文章目录
Beautiful Soup4 简介
BeautifulSoup4和 lxml 一样是一套HTML/XML数据分析、清洗和获取工具,主要的功能也是如何解析和提取 HTML/XML 数据。
BeautifulSoup支持Python标准库中的HTML解析器,还支持一些第三方的解析器,如果我们不安装它,则 Python 会使用 Python默认的解析器。
Beautiful Soup自动将输入文档转换为Unicode编码,输出文档转换为utf-8编码。你不需要考虑编码方式,除非文档没有指定一个编码方式,这时,Beautiful Soup就不能自动识别编码方式了。然后,你仅仅需要说明一下原始编码方式就可以了。
Beautiful Soup4 解析器
Beautiful Soup4常用解析器及优缺点
| 解析器 | 用法 | 优点 | 缺点 |
|---|---|---|---|
| html.parser | BeautifulSoup(markup,“html.parser”) | python 内置库,速度较好,容错能力好 | 在python2.7.3或3.2.2前 容错差 |
| lxml HTML解析器 | BeautifulSoup(markup,“lxml”) | 速度快,容错能力好 | 依赖C |
| lxml XML解析器 | BeautifulSoup(markup,“xml”)或BeautifulSoup(markup,“lxml-xml”) | 速度非常快,唯一支持XML的解析器 | 依赖C |
| html5lib | BeautifulSoup(markup,“html5lib”) | 容错非常好,解析方式与浏览器相同 | 速度非常慢,依赖python |
现在看不懂也没关系,大概了解一下。
Beautiful Soup4 安装
安装最新版本
pip install beautifulsoup4
Beautiful Soup4 解析器安装
安装lxml解析器(建议安装)
pip install lxml
安装html5lib解析器
pip install html5lib
Beautiful Soup4 简单使用
演示文档(爱丽丝梦游仙境的一段内容)
html_doc = """
<html><head><title>The Dormouse's story</title></head>
<body>
<p class="title"><b>The Dormouse's story</b></p>
<p class="story">Once upon a time there were three little sisters; and their names were
<a href="http://example.com/elsie" class="sister" id="link1">Elsie</a>,
<a href="http://example.com/lacie" class="sister" id="link2">Lacie</a> and
<a href="http://example.com/tillie" class="sister" id="link3">Tillie</a>;
and they lived at the bottom of a well.</p>
<p class="story">...</p>
"""
用BeautifulSoup解析这段代码,能够得到一个BeautifulSoup的对象,并能按照标准的缩进格式的结构输出
In:
from bs4 import BeautifulSoup
html_doc = """
<html><head><title>The Dormouse's story</title></head>
<body>
<p class="title"><b>The Dormouse's story</b></p>
<p class="story">Once upon a time there were three little sisters; and their names were
<a href="http://example.com/elsie" class="sister" id="link1">Elsie</a>,
<a href="http://example.com/lacie" class="sister" id="link2">Lacie</a> and
<a href="http://example.com/tillie" class="sister" id="link3">Tillie</a>;
and they lived at the bottom of a well.</p>
<p class="story">...</p>
"""
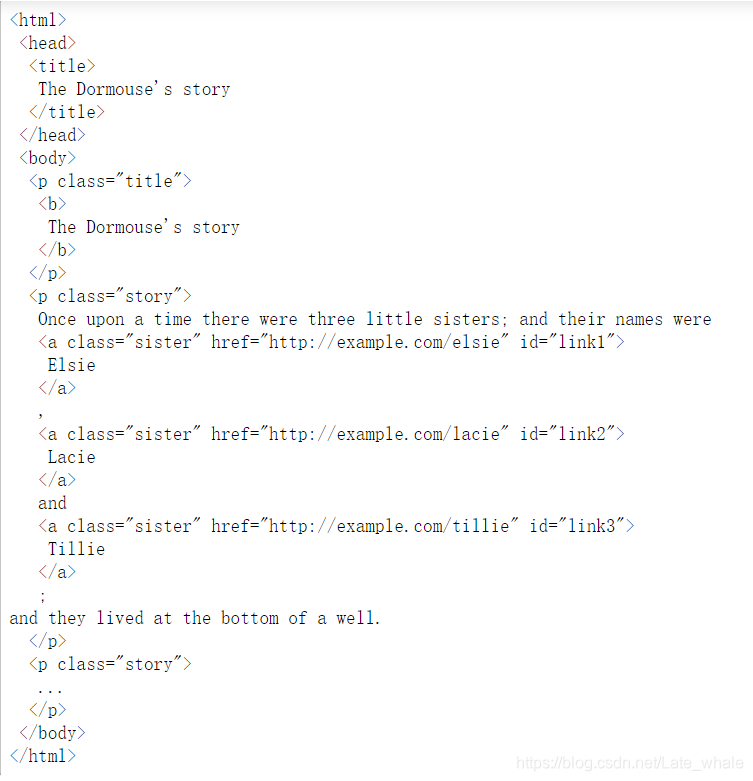
soup = BeautifulSoup(html_doc, 'html.parser')
print(soup.prettify())
Out:
获取第一个某标签的所有内容
print(soup.title)#获取标签title的所有内容
print(soup.p)#获取标签p的所有内容
print(soup.a)#获取标签a的所有内容
获取第一个某标签的name
print(soup.title.name)#获取标签title的name
print(soup.p.name)#获取标签p的name
print(soup.a.name)#获取标签a的name
获取第一个某标签的内容
print(soup.title.string)#获取标签title的内容
print(soup.p.string)#获取标签p的内容
print(soup.a.string)#获取标签a的内容
获取第一个某标签的name
print(soup.title.name)#获取标签title的name
print(soup.p.name)#获取标签p的name
print(soup.a.name)#获取标签a的name
获取第一个某标签的id值
print(soup.a['id'])#获取标签a的id值
获取所有的某标签的所有内容
print(soup.find_all('a'))#获取标签a的所有内容
按某个已知值进行查询
print(soup.find(id="link3"))#查询id=“link3”
获取文档中所有文字内容
print(soup.get_text())
from bs4 import BeautifulSoup
html_doc = """
<html><head><title>The Dormouse's story</title></head>
<body>
<p class="title"><b>The Dormouse's story</b></p>
<p class="story">Once upon a time there were three little sisters; and their names were
<a href="http://example.com/elsie" class="sister" id="link1">Elsie</a>,
<a href="http://example.com/lacie" class="sister" id="link2">Lacie</a> and
<a href="http://example.com/tillie" class="sister" id="link3">Tillie</a>;
and they lived at the bottom of a well.</p>
<p class="story">...</p>
"""
soup = BeautifulSoup(html_doc, 'html.parser')
# print(soup.prettify())
# print(soup.title)#获取标签title及其内容
# print(soup.p)#获取标签p及其内容
# print(soup.a)#获取标签a及其内容
# print(soup.title.name)#获取标签title的name
# print(soup.p.name)#获取标签p的name
# print(soup.a.name)#获取标签a的name
# print(soup.title.string)#获取标签title的内容
# print(soup.p.string)#获取标签p的内容
# print(soup.a.string)#获取标签a的内容
# print(soup.a['id'])#获取标签a的id值
# print(soup.find_all('a'))#获取标签a的所有内容
# print(soup.find(id="link3"))#查询id=“link3”
print(soup.get_text())
Beautiful Soup4 四大对象
BeautifulSoup4将复杂HTML文档转换成一个复杂的树形结构,每个节点都是Python对象,所有对象可以归纳为4种:
Tag
bs4中的tag也是XML或HTML中的tag,简单来说就是HTML中的标签,tag有很多属性:
name:
name:通过.name获取
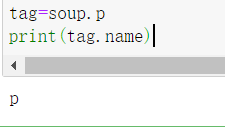
tag=soup.p
tag.name
如果改变了某个tag的name,会直接修改当前Beautiful Soup对象生成的HTML文档
tag=soup.p
tag.name='ppp' #会将soup对象中的第一个p标签修改
print(tag)

attrs:
一个tag可能会有很多属性,tag属性的操作方法与字典一致,可以增加、删除、修改等
tag=soup.a
print(tag['class']) #访问属性的方法与字典类似
print(tag.attrs) #返回该tag的所有属性
tag['class']='class_tag' #修改属性值
del tag['id'] #删除该tag的id属性
print(tag['class'])

多值属性:
HTML5中常见的多值属性是class(一个tag可以有多个class),另外的属性 rel , rev , accept-charset , headers , accesskey等也是多值属性
在Beautiful Soup中多值属性的返回类型是list:
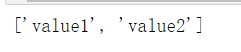
css_soup = BeautifulSoup('<p class="value1 value2"></p>')
print(css_soup.p['class'])
某些属性有多个值,但不是多值属性则Beautiful Soup会将这个属性作为字符串返回
css_soup = BeautifulSoup('<p id="value1 value2"></p>')
print(css_soup.p['id'])
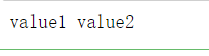
tag被转换成字符串时,多值属性会合并为一个值
css_soup = BeautifulSoup('<p class="value1 value2"></p>')
print(css_soup.p['class'])
print(css_soup.p)

如果是xml文档中的tag,则不会出现多值属性
css_soup = BeautifulSoup('<p class="value1 value2"></p>','xml')
print(css_soup.p['class'])
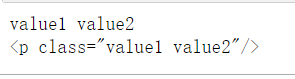
NavigableString
字符串常被包含在tag内.Beautiful Soup用 NavigableString 类来包装tag中的字符串:
通过tag.string来获取标签中的内容
css_soup = BeautifulSoup('''<p class="value1 value2">The Dormouse's story</p>''','xml')
tag=css_soup.p
print(tag.string)
print(type(tag.string))

NavigableString 字符串与Python中的Unicode字符串相同,可以通过 unicode() 方法直接将 NavigableString 对象转换成Unicode字符串
tag中包含的字符串不能编辑,但是可以用 replace_with() 方法来替换成其它的字符串,:
css_soup = BeautifulSoup('''<p class="value1 value2">The Dormouse's story</p>''','xml')
tag=css_soup.p
tag.string.replace_with("hello bs4")
print(tag.string)
print(type(tag.string))

BeautifulSoup
BeautifulSoup 对象表示的是一个文档的全部内容.大部分时候,可以把它当作 Tag 对象,他具有的属性为
名称:
通过.name获取BeautifulSoup的名称
类型:
通过type()获取BeautifulSoup的类型
属性:
通过.attrs获取BeautifulSoup的属性
soup = BeautifulSoup('''<p class="value1 value2">The Dormouse's story</p>''','xml')
print(soup.name)
print(type(soup))
print(soup.attrs)

Comment
Comment 对象是一种特殊的 NavigableString 对象,它会将标签中的注释输出,但不包括注释符。
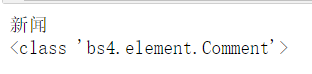
html_a='''<a class="mnav" href="http://news.baidu.com" name="tj_trnews"><!--新闻--></a>'''
soup=BeautifulSoup(html_a)
comment=soup.a.string
print(comment)
print(type(comment))