
-
基于用户行为的网页分析算法
该算法里,会根据用户对网页的访问行为对网页进行评价,常见的是根据用户对网页的访问频率、访问时长、用户对网页的单机率等进行中和评价。 -
基于网络拓扑的网页分析算法
该算法通过网页的链接关系、结构关系等网页数据来对网页进行分析的,拓扑就是网络结构关系。该算法可以分为三种:基于网页粒度的分析算法,基于网页块粒度的分析算法,基于网站粒度的分析算法。- 基于网页粒度的分析算法:根据网页之间的链接关系对网页的权重进行分析并排名,常见的如谷歌的PageRank,HITS等。
- 基于网页块粒度的分析算法:根据网页之间连接关系进行计算,但分析规则有所不同。通常来说,一个网页会包含多个超链接,这些链接对网页的重要程度是有不同层次的;根据这些外部链接的层次进行分析、排名网页。
- 基于网站粒度的分析算法:我们不在具体的对每个网页进行排名,而是划分网站的层次或等级。对于基于网页粒度的算法来说,更加简单高效,同时精确度不如网页粒度。
-
基于网络内容的网页分析算法
该算法会依据网页的内容对网页进行相应的评价
身份识别
在爬取网页时,爬虫需先访问该网页,此时爬虫会告诉网页的站长其爬虫身份。网站管理者可以通过爬虫告知的身份信息度爬虫身份进行识别,我们称该过程为爬虫的身份识别过程。
爬虫在爬取网页时,会通过http请求中User Agent字段告知自己的爬虫身份。爬虫在爬取网页之前会根据该网页的Robots.txt来确定可爬取的范围。
实现爬虫
在这里先简单介绍一个简单爬虫工具gooseeker。
-
直接搜索下载并注册(一定要注册)gooseeker,傻瓜式安装后打开
-
在顶上搜索栏出输入想爬取的网站,此处以爬取2345天气网
http://tianqi.2345.com/today-57516.htm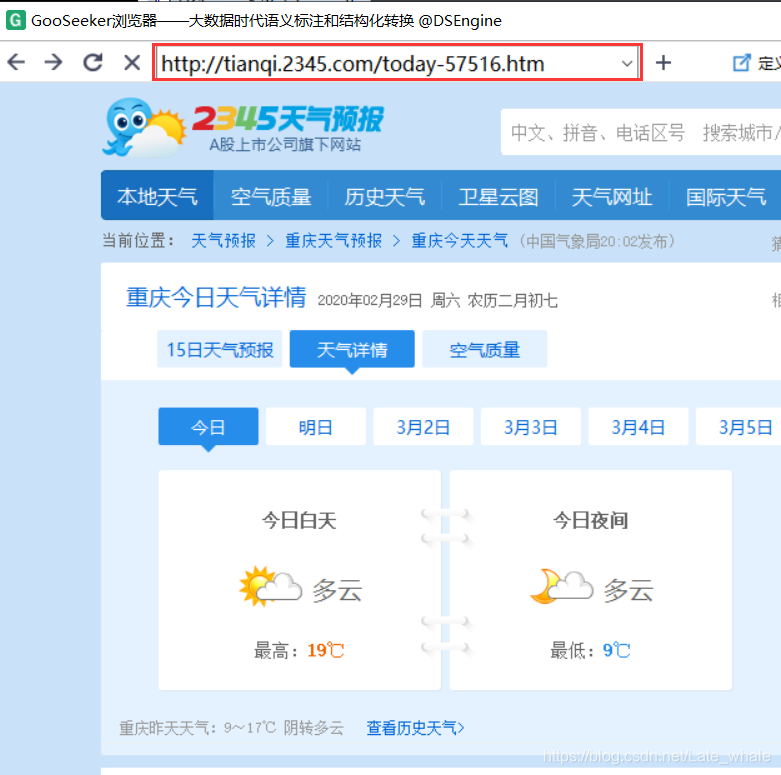
-
点击ms谋数台
-
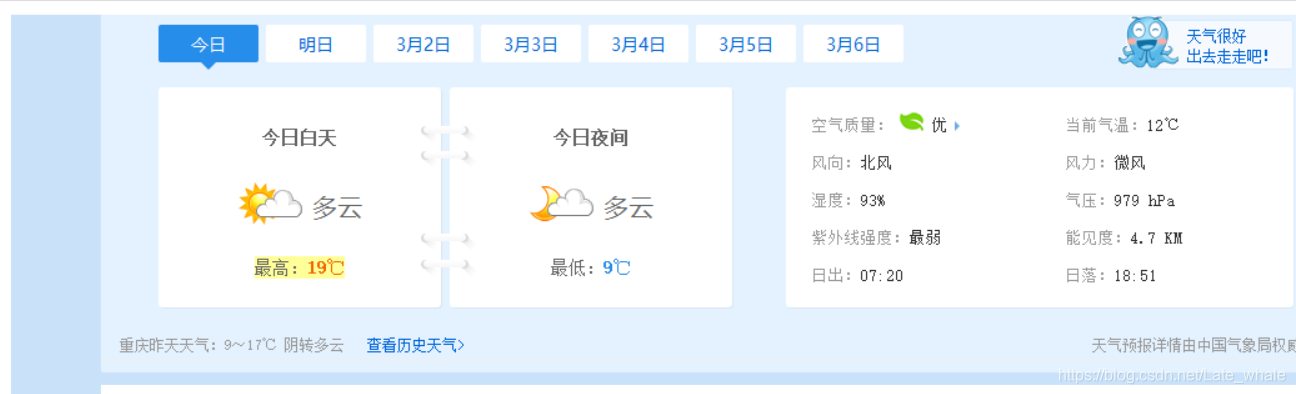
输入需要爬取的网址,后按回车,等待网页加载完毕

-
点击弹出工作台,如果工作台未关闭的就跳过该步
-
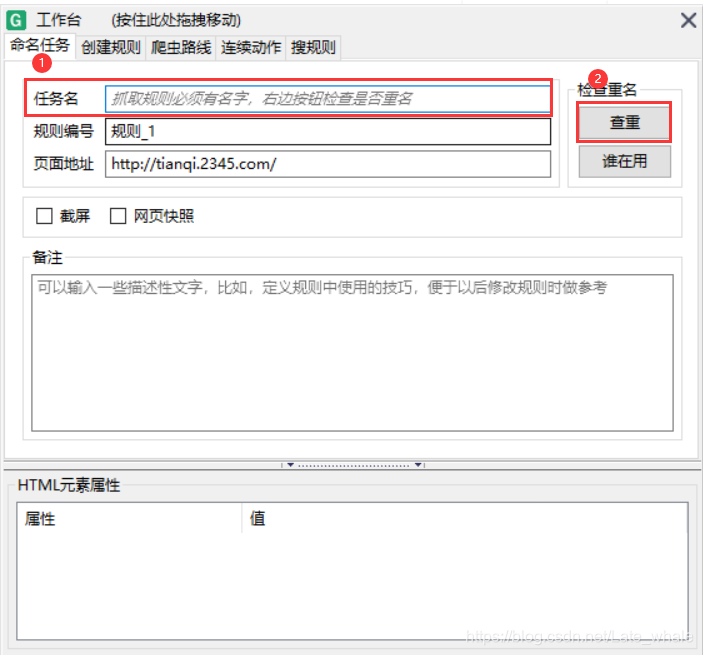
创建命令规则并查重,直到不重复为止。
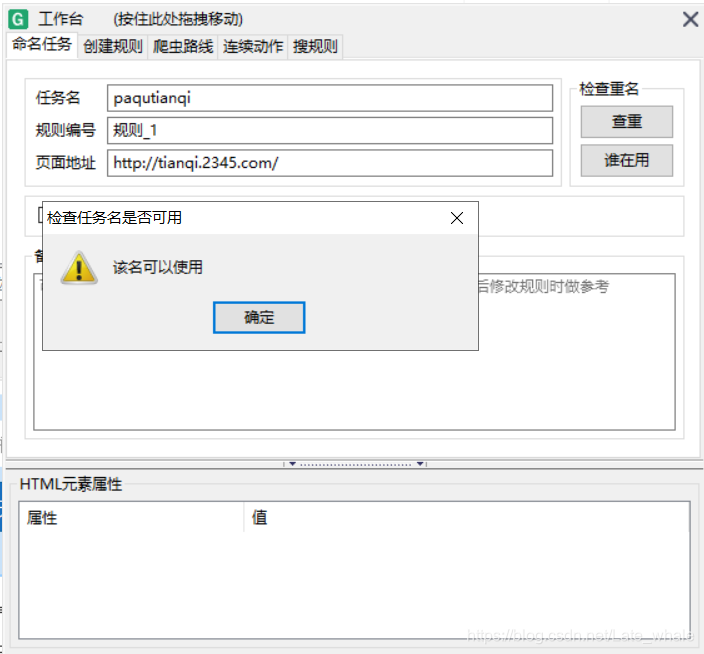
显示可用即可
-
创建规则
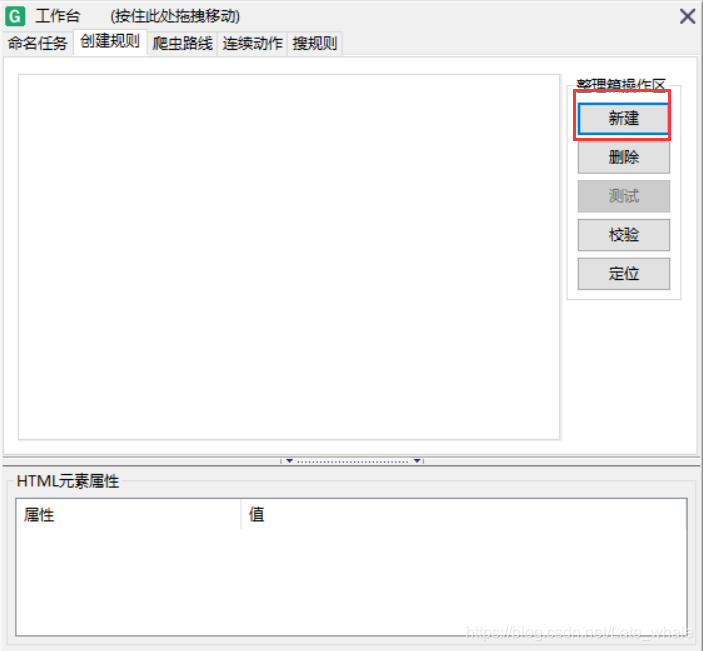
点击新建
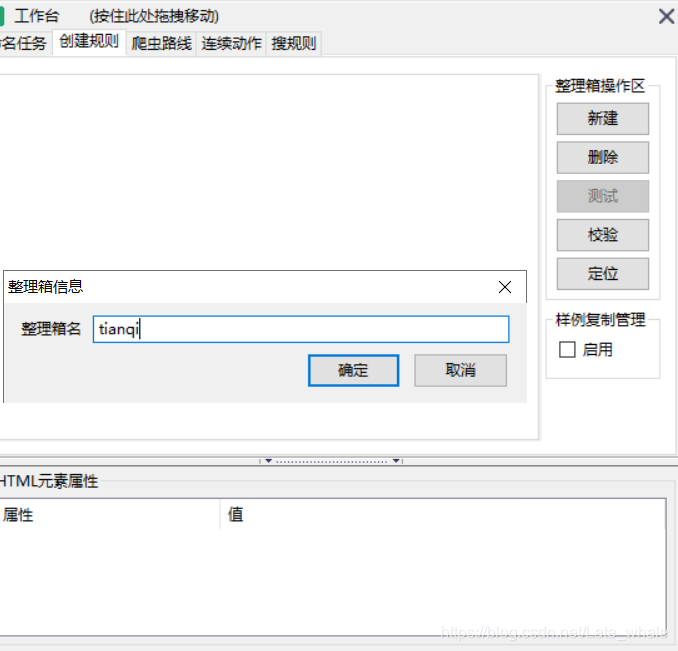
输入名字确定即可
创好之后如下
-
右键点击之前的名字→添加→包容,并命名你想爬取的内容,随后在之前添加好的那个上添加,其后
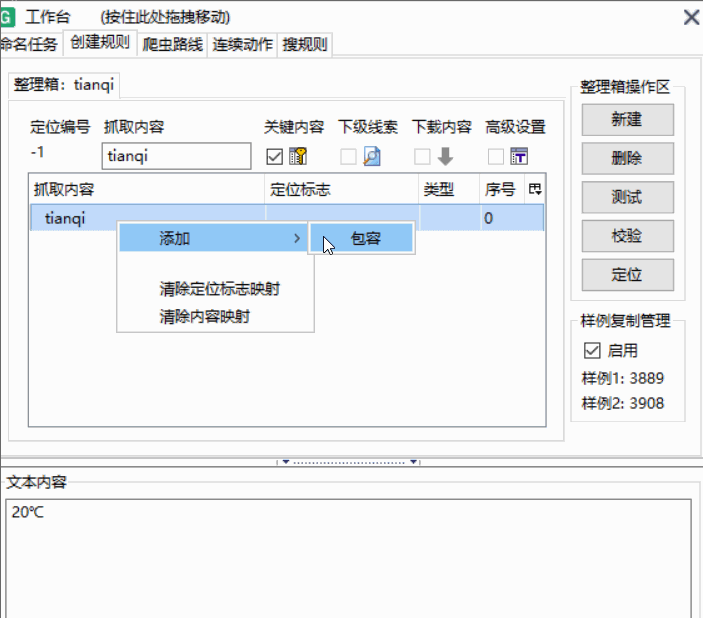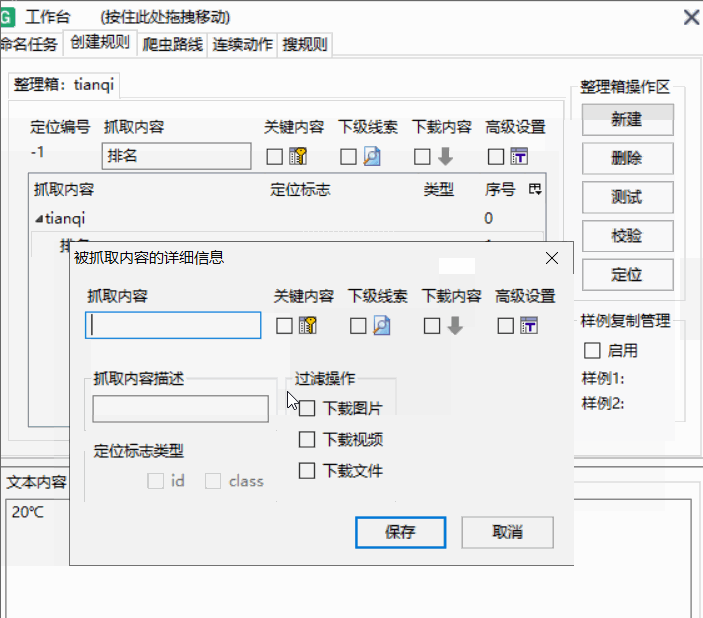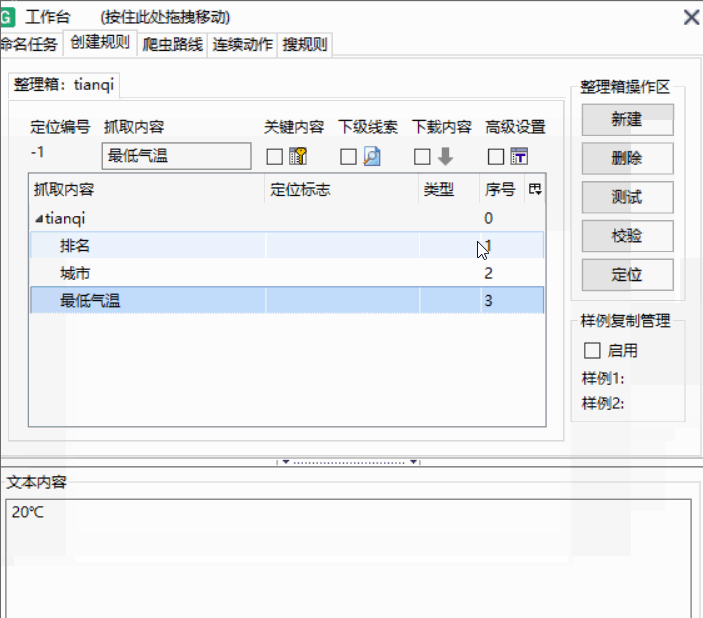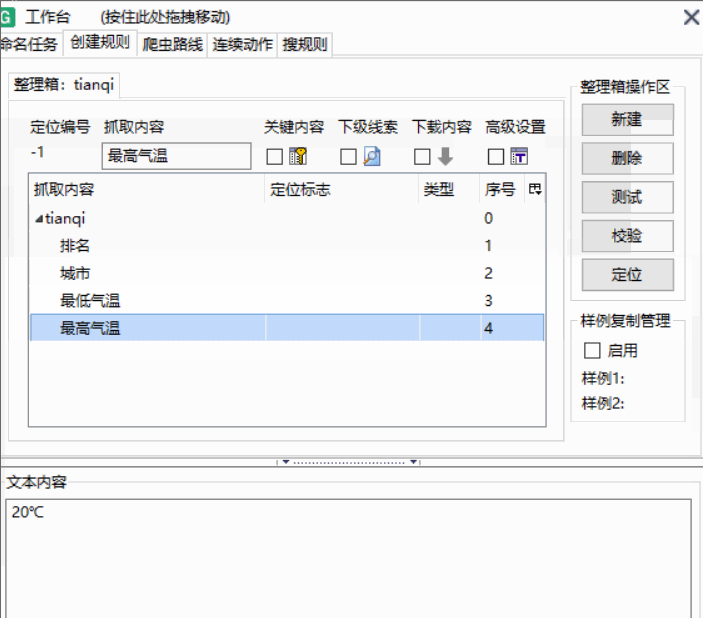
定义好后点击第一个并勾选上关键内容
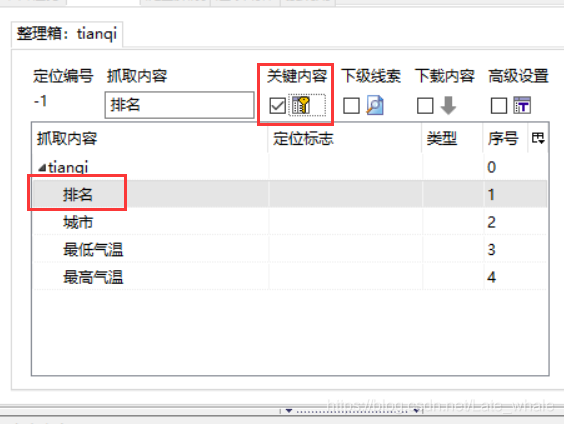
-
点击你想爬取的内容并在网页标签中找到text在谋数台中查看是否是需要的属性,是就在text处右键点击并内容映射,选择对应的名称标记即可
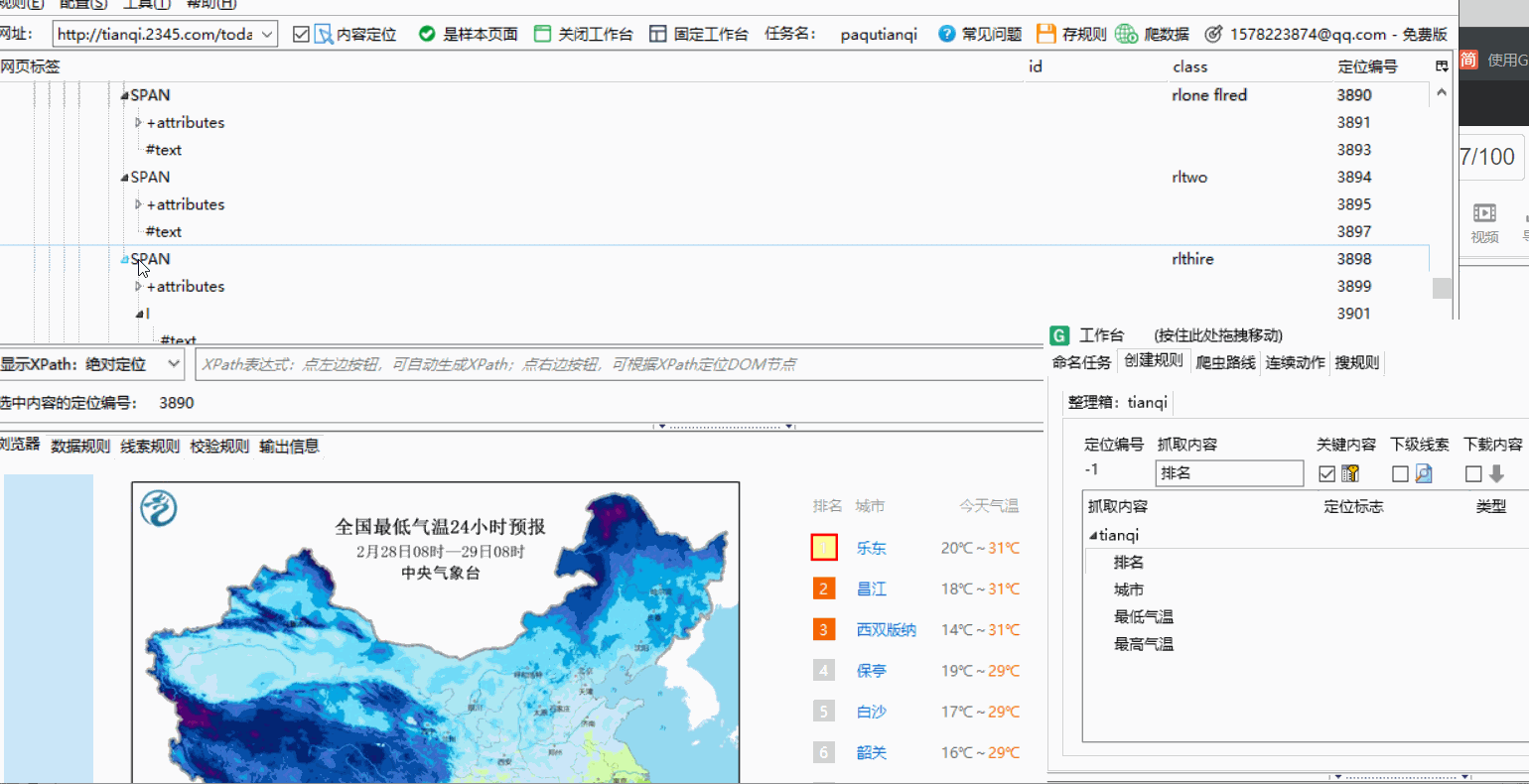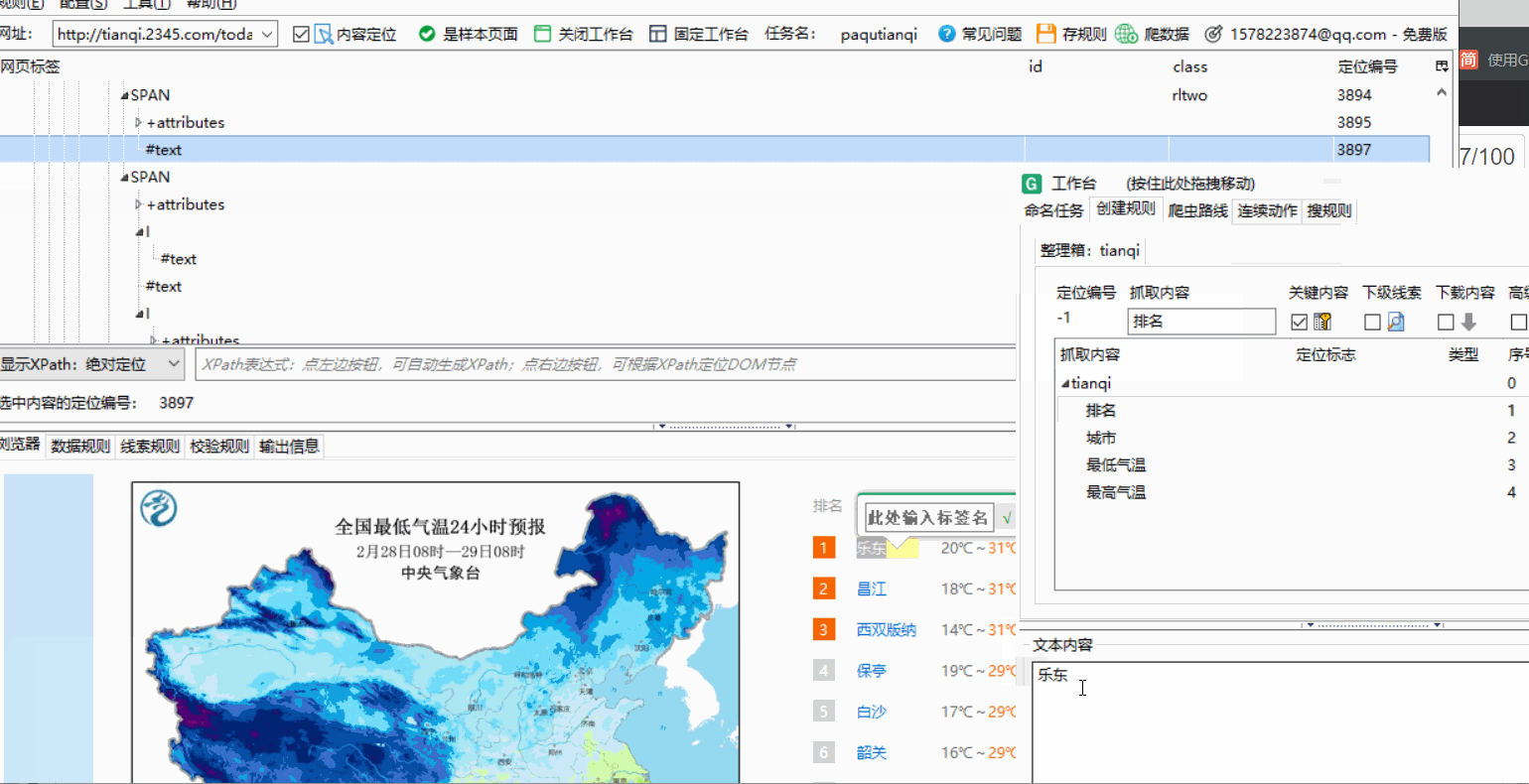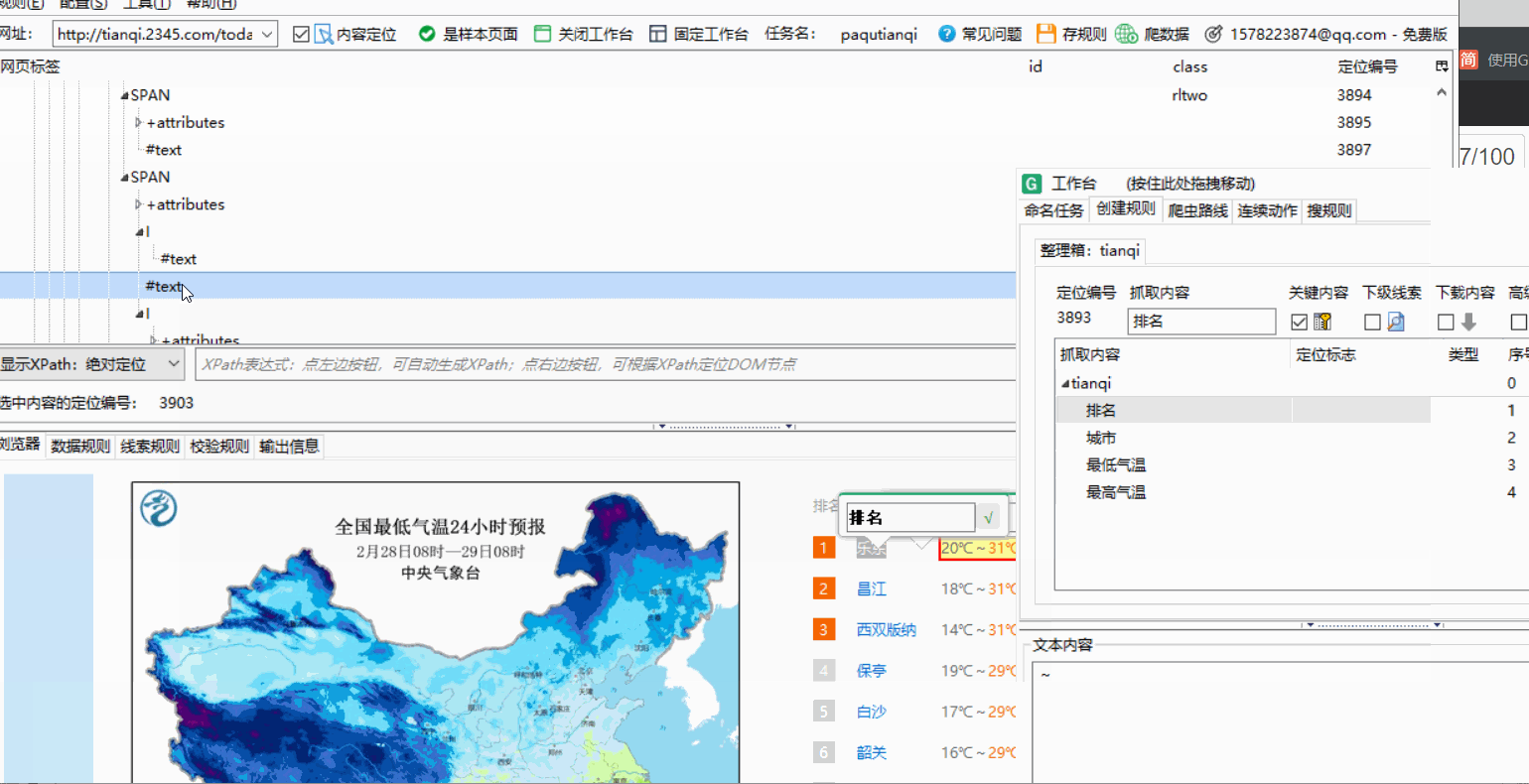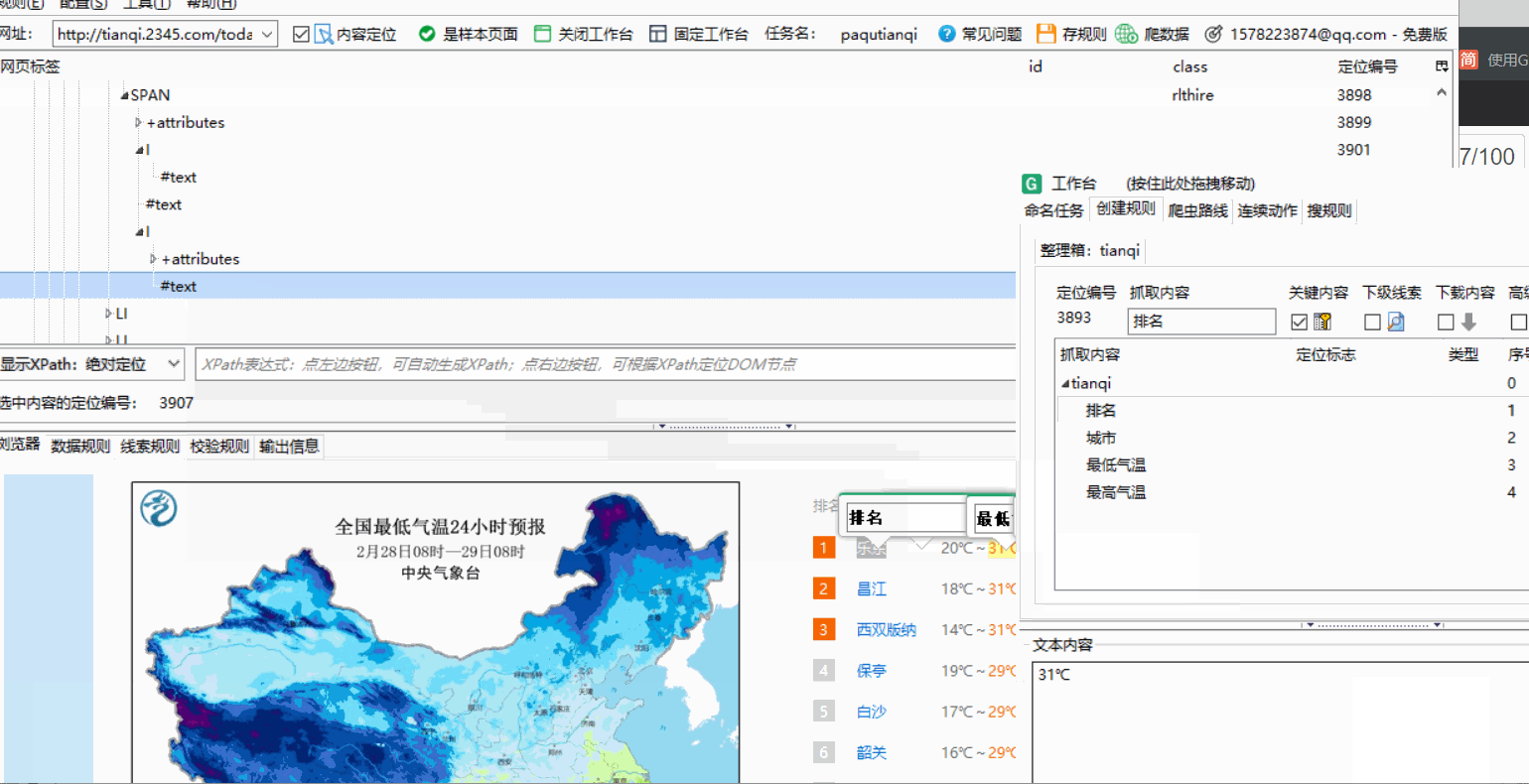
-
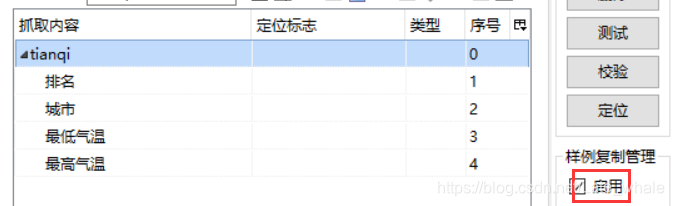
点击tianqi勾选启用,如果出现问题,就按照之前的步骤检查
-
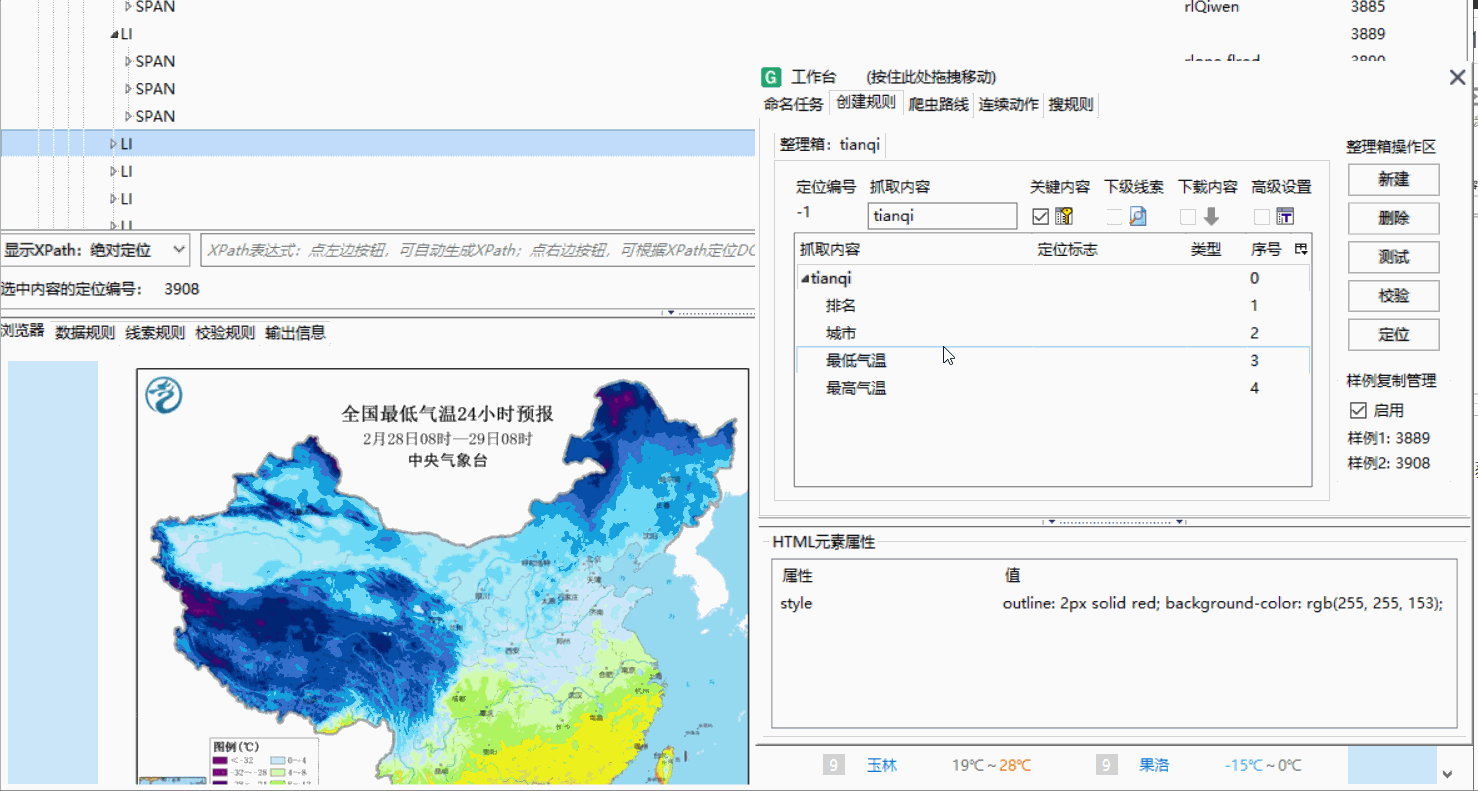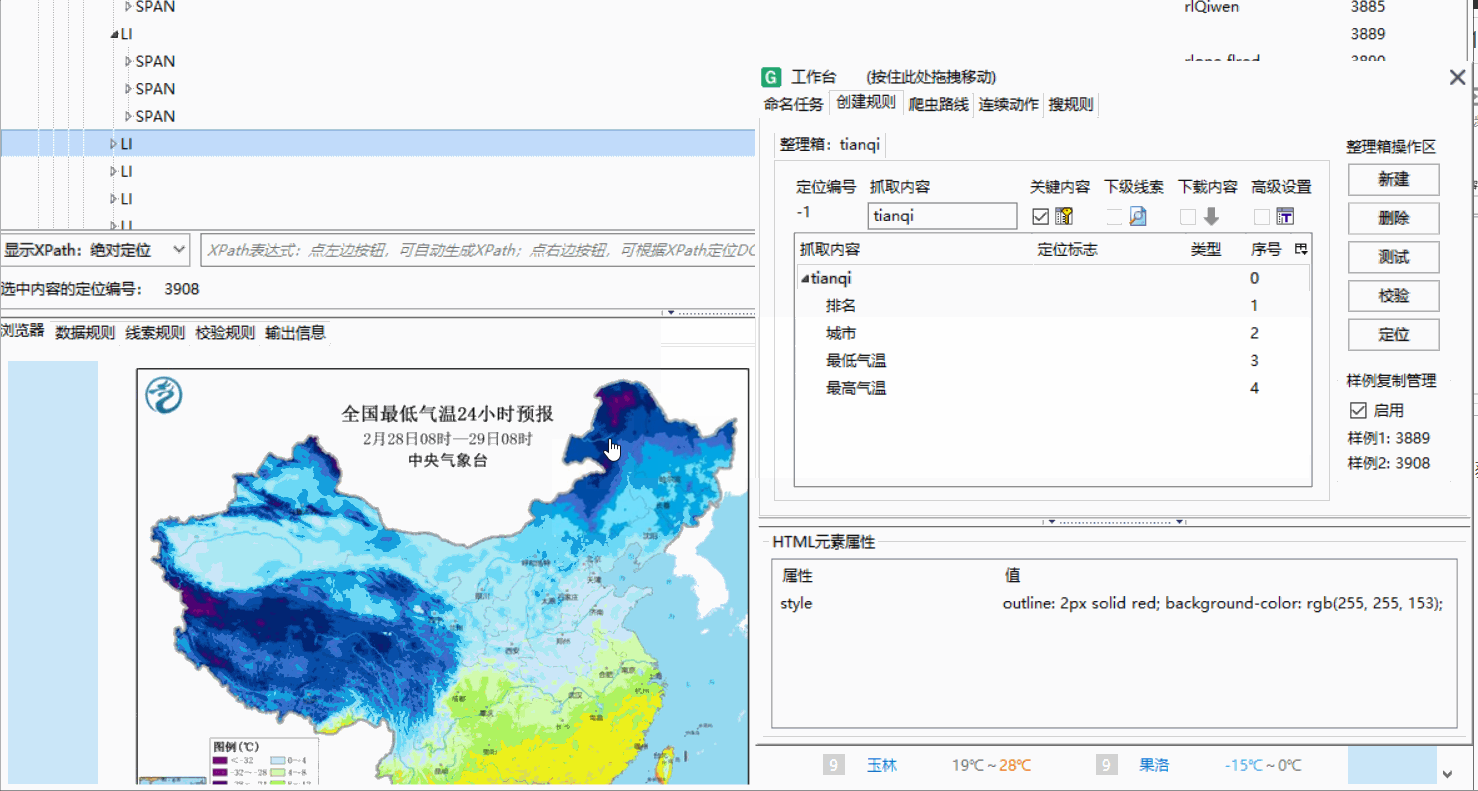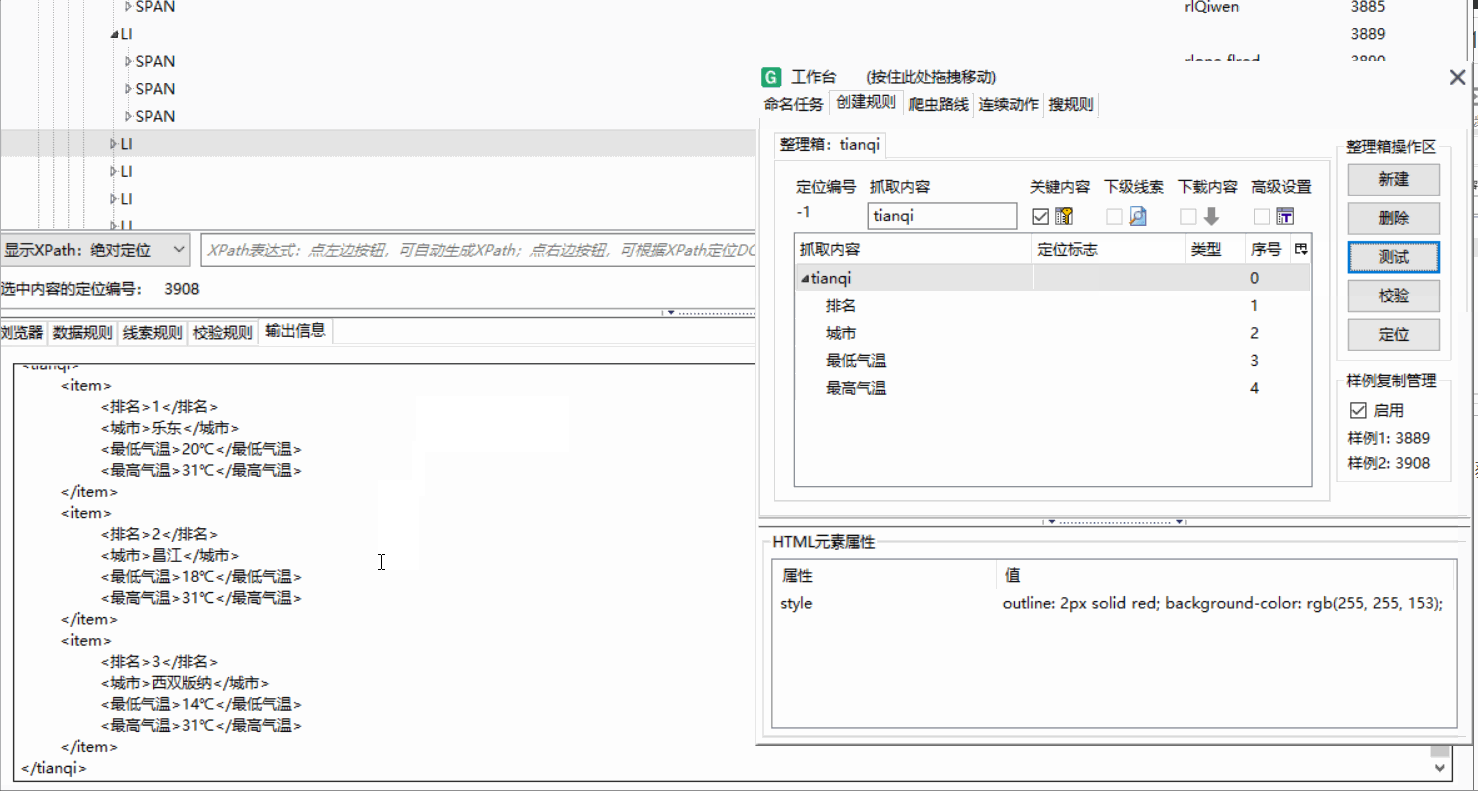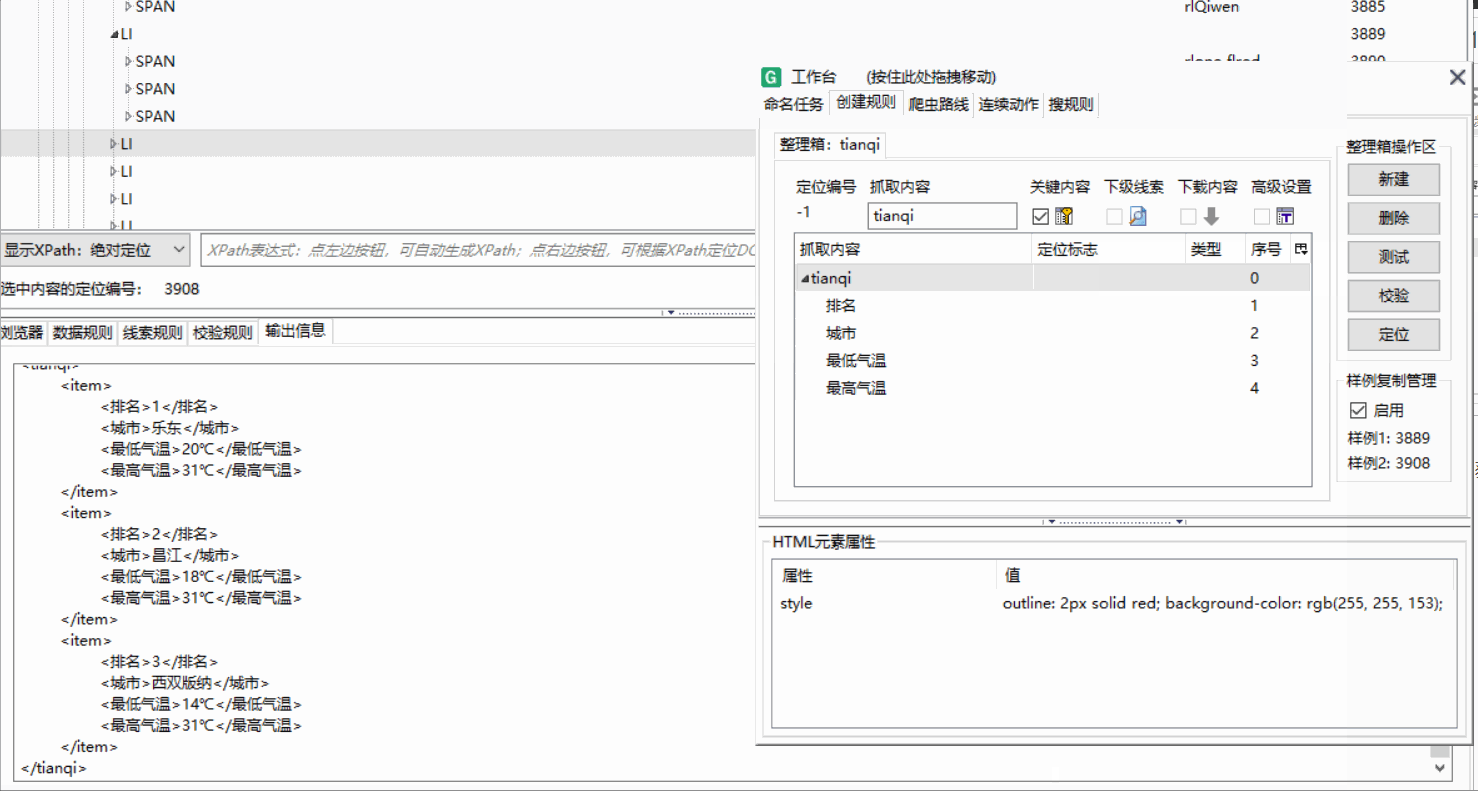
使用样例复制我们需要爬取的排行榜结构都是一样的,我们上一步只是完成了第一名数据的抓取,想要抓取更多的评论就需要进行样例复制。
找到包含整个数据的标签右键点击依次选择第一个第二个
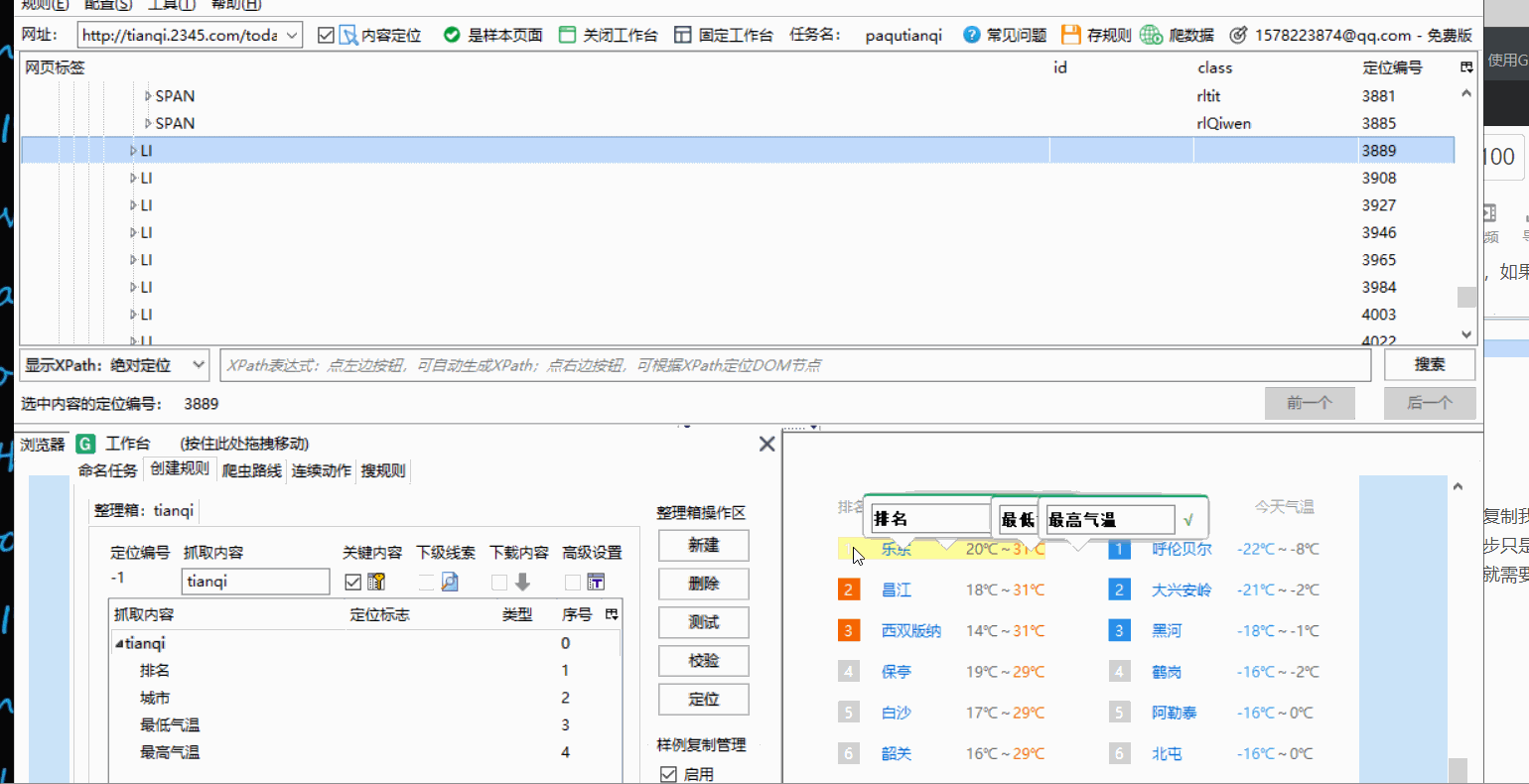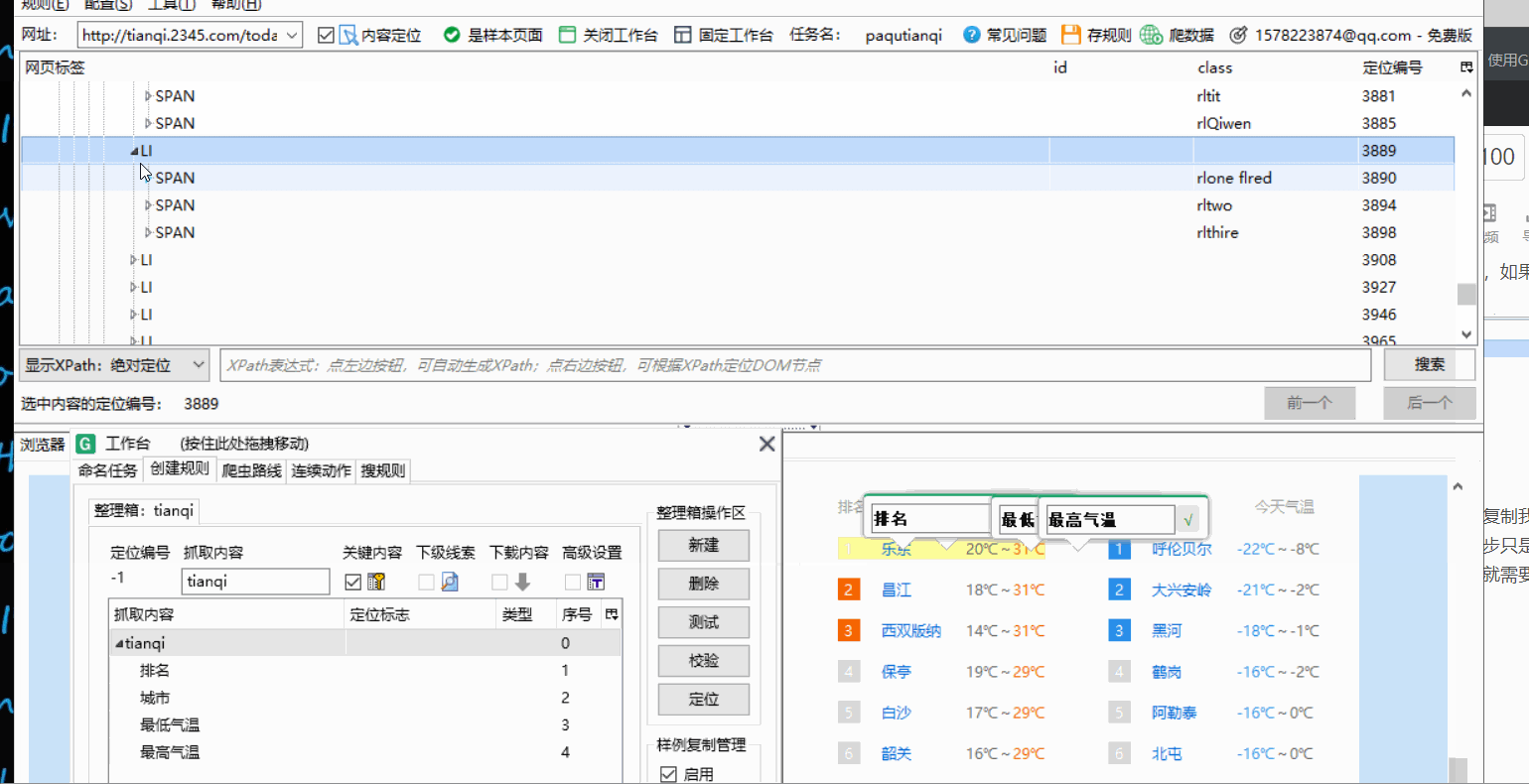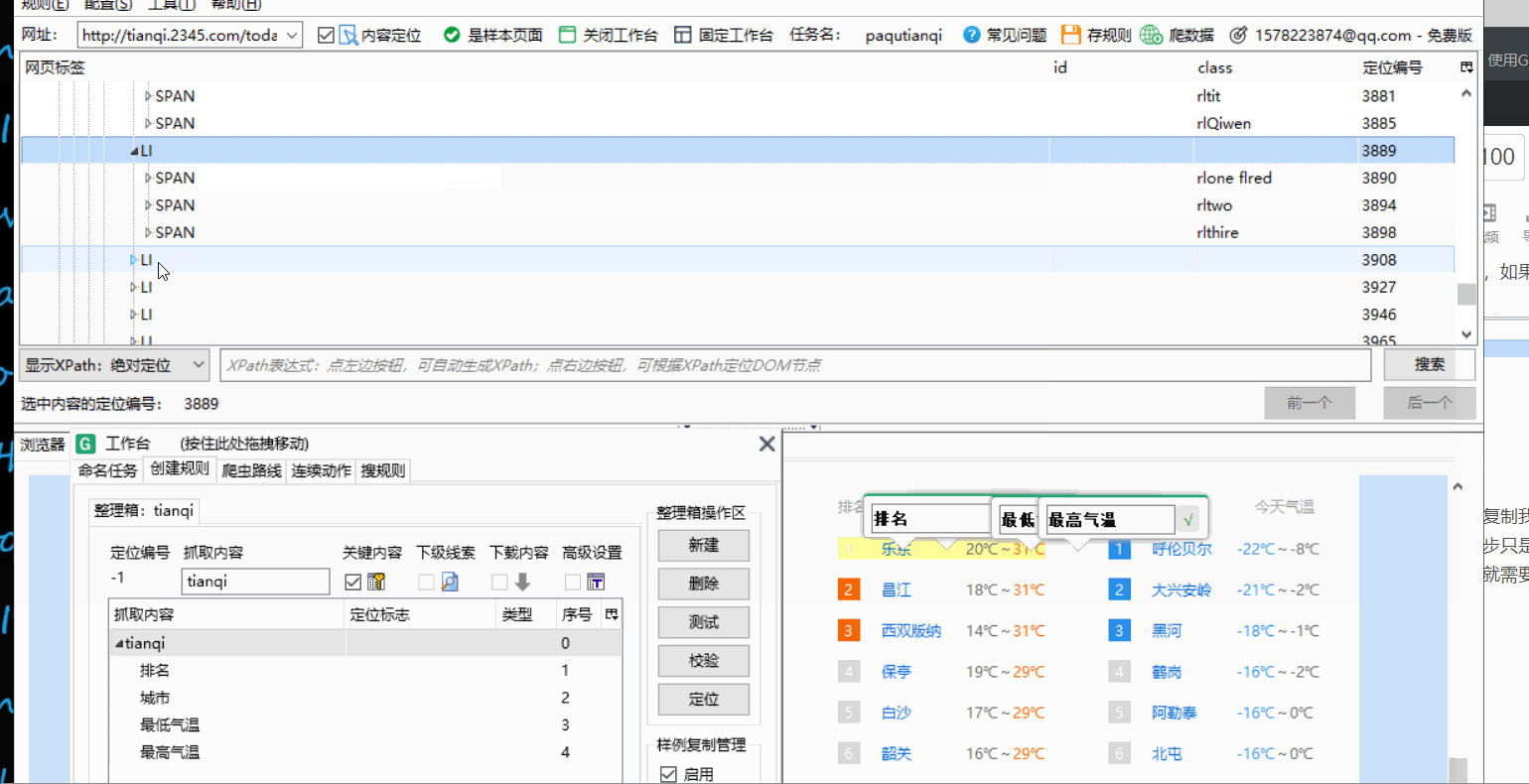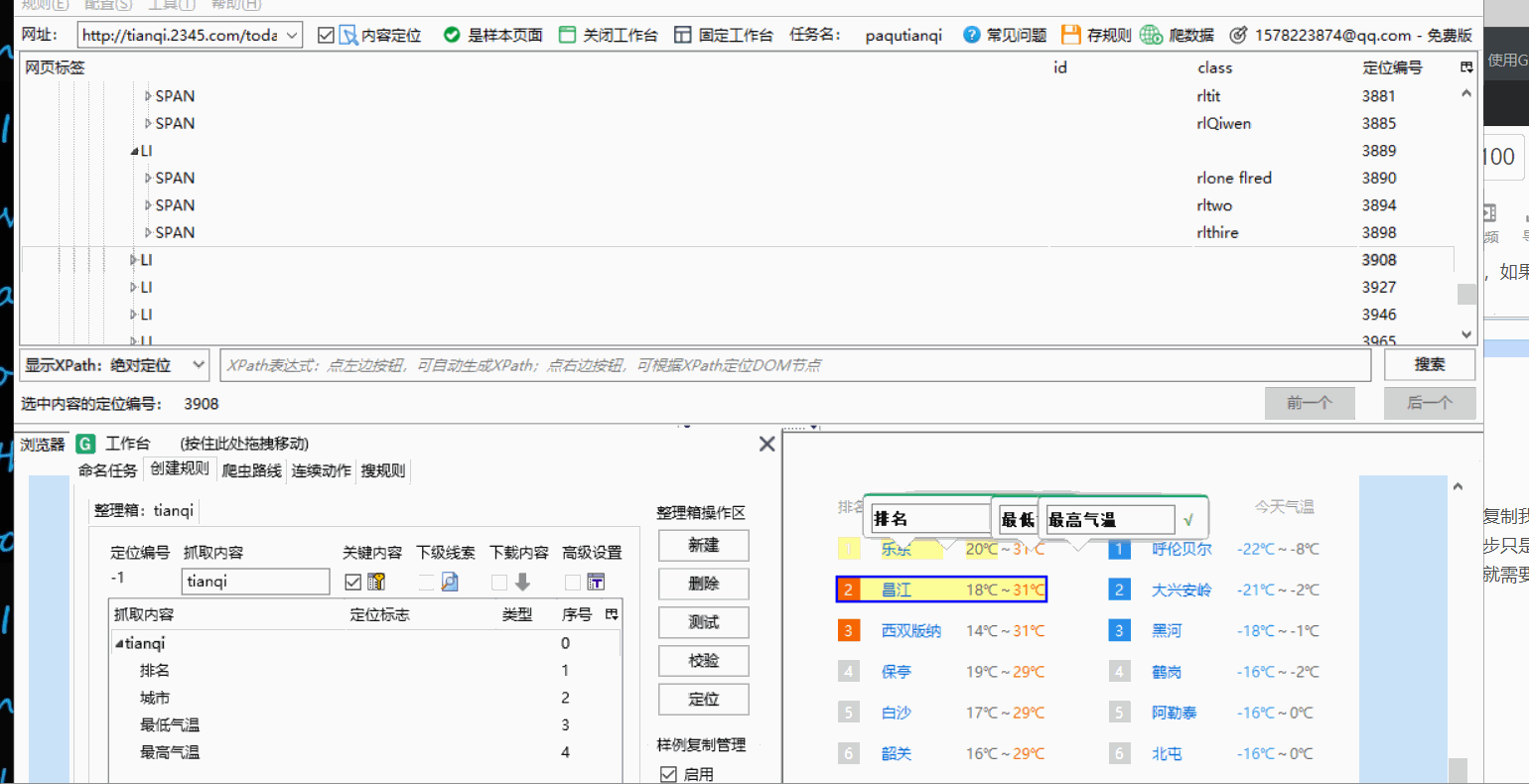
结果如图
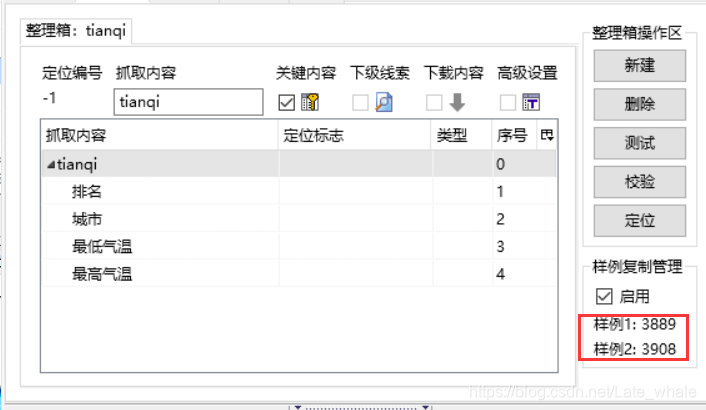
12. 点击测试,获取结果,